BCQ:批次约束的DQN
BCQ算法是离线强化学习的开篇之作。作者们首先分析了推断错误产生的三个原因,分别是数据不足、模型偏差、训练中的不匹配。其中,数据不足是指若数据$({s}',\pi({s}'))$不足,那么$Q_{\theta}({s}',\pi({s}'))$估计也不准确;模型偏差是指贝尔曼运算$\mathcal{\tau}^{\pi}$的动态转换估计的偏差,其转换形式可见式(1)
$$ \begin{aligned} \tau^{\pi}Q(s,a)\approx\mathbb{E}_{{s}'\sim\mathcal{B}}[r+\gamma Q({s}',\pi({s}'))] \end{aligned}\tag{1} $$
式(1)中期望是关于数据集$\mathcal{B}$中转换函数的期望。
训练中的不匹配是指即使数据足够,那么若数据集$\mathcal{B}$中的数据分布与策略$\pi$对应的数据分布不一致,价值函数的估计也是不足的。
接下来,作者利用gym中Hopper-v1环境和DDPG算法做了三个实验。第一个实验Final Buffer是DDPG智能体以一定探索型噪音的方式在Hopper-v1环境中交互训练100万个时间步,存储所有的转换经验,从而创建一个包含各种各样状态-动作的数据集。接下来再利用刚收集的数据离线训练另一个DDPG智能体。第二个实验Concurrent是两个智能体同时学习。行为策略与环境交互产生数据,存储在replay-buffer。行为策略的动作增加了以高斯分布$\mathcal{N}(0,1)$的噪音,从而保证足够的探索。然后,行为克隆智能体与off-polciy智能体同时基于这份数据学习。第三个实验Imitation是一个训练好的DDPG智能体作为专家与环境交互100万步,收集这部分数据,行为克隆智能体与off-polciy智能体基于这份数据学习。
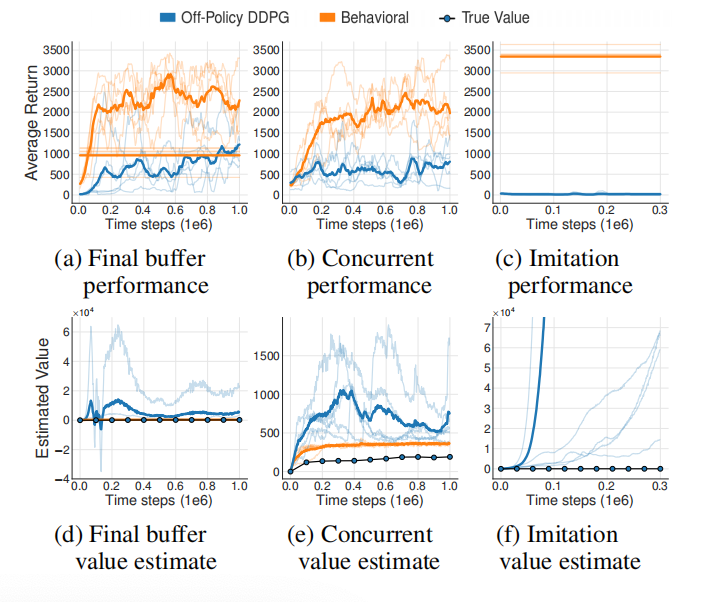
注解: 每个单独的实验结果都是用细线画出。粗线表示的是均值(无探索噪音下评估的结果)。直线代表的是episodes的平均回报(有探索噪音)。点划线是基于Monte-Carlo估计的off-policy智能体的真实值。在所有三个实验中都观察到行为克隆与off-policy智能体之间在表现上存在大的间隔。此外,off-policy智能体的值估计是不稳定的或发散的,且是高估的。
实验结果表明离线强化学习的策略明显比行为克隆算法的策略效果差。根据并发学习环境下的结果,可知,若初始策略下状态分布存在差异,那么也足够导致离线强化学习的推断错误。对于在线强化学习来说,高估有利于探索,智能体探索之后就会纠正估计。然而,对于离线强化学习来说,高估会导致盲目的乐观且得不到纠正,最终造成策略表现很差。
BCQ算法
BCQ算法背后的思想是:为了避免推断错误,策略$\pi$下的状态-动作访问分布应该与该batch数据集中状态-动作访问分布相似。满足该思想的策略被称为batch-constrained。为了得到batch-constrained策略,策略训练的目标应该是:
- 最小化策略$\pi$与行为策略$\pi_{\beta}$之间的距离。
- 策略$\pi$下的状态分布与数据集中状态分布应相似。
- 最大化价值函数。
在以上三个目标中,目标(1)的重要性高于其它两个目标。这是因为若目标(1)不能被满足,那么目标(2)和(3)也不能被满足。
作者们分析了batch-constrained策略在有限回合制马尔科决策过程中的理论特性,结论如下:
- 若策略$\pi$下数据分布完全包含于行为策略$\pi_{\beta}$下数据分布,那么batch-constrained策略能够消除推断错误。
- 与标准Q-learning相同条件下,Q-learning的batch-constrained变体能够拟合到最优策略。
- 在确定型MDP下,BCQ被保证匹配或超越行为策略$\pi_{\beta}$。
如算法1所示,BCQ算法的伪代码。

为了满足目标(1),把数据集$\mathcal{B}$中状态-动作分布建模为$P^G_{\mathcal{B}}(a\vert s)$。由于高纬空间中$P^G_{\mathcal{B}}(a\vert s)$难以估计,所以训练VAE生成模型$G_w(s)$,用于生成动作。图2中,式(13)为
$$ \begin{aligned} r+\gamma\underset{a_i}{max}[\lambda\underset{j=1,2}{min}Q_{{\theta}'_j}({s}',a_i)+(1-\lambda)\underset{j=1,2}{max}Q_{{\theta}'_j}({s}',a_i)] \end{aligned}\tag{2} $$
根据算法1,可知,BCQ算法通过VAE生成模型实现batch-constrained概念。对于给定的状态,BCQ产生一系列与batch中高度相似的动作,然后通过Q网络选择价值最高的动作。此外,还基于Clipped Double Q-learning算法的改进版,对未见过的状态进行惩罚。惩罚方式可见式(5),即价值估计选择两个Q网络的$\{Q_{\theta_1},Q_{\theta_2}\}$的最小值,这种方式被用于降低价值高估的问题,而BCQ算法中用于惩罚对不确定区域的估计方差过大的问题。同时,最大化部分用于控制未来时间步不确定性的惩罚。因此,式(5)中最小化的权重大于最大化的权重。
对于生成模型$G_{w}$,被用于采样$n$个动作。同时,为了增加随机性或多样性引入了扰动模型$\xi_{\phi}(s,a,\Phi)$,其输出范围为$[-\Phi,\Phi]$。其中,扰动模型的目标函数为
$$ \begin{aligned} \phi\leftarrow\underset{\phi}{argmax}\sum_{(s,a)\in\mathcal{B}}Q_{\theta}(s,a+\xi_{\phi}(s,a,\Phi)) \end{aligned}\tag{3} $$
确切的说,通过生成模型实现batch-constrained的方式设定了一个假设:给定状态$s$,(s,a)与离线数据集$\mathcal{B}$中状态-动作对可以被一个可学习的状态为条件的边缘似然$p_{\mathcal{B}}^G(a\vert s)$建模。在模型推理阶段,BCQ算法会从生成模型中采样$n$个动作,选择价值函数最大的作为最终动作,可见式(4)
$$ \begin{aligned} \pi(s)=\underset{a_i+\xi_{\phi}(s,a_i,\Phi)}{argmax}Q_{\theta}(s,a_i+\xi_{\phi}(s,a_i,\Phi)),\\ \{a_i\sim G_{w}(s)\}_{i=1}^n \end{aligned}\tag{4} $$
式(4)中$n,\Phi$的选择决定着模仿学习与强化学习的平衡,若$\Phi=0$且$n=1$,那么该算法为模仿学习;若$\Phi\to a_{max}-a_{min},n\to\infty$,那么算法趋近于强化学习。
引用方法
请参考:
li,wanye. "BCQ:批次约束的DQN". wyli'Blog (Feb 2024). https://www.robotech.ink/index.php/archives/181.html
或BibTex方式引用:
@online{eaiStar-181,
title={BCQ:批次约束的DQN},
author={li,wanye},
year={2024},
month={Feb},
url="https://www.robotech.ink/index.php/archives/181.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接