视觉-语言模型CLIP的核心技术点
自然语言处理领域基于原始文本的预训练模型已经可以实现零样本泛化到下游任务,且性能优越于基于高质量标签数据的模型。然而,在计算机视觉领域基于图片预测标签的SOTA模型,要么是有监督的训练,要么是预训练-微调的方式,且模型的规模也无法与GPT3这样的模型相比。作者们提出了CLIP(Contrastive Lanuage-Image Pre-training),该模型利用自然语言监督的方式在图片分类任务上大规模的训练模型。
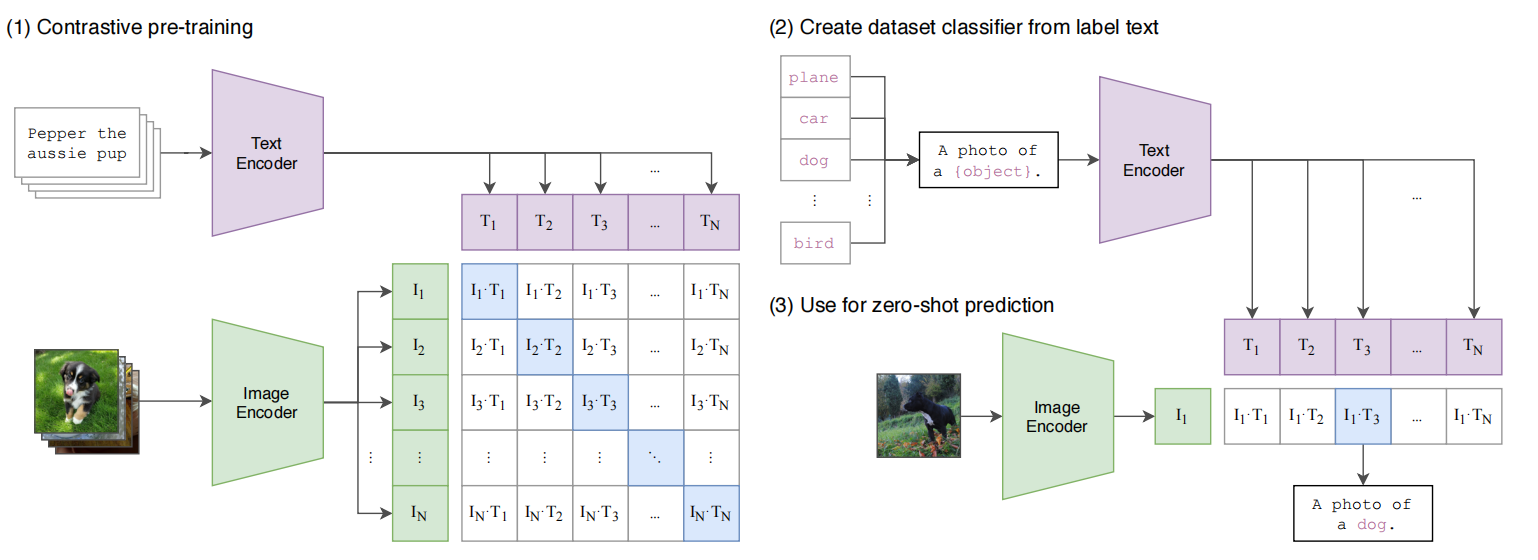
高效预训练方法
CLIP的初始训练方法与VirTex训练方法一致,从零开始联合训练一个图片CNN网络和文本transformer。然而,扩展该训练方式遇到了困难。如图2所示,6.3亿参数的transformer语言模型学习识别ImageNet数据类别比预测bag-of-words的baseline方法慢3倍,其算力需求是ResNet-50的两倍。
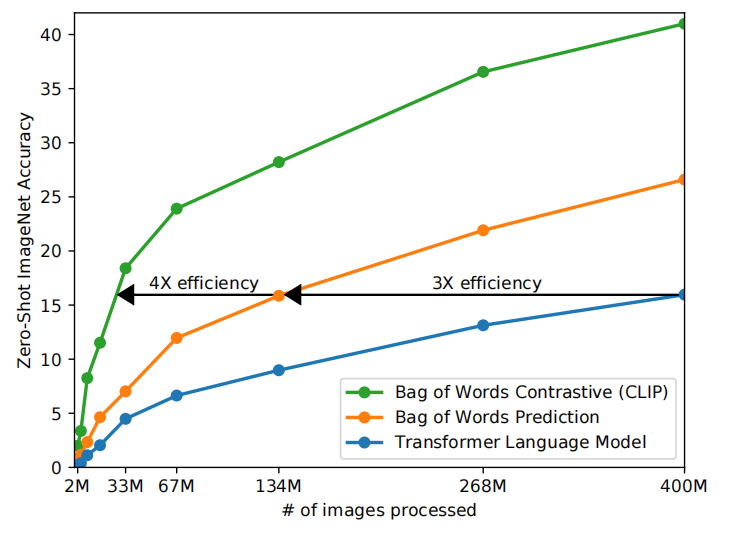
CMC的对比表示学习方法能够学习出更好的表示。iGPT作者们发现虽然图片生成模型能够学习高质量的图片表示,但是与对比学习相比需要高出一个数量级的算力。基于这些发现,作者们不再寻求精确的预测文本中单词,而是预测整个文本,以此作为容易的代理任务。根据图2可知,以对比损失为目标函数的模型展示出高于初始训练方法4倍的效率。
具体来说,给定批次$N$个(image,text)对,CLIP被训练以预测$N\times N$个可能对的概率。由此,CLIP通过最大化$N$个文本-图片对的余弦相似度和最小化$N^2-N$错误对的余弦相似度,从而学习到了一个多模态的embedding向量空间。

如图3伪代码所示,CLIP的损失函数为对称的交叉熵。这种批次的构建技术和目标函数第一次在multi-class N-pair loss中被提出,在文献$[6]$中作为InfoNCE损失广泛使用。
其它的技术细节:
- 从零开始训练CLIP模型。
- 移除了表示空间和对比embedding空间之间的非线性投射,只使用线性投射。
- 移除了ConVIRT中文本变形函数
- Square裁剪作为唯一的数据增强方法。
- 模型训练期间,温度参数直接被优化以避免作为超参数。
模型选择
图片编码器
基于两个完全不同的架构作为图片编码器,分别是ResNet-50和ViT。对于ResNet-50,作者们也做了很多修改,包括bag-of-words和antialiased rect-2 blur pooling。同时,也把全局平均池化替换为注意力池化。对于ViT,作者们只是增加了结合片段编码和位置编码的layer normalization,以及稍微不同的初始化方式。
文本编码器
文本编码器是GPT-2。在模型输入上,以文本的BPE表示作为输入。其它技术细节:
- 为了计算效率,最大序列长度为76。
- 文本序列被$[SOS]$和$[EOS]$包裹。
- 最高层的$[EOS]$token的编码作为文本的特征表示。
- 文本特征表示被layer normalized且线性投射到多模态embedding空间。
值得一提的是:基于EfficientNet的研究,ResNet同时增加模型的宽度、高度、以及模型分辨率。对于文本编码器只是使宽度与ResNet一致,这是因为CLIP的表现很少受到文本编码器容量的影响。
引用方法
请参考:
li,wanye. "视觉-语言模型CLIP的核心技术点". wyli'Blog (Feb 2024). https://www.robotech.ink/index.php/archives/174.html
或BibTex方式引用:
@online{eaiStar-174,
title={视觉-语言模型CLIP的核心技术点},
author={li,wanye},
year={2024},
month={Feb},
url="https://www.robotech.ink/index.php/archives/174.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接