AI与计算
文章来源于OpenAI's Blog:AI and compute
注:文章直接用Google翻译,可能存在不准确的情况,所以也贴出了英文原文。
We’re releasing an analysis showing that since 2012, the amount of compute used in the largest AI training runs has been increasing exponentially with a 3.4-month doubling time (by comparison, Moore’s Law had a 2-year doubling period). Since 2012, this metric has grown by more than 300,000x (a 2-year doubling period would yield only a 7x increase). Improvements in compute have been a key component of AI progress, so as long as this trend continues, it’s worth preparing for the implications of systems far outside today’s capabilities.
我们发布的分析显示,自 2012 年以来,最大规模 AI 训练运行中使用的计算量呈指数级增长,翻倍时间为 3.4 个月(相比之下,摩尔定律的翻倍周期为 2 年)。自 2012 年以来,这一指标增长了 300,000 多倍(2 年的翻倍周期只能产生 7 倍的增长)。计算能力的提升一直是 AI 进步的关键组成部分,因此只要这一趋势持续下去,就值得为远远超出当今能力的系统带来的影响做好准备。
AlexNet to AlphaGo Zero: 300,000x increase in compute
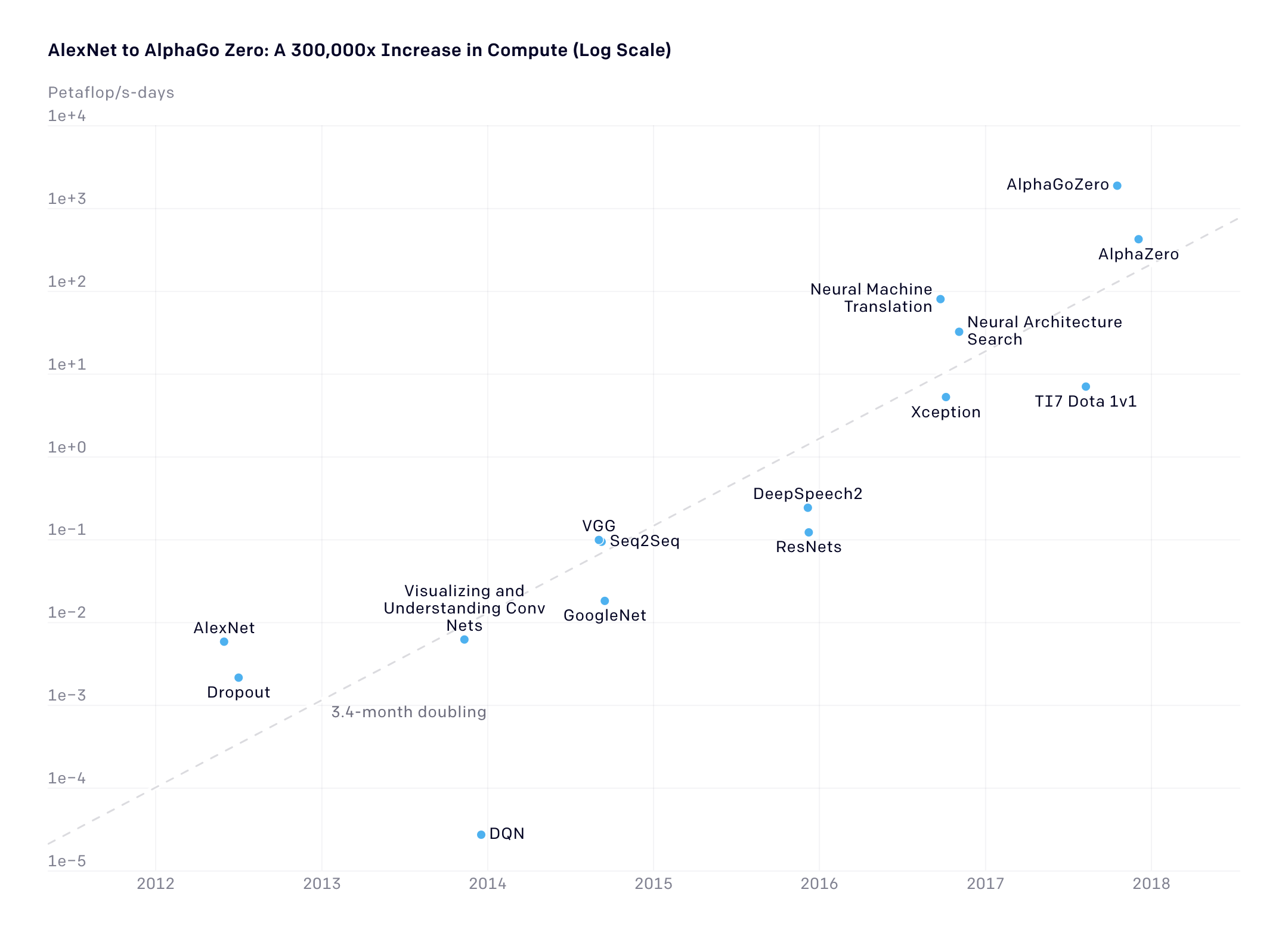
The total amount of compute, in petaflop/s-days,1 used to train selected results that are relatively well known, used a lot of compute for their time, and gave enough information to estimate the compute used.
用于训练相对知名的选定结果的总计算量(以 petaflop/s-days 为单位)1 在其时间内使用了大量计算,并提供了足够的信息来估计所使用的计算量。
概览
Three factors drive the advance of AI: algorithmic innovation, data (which can be either supervised data or interactive environments), and the amount of compute available for training. Algorithmic innovation and data are difficult to track, but compute is unusually quantifiable, providing an opportunity to measure one input to AI progress. Of course, the use of massive compute sometimes just exposes the shortcomings of our current algorithms. But at least within many current domains, more compute seems to lead predictably to better performance(opens in a new window), and is often complementary to algorithmic advances.
推动人工智能发展的因素有三个:算法创新、数据(可以是监督数据或交互式环境)以及可用于训练的计算量。算法创新和数据难以追踪,但计算却可以量化,为衡量人工智能进步的一项投入提供了机会。当然,使用大量计算有时只会暴露我们当前算法的缺点。但至少在当前的许多领域中,更多的计算似乎可以预见地带来更好的性能(在新窗口中打开),并且通常与算法进步相辅相成。
For this analysis, we believe the relevant number is not the speed of a single GPU, nor the capacity of the biggest datacenter, but the amount of compute that is used to train a single model—this is the number most likely to correlate to how powerful our best models are. Compute per model differs greatly from total bulk compute because limits on parallelism(opens in a new window) (both hardware and algorithmic) have constrained how big a model can be or how much it can be usefully trained. Of course, important breakthroughs are still made with modest amounts of compute—this analysis just covers compute capability.
对于本分析,我们认为相关数字不是单个 GPU 的速度,也不是最大数据中心的容量,而是用于训练单个模型的计算量——这个数字最有可能与我们的最佳模型的强大程度相关。每个模型的计算量与总体计算量大不相同,因为并行性(硬件和算法)的限制限制了模型的大小或训练的有效性。当然,重要的突破仍然需要适度的计算量——本分析仅涵盖计算能力。
The trend represents an increase by roughly a factor of 10 each year. It’s been partly driven by custom hardware that allows more operations to be performed per second for a given price (GPUs and TPUs), but it’s been primarily propelled by researchers repeatedly finding ways to use more chips in parallel and being willing to pay the economic cost of doing so.
这一趋势每年大约增长 10 倍。这在一定程度上是由定制硬件推动的,这些硬件允许以给定价格(GPU 和 TPU)每秒执行更多操作,但主要推动力是研究人员不断寻找并行使用更多芯片的方法,并愿意为此付出经济成本。
时代
Looking at the graph we can roughly see four distinct eras:
- Before 2012: It was uncommon to use GPUs for ML, making any of the results in the graph difficult to achieve.
- 2012 to 2014: Infrastructure to train on many GPUs was uncommon, so most results used 1-8 GPUs rated at 1-2 TFLOPS for a total of 0.001-0.1 pfs-days.
- 2014 to 2016: Large-scale results used 10-100 GPUs rated at 5-10 TFLOPS, resulting in 0.1-10 pfs-days. Diminishing returns on data parallelism meant that larger training runs had limited value.
- 2016 to 2017: Approaches that allow greater algorithmic parallelism such as huge batch sizes(opens in a new window), architecture search(opens in a new window), and expert iteration(opens in a new window), along with specialized hardware such as TPU’s and faster interconnects, have greatly increased these limits, at least for some applications.
AlphaGoZero/AlphaZero is the most visible public example of massive algorithmic parallelism, but many other applications at this scale are now algorithmically possible, and may already be happening in a production context.
从图表中我们大致可以发现四个不同的时代:
- 2012 年之前:使用 GPU 进行机器学习并不常见,因此图中的任何结果都难以实现。
- 2012 年至 2014 年:在许多 GPU 上进行训练的基础设施并不常见,因此大多数结果使用 1-8 个 GPU,额定为 1-2 TFLOPS,总计 0.001-0.1 pfs 天。
- 2014 年至 2016 年:大规模结果使用了 10-100 个 GPU,额定速度为 5-10 TFLOPS,结果为 0.1-10 pfs-days。数据并行性的收益递减意味着更大规模的训练运行价值有限。
- 2016 年至 2017 年:允许更大算法并行性的方法,例如大批量大小(在新窗口中打开)、架构搜索(在新窗口中打开)和专家迭代(在新窗口中打开),以及专用硬件(例如 TPU 和更快的互连),至少对于某些应用程序而言,大大增加了这些限制。
AlphaGoZero/AlphaZero 是大规模算法并行性最引人注目的公开例子,但这种规模的许多其他应用现在在算法上都是可行的,并且可能已经在生产环境中发生。
展望
We see multiple reasons to believe that the trend in the graph could continue. Many hardware startups(opens in a new window) are developing AI-specific chips, some of which claim they will achieve a substantial increase in FLOPS/Watt (which is correlated to FLOPS/$) over the next 1–2 years. There may also be gains from simply reconfiguring hardware to do the same number of operations for less economic cost(opens in a new window). On the parallelism side, many of the recent algorithmic innovations described above could in principle be combined multiplicatively—for example, architecture search and massively parallel SGD.
我们看到多个理由相信图表中的趋势可能会持续下去。许多硬件初创公司(在新窗口中打开)正在开发 AI 专用芯片,其中一些声称他们将在未来 1-2 年内实现 FLOPS/Watt(与 FLOPS/$ 相关)的大幅增长。只需重新配置硬件以较低的经济成本执行相同数量的操作(在新窗口中打开),也可能会带来收益。在并行性方面,上面描述的许多最新算法创新原则上可以乘法组合 - 例如,架构搜索和大规模并行 SGD。
On the other hand, cost will eventually limit the parallelism side of the trend and physics will limit the chip efficiency side. We believe the largest training runs today employ hardware that cost in the single digit millions of dollars to purchase (although the amortized cost is much lower). But the majority of neural net compute today is still spent on inference (deployment), not training, meaning companies can repurpose or afford to purchase much larger fleets of chips for training. Therefore, if sufficient economic incentive exists, we could see even more massively parallel training runs, and thus the continuation of this trend for several more years. The world’s total hardware budget is 1 trillion dollars(opens in a new window) a year, so absolute limits remain far away. Overall, given the data above, the precedent for exponential trends in computing, work on ML specific hardware, and the economic incentives at play, we think it’d be a mistake to be confident this trend won’t continue in the short term.
另一方面,成本最终将限制趋势的并行性方面,而物理将限制芯片效率方面。我们认为,当今最大规模的训练运行使用的硬件购买成本为数百万美元(尽管摊销成本要低得多)。但当今神经网络计算的大部分仍用于推理(部署),而不是训练,这意味着公司可以重新利用或负担得起购买更大的芯片组进行训练。因此,如果存在足够的经济激励,我们可能会看到更大规模的并行训练运行,从而继续这种趋势几年。全球每年的硬件总预算为 1 万亿美元(在新窗口中打开),因此绝对限制仍然遥不可及。总体而言,鉴于上述数据、计算指数趋势的先例、ML 特定硬件的工作以及发挥作用的经济激励,我们认为相信这种趋势不会在短期内持续下去是一个错误。
Past trends are not sufficient to predict how long the trend will continue into the future, or what will happen while it continues. But even the reasonable potential for rapid increases in capabilities means it is critical to start addressing both safety and malicious use of AI today. Foresight is essential to responsible policymaking(opens in a new window) and responsible technological development, and we must get out ahead of these trends rather than belatedly reacting to them.
过去的趋势不足以预测这种趋势将持续多久,也不足以预测这种趋势持续下去会发生什么。但即使能力有快速增长的合理潜力,也意味着现在开始解决人工智能的安全和恶意使用问题至关重要。远见对于负责任的政策制定和负责任的技术发展至关重要,我们必须走在这些趋势之前,而不是迟迟做出反应。
If you’d like to help make sure that AI progress benefits all of humanity, join us at OpenAI. Our research and engineering roles range from machine learning researchers(opens in a new window) to policy researchers(opens in a new window) to infrastructure engineers(opens in a new window).
如果您想帮助确保 AI 进步造福全人类,请加入 OpenAI。我们的研究和工程职位包括机器学习研究人员(在新窗口中打开)、政策研究人员(在新窗口中打开)和基础设施工程师(在新窗口中打开)。
- footnote-petaflops ↩
引用方法
请参考:
li,wanye. "AI与计算". wyli'Blog (Aug 2024). https://www.robotech.ink/index.php/archives/591.html
或BibTex方式引用:
@online{eaiStar-591,
title={AI与计算},
author={li,wanye},
year={2024},
month={Aug},
url="https://www.robotech.ink/index.php/archives/591.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接