视觉信息增强的足式机器人在挑战领域运动
在RMA足式机器人中,主要希望智能体学习到快速适应环境的策略。虽然RMA表现出性能较好,但是没有利用视觉信息。文献[1],在RMA的基础上增加视觉信息,机器人更能适应挑战的领域上运动。
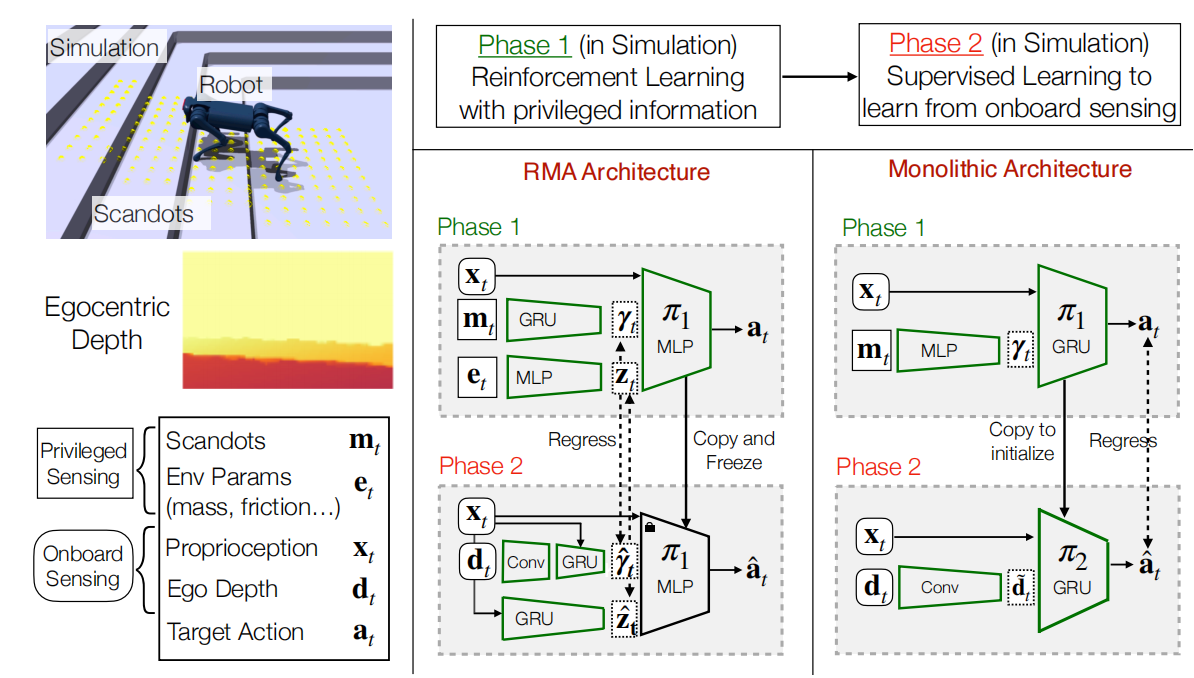
在结构上,深度相机放在了机器人的头部。这种设计背后的思想是:人或动物行走的时候,并不会关注脚下的地形,而是关注前面的部分路况,这是因为之前脚下的路况已经被短期记忆所存储。
为了高效的训练模型,如图1所示,机器人进行了两阶段的训练。第一阶段中,利用低分辨率扫描点作为深度相机的代理;第二阶段中,利用深度相机和本体状态作为RNN网络输入,基于阶段一的模型有监督学习方式预测动作。
值得一提的是,其奖励函数主要有两大类惩罚构成,分别是惩罚能量消耗和惩罚损坏硬件。具体来说,Absolute work penalty由扭矩和角速度构成用来计算做功,使机器人低能耗的运动;Cmand tracking用于使机器人能够按照命令运行;Foot jerk penalty主要由刚体之间力的差构成,用于防止较大的电动机输出变化;Feet drag penalty主要用于防止脚拖拽;Collision penalty防止碰撞;Survival bonus奖励在挑战领域生存下来的行为。在RMA机器人中,奖励函数主要由速度、加速度、扭矩、方向和功构成,即相对简单。与其它机器一样,在训练阶段,主要是采用由易到难的课程学习方式训练。
参考文献
$[1]$ Agarwal A, Kumar A, Malik J, et al. Legged locomotion in challenging terrains using egocentric vision$[C]$//Conference on Robot Learning. PMLR, 2023: 403-415.
引用方法
请参考:
li,wanye. "视觉信息增强的足式机器人在挑战领域运动". wyli'Blog (Jan 2024). https://www.robotech.ink/index.php/archives/52.html
或BibTex方式引用:
@online{eaiStar-52,
title={视觉信息增强的足式机器人在挑战领域运动},
author={li,wanye},
year={2024},
month={Jan},
url="https://www.robotech.ink/index.php/archives/52.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接