足式机器人学习敏捷技能与电机动力学
经典的控制器是针对特定任务设计的,很难使机器人拥有敏捷的动作和多样的动作,运动呈现不灵活性,且很难应用到户外任务。同时,控制器的设计需要丰富经验的工程师,耗费大量时间才能设计出来,时间成本很高。与之相对的,最近基于强化学习的控制器在仿真环境中能够表现出良好的性能,它的缺点就是仿真与现实之间的gap很难处理,常见有两种处理方法,分别是提高仿真的可信度和提高策略的鲁棒性。
文献$[1]$中作者们,提出了一种不同的方法,它对于仿真方面的核心思想是:仿真环境的效率和真实性可通过机器人本体动力学模型和能够应对复杂执行接触动力学的执行器网络相结合所实现,可见图1所示控制策略的学习过程。

根据图1可知,ANYmal策略的创建过程,共分为四步:
- 机器人本体动力学建模
- 训练执行器网络
- 仿真环境中学习控制策略
- 策略网络部署到真实系统
对于基于经典动力学理论建模的机器人本体动力学模型中关节惯性特性的不精确性,在ANYmal机器中随机采样惯性特性获得30个机器人用于训练,从而提高模型的鲁棒性。
执行器的动力学包含非线性和非光滑耗散,且拥有级联的反馈环和大量不可直接观测的内部状态,所以也很难精确的建模。ANYmal对执行器的建模是基于深度神经网络采用有监督学习的方式获得模型。历史位置误差和速度构成网络的输入,力矩作为输出。同时,为了提高历史输入数据捕获动力学的有效性,引入平滑成本项惩罚策略输出突然的改变。然而,输入历史数据过多也会导致过拟合和计算成本高的问题。对于历史长度的选择,作者们给出的建议是应该比交流延时和机械响应时间之和长。
值得一提的是:对于执行器网络训练的数据是来源于基于简单参数的控制器控制机器人运动生成的足迹。
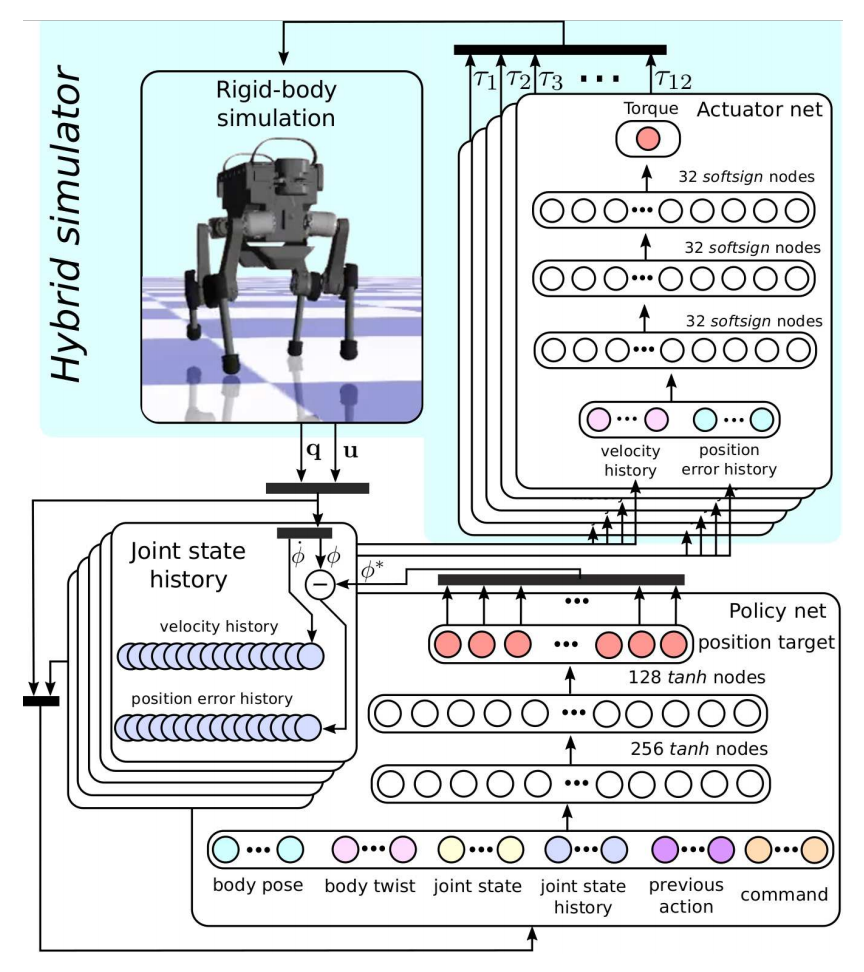
在仿真环境中策略的学习就是强化学习范式,可见图2所示。对于强化学习训练部分,状态观测中机器人的状态信息主要包含关节角度、速度、以及身体位姿;策略输出的是关节位置,再被执行器转换为扭矩。值得一提的是:模型训练时,为了使智能体能够学习到较自然的策略,利用Curriculum Learning技术。课程学习技术主要通过调节Curriculum Coefficient 的大小,从而调节它与成本函数的积,改变奖励地图, 使机器人能够逐步学会在复杂地形中行走。在模型部署时,也利用PD和PID控制器对关节运动实现控制。
参考文献
$[1]$ Hwangbo, Jemin, et al. "Learning agile and dynamic motor skills for legged robots." Science Robotics 4.26 (2019): eaau5872.
引用方法
请参考:
li,wanye. "足式机器人学习敏捷技能与电机动力学". wyli'Blog (Jan 2024). https://www.robotech.ink/index.php/archives/50.html
或BibTex方式引用:
@online{eaiStar-50,
title={足式机器人学习敏捷技能与电机动力学},
author={li,wanye},
year={2024},
month={Jan},
url="https://www.robotech.ink/index.php/archives/50.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接