新视角理解大语言模型
谈到大语言模型,通常想到的是预训练、有监督微调、RLHF、以及思维链提升。然而,这些都是站在LLMs的技术细节理解。与之不同,本文站在基础模型的角度理解大语言模型,也可以理解为站在应用或提升其特定能力的角度。如图1所示,大语言模型可扮演的角色。
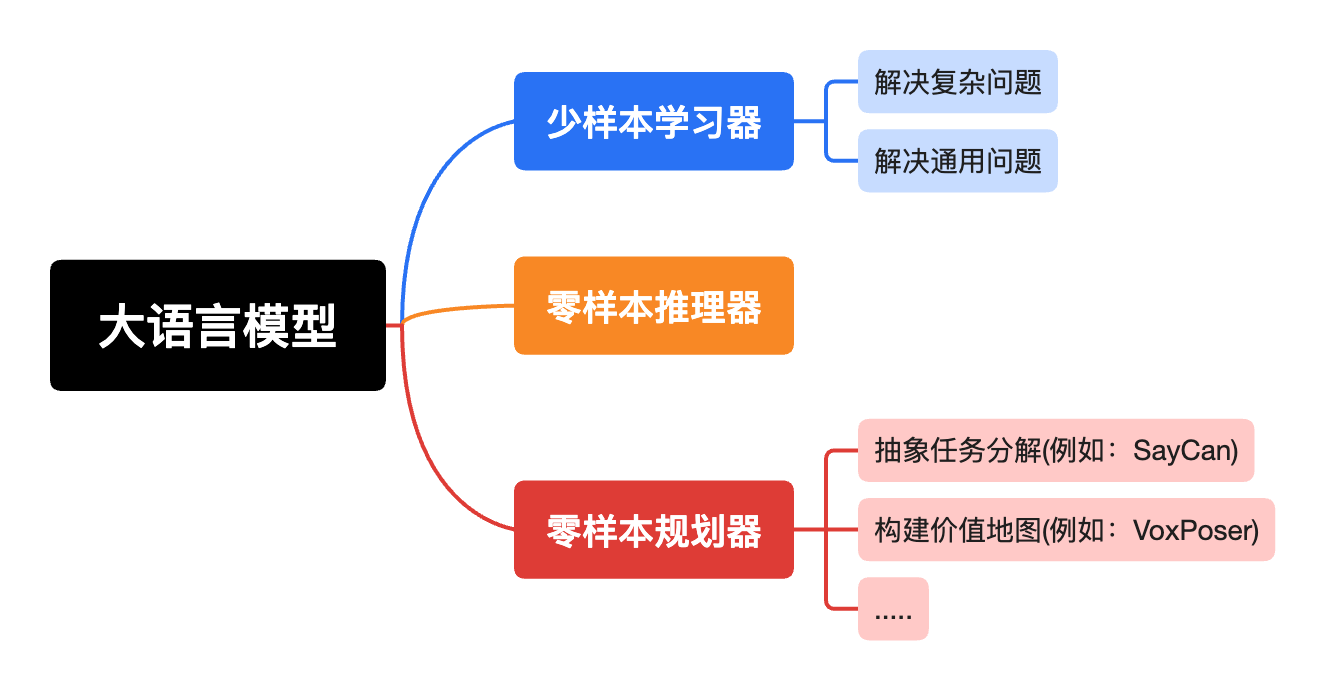
图1 大语言模型可扮演的角色
Few-Shot Learners
GPT3论文中表示语言模型扩展到175B参数量不需要梯度更新或微调,只需要少量演示样本与模型交互,就可以在很多NLP任务上实现较强的表现,即语言模型拥有较强的上下文学习(也称元学习)能力。当然,作者们也发现了一些GPT3少样本学习仍很困难的数据。
在该能力下,开启了设计思维链提示,从而利用大语言模型解决问题的大门。例如:《Self-Consistency Improves Chain of Thought Reasoning in Language Models》利用自一致性提升LLM解决复杂问题的能力,《Tree of Thoughts: Deliberate Problem Solving with Large Language Models》利用ToT思维链使大语言模型拥有了审慎决策的能力。
原理
若要实现大语言模型只需根据少量演示样本就能够一定程度的完成任务,那么有两条路径:
元学习:在训练阶段,语言模型形成一系列广泛的技能和模式识别能力。在推理阶段,利用这些能力快速适应以识别期望的任务。这种方式被称为“上下文学习”,主要通过模型以自然语言指令或少量演示为条件完成任务的方式学习。然而,这种方式的性能仍无法与微调范式相媲美。
语言建模:Transformer语言模型的不断扩展,其在下游任务上的性能不断增加。
由此,作者们假设:由于上下文学习涉及在模型参数内吸收许多技能和任务,因此上下文学习能力也会随着模型的扩展不断提升。最终,通过扩展Transformer模型验证该假设的正确性。
Zero-Shot Reasoners
论文《Large Language Models are Zero-Shot Reasoners》作者们表明:只需要在每个答案前增加Lets us think step by step,LLM可为资深的零样本推理器,可见图2(d)所示。

图2 GPT3的输入与输出样例
在处理系统2中多步推理问题(例如:数学问题)时,若利用大语言模型的少样本学习能力,那么需要针对不同的任务设计思维链提示,可见图2(b)所示。与之相比,Zero-shot-CoT拥有多功能性和任务不可知的特性。这也表明大语言模型拥有零样本能力,即只需要通过简单提示可抽取高级别多任务的认知能力。该论文凸显出探索和分析大语言模型中隐藏的大量零样本知识的重要性。
Zero-Shot Planners
论文《Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents》的作者们表明:若预训练语言模型足够大且被合适的提示,那么在不需要进一步训练的情况下可把高级别的任务拆解为中级别规划。为了把这些规划变为可执行的动作,提出了一种方法,可见图3所示。
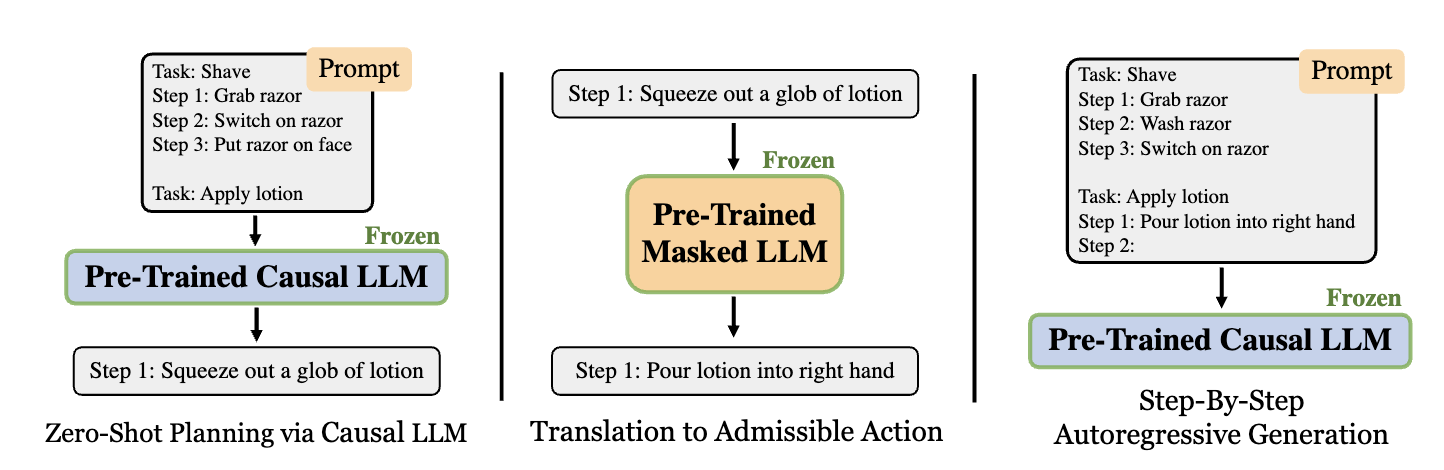
图3 生成可执行动作方法
首先,预训练因果大语言模型被相似任务的可执行规划而提示,以生成任务的规划。接下来,再利用预训练掩码语言模型把第一步规划转化为可执行的动作。最后,以相似任务的可执行规划为提示,以及该任务的第一步可执行动作作为锚,自回归的生成可执行的规划。其中,预训练掩码语言模型为BERT形式的大模型。
引用方法
请参考:
li,wanye. "新视角理解大语言模型". wyli'Blog (Jan 2025). https://www.robotech.ink/index.php/archives/696.html
或BibTex方式引用:
@online{eaiStar-696,
title={新视角理解大语言模型},
author={li,wanye},
year={2025},
month={Jan},
url="https://www.robotech.ink/index.php/archives/696.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接