足式机器人的快速电机自适应
经典的足式机器人主要是基于物理动力学和控制理论实现,这种方法需要大量的专家设计才能有效果。然而,这种方式仍然无法应对不确定性的环境。最近,基于强化学习和模仿学习的范式取得了很大的成功。然而,强化学习用于机器人存在Sim2Real Gap的问题,阻碍了发展。对于该问题经典的解决方案是利用Sim2Real技术把算法模型从虚拟环境迁移到真实环境,仍然具有很大的挑战。这是因为Sim2Real Gap本身是很多因素的结果,分别是
- 物理机器人与它在仿真器中模型本身存在很大的不同。
- 真实世界的环境与虚拟环境相比,变化很大。
- 物理仿真器无法精确建模真实环境的物理属性。
文献$[1]$中作者受到人类在真实世界行走时,具有快速适应不同领域的特性的启发,提出了快速电机自适应(Rapid Motor Adaption, RMA)。然而,由于机器人在物理世界中电动机接受指令的频率很高,因此无法执行多次实验以选择较合适的行走策略。可以理解为,物理世界的机器人不仅仅要求拥有基本的行走策略,还有快速的自适应。
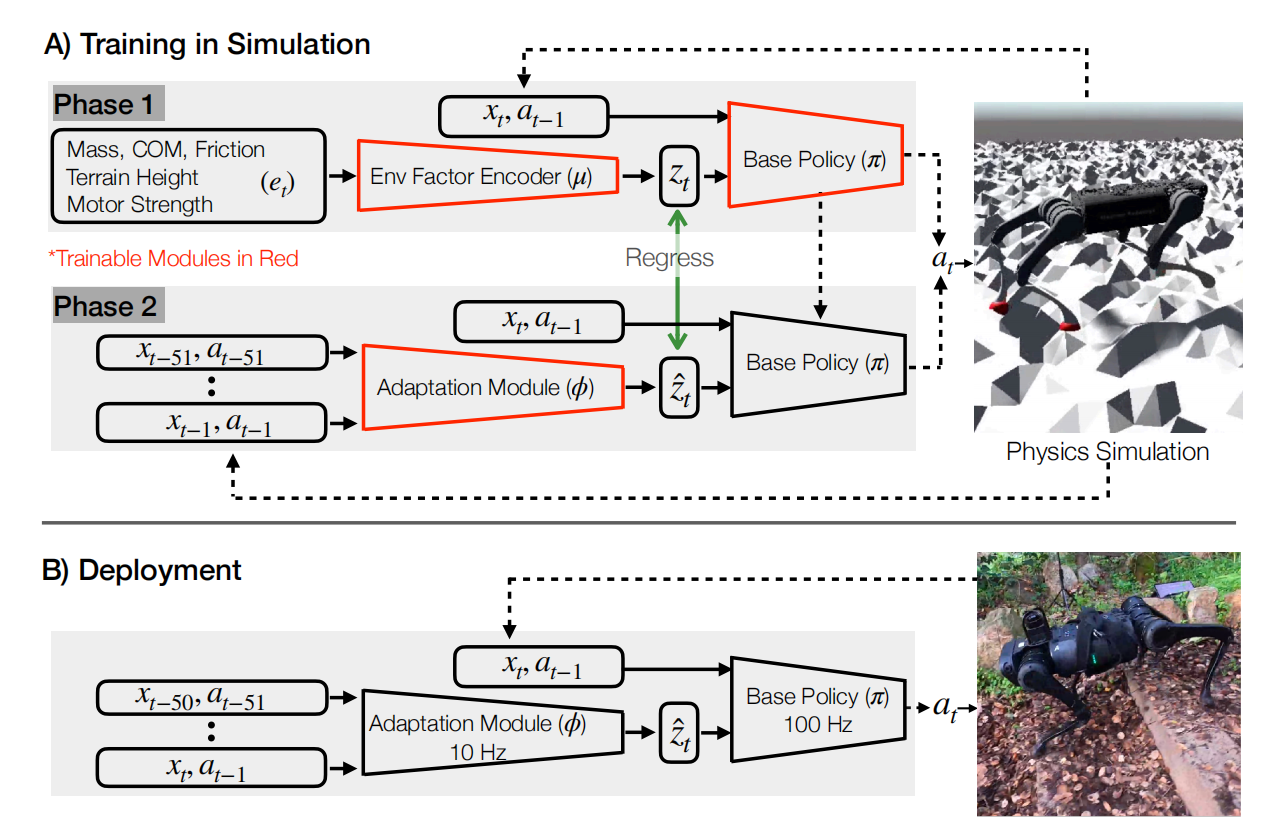
如图1所示,RMA由两大系统组成,分别是基础策略$\pi$与适应模块$\phi$。
在模型训练阶段,对于基础策略模型的训练,利用当前状态$x_t$、上一个动作$a_{t-1}$、以及先验的环境配置信息$e_t$的embedding$z_t$作为输入,预测动作$a_t$。其中,$z_t$也被称为外部因素。对于编码网络$\mu$的训练,是与策略网络$\pi$联合起来训练的。
对于适应模块$\phi$的训练,由于模型部署阶段真实世界的$e_t$无法知道,因此需要估计外部因素$z_t$,被称为自适应模块$\phi_t$。自适应模块背后的思想是机器人关节运动的不同取决于外部因素。因此,希望能够利用机器的历史状态信息估计外部因素向量,类似于卡尔曼滤波运算。自适应模块的训练是利用监督学习的方式,这是因为仿真环境中外部因素$z_t$可由编码网络预测,历史状态信息可方便获得。
在部署阶段,基础策略以100HZ运行,而自适应模块以10HZ运行,即异步部署。
奖励设计
值得一提的是,基础策略的训练是基于生物能量学设计的“自然”奖励函数,可见文献$[2]$和$[3]$。还有,为了机器人应对各种各样的环境,作者设计了一个变化的环境生成器。如图2所示,奖励函数是由若干项之和。

根据图2可知,奖励函数的主要目的有奖励前向运动、惩罚横向运动或偏航运动、鼓励能耗更低的运动、避免碰撞、惩罚动作不平滑、惩罚动作幅度、惩罚关节速度、惩罚转圈和抬腿、惩罚基座上下运动、以及惩罚脚的平滑。总的来说,鼓励前向运动,惩罚其它运动形式。其中奖励项的缩放因子很可能是基于每项奖励的量级而选择,使其在同一个量级。
综合自己阅读论文,奖励项是基于$l_2$范数计算得到,也有以$l_2$范数为指数且$e$为底计算得到,或者$l_2$范数为对数项计算得到。
plus: 根据自己的理解,这种技术的前提假设是机器人的下一步动作应该与过去一段时间的自身状态和动作有关。然而,这种假设的成立条件是环境不是急剧突变。所以只是依赖这种自适应很难真正的做到应对各种环境,更可靠的方法是加入视觉等信息。
参考文献
$[1]$ Kumar A, Fu Z, Pathak D, et al. Rma: Rapid motor adaptation for legged robots$[J]$. arXiv preprint arXiv:2107.04034, 2021.
$[2]$ Peng X B, Coumans E, Zhang T, et al. Learning agile robotic locomotion skills by imitating animals$[J]$. arXiv preprint arXiv:2004.00784, 2020.
$[3]$ Polet D T, Bertram J E A. An inelastic quadrupedal model discovers four-beat walking, two-beat running, and pseudo-elastic actuation as energetically optimal$[J]$. PLoS computational biology, 2019, 15(11): e1007444.
引用方法
请参考:
li,wanye. "足式机器人的快速电机自适应". wyli'Blog (Jan 2024). https://www.robotech.ink/index.php/archives/34.html
或BibTex方式引用:
@online{eaiStar-34,
title={足式机器人的快速电机自适应},
author={li,wanye},
year={2024},
month={Jan},
url="https://www.robotech.ink/index.php/archives/34.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接