AI与效率
文章来源于OpenAI's Blog:AI and efficiency
注:文章直接用Google翻译,可能存在不准确的情况,所以也贴出了英文原文。
We’re releasing an analysis showing that since 2012 the amount of compute needed to train a neural net to the same performance on ImageNet classification has been decreasing by a factor of 2 every 16 months. Compared to 2012, it now takes 44 times less compute to train a neural network to the level of AlexNet (by contrast, Moore’s Law would yield an 11x cost improvement over this period). Our results suggest that for AI tasks with high levels of recent investment, algorithmic progress has yielded more gains than classical hardware efficiency.
我们发布的一项分析显示,自 2012 年以来,训练神经网络达到 ImageNet 分类的相同性能所需的计算量每 16 个月减少 2 倍。与 2012 年相比,现在训练神经网络达到 AlexNet 水平所需的计算量减少了 44 倍(相比之下,摩尔定律将在此期间将成本降低 11 倍)。我们的结果表明,对于近期投入大量的 AI 任务,算法进步带来的收益比传统硬件效率更高。
Algorithmic improvement is a key factor driving the advance of AI. It’s important to search for measures that shed light on overall algorithmic progress, even though it’s harder than measuring such trends in compute.4
算法改进是推动人工智能进步的关键因素。寻找能够揭示整体算法进展的指标很重要,尽管这比衡量计算中的此类趋势更难。
44x less compute required to get to AlexNet performance 7 years later
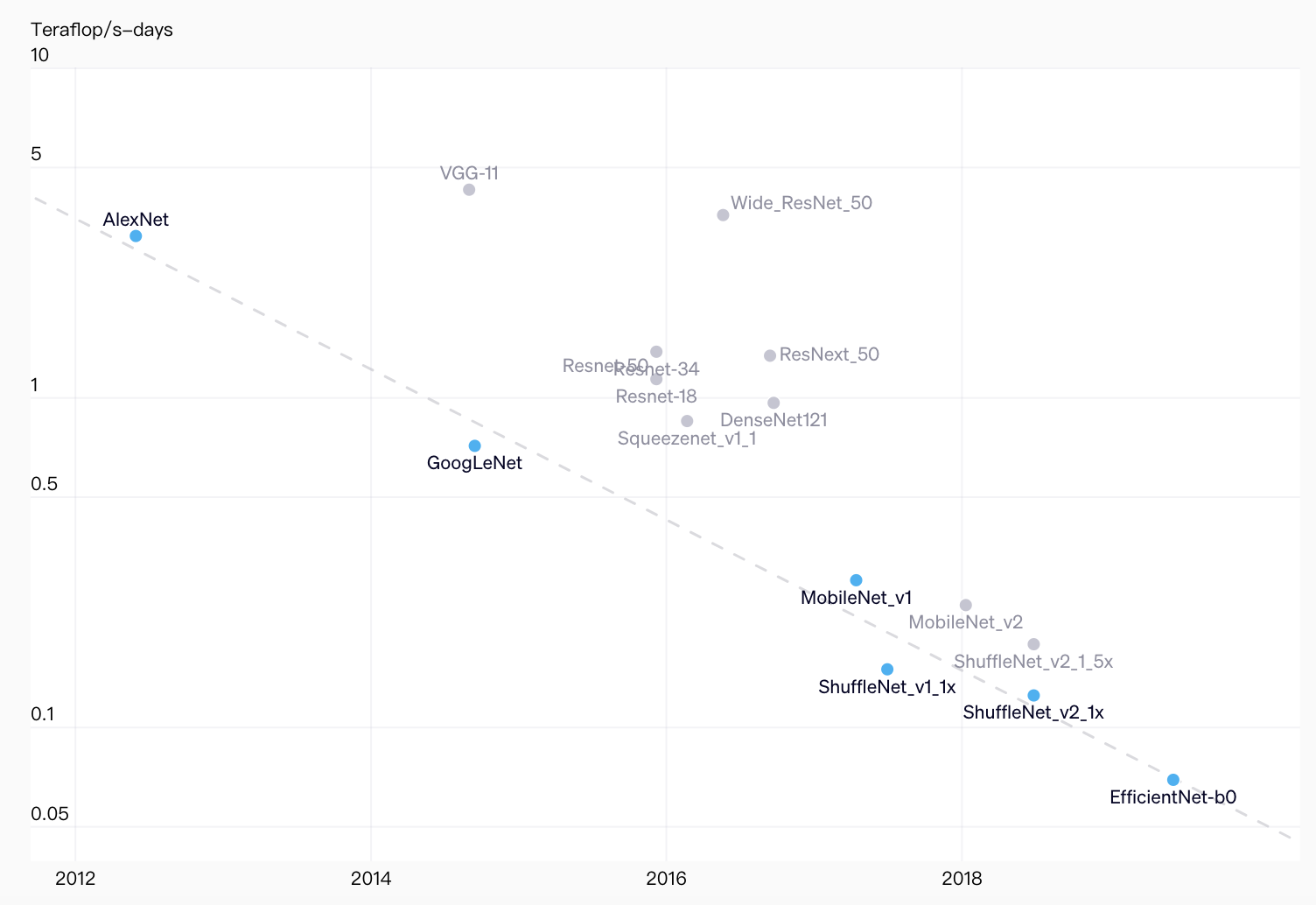
Total amount of compute in teraflops/s-days used to train to AlexNet level performance. Lowest compute points at any given time shown in blue, all points measured shown in gray.
用于训练以达到 AlexNet 级别性能的每日万亿次浮点运算总量。任何给定时间的最低计算点以蓝色显示,所有测量点以灰色显示。
测量效率
Algorithmic efficiency can be defined as reducing the compute needed to train a specific capability. Efficiency is the primary way we measure algorithmic progress on classic computer science problems like sorting. Efficiency gains on traditional problems like sorting are more straightforward to measure than in ML because they have a clearer measure of task difficulty.A However, we can apply the efficiency lens to machine learning by holding performance constant. Efficiency trends can be compared across domains like DNA sequencing17 (10-month doubling), solar energy18 (6-year doubling), and transistor density3 (2-year doubling).
算法效率可以定义为减少训练特定能力所需的计算量。效率是我们衡量算法在经典计算机科学问题(如排序)上进展的主要方式。传统问题(如排序)的效率提升比机器学习更容易衡量,因为它们可以更清楚地衡量任务难度。A 但是,我们可以通过保持性能不变将效率视角应用于机器学习。效率趋势可以跨领域进行比较,例如 DNA 测序17(10 个月翻一番)、太阳能18(6 年翻一番)和晶体管密度3(2 年翻一番)。
For our analysis, we primarily leveraged open-source re-implementations19, 20, 21 to measure progress on AlexNet level performance over a long horizon. We saw a similar rate of training efficiency improvement for ResNet-50 level performance on ImageNet (17-month doubling time).7, 16 We saw faster rates of improvement over shorter timescales in Translation, Go, and Dota 2:
- Within translation, the Transformer22 surpassed seq2seq23 performance on English to French translation on WMT’14 with 61x less training compute 3 years later.
- We estimate AlphaZero24 took 8x less compute to get to AlphaGoZero25 level performance 1 year later.
- OpenAI Five Rerun required 5x less training compute to surpass OpenAI Five26 (which beat the world champions, OG(opens in a new window)) 3 months later.
在我们的分析中,我们主要利用开源重新实现19、20、21 来衡量 AlexNet 级别长期性能的进展。我们发现 ResNet-50 级别性能在 ImageNet 上的训练效率提升速度相似(17 个月翻倍时间)。我们在 Translation、Go 和 Dota 2 中看到了更快速的改进速度:
- 在翻译方面,Transformer22 在 WMT’14 上的英语到法语翻译中的表现超过了 seq2seq23,三年后,训练计算量减少了 61 倍。
- 我们估计,AlphaZero24 所需的计算量减少了 8 倍,一年后就达到了 AlphaGoZero25 级别的性能。
- 3 个月后,OpenAI Five Rerun 所需的训练计算量减少了 5 倍,便超越了 OpenAI Five26(后者击败了世界冠军 OG(opens in a new window))。
It can be helpful to think of compute in 2012 not being equal to compute in 2019 in a similar way that dollars need to be inflation-adjusted over time. A fixed amount of compute could accomplish more in 2019 than in 2012. One way to think about this is that some types of AI research progress in two stages, similar to the “tick tock” model of development seen in semiconductors; new capabilities (the “tick”) typically require a significant amount of compute expenditure to obtain, then refined versions of those capabilities (the “tock”) become much more efficient to deploy due to process improvements.
我们可以这样想:2012 年的计算量与 2019 年的计算量并不相等,就像美元需要随时间推移进行通货膨胀调整一样。固定数量的计算量在 2019 年可以比 2012 年实现更多目标。一种思考方式是,某些类型的人工智能研究分为两个阶段进行,类似于半导体领域的“滴答”发展模式;新功能(“滴答”)通常需要大量的计算支出才能获得,然后这些功能的精炼版本(“滴答”)由于流程改进而变得更加高效。
Increases in algorithmic efficiency allow researchers to do more experiments of interest in a given amount of time and money. In addition to being a measure of overall progress, algorithmic efficiency gains speed up future AI research in a way that’s somewhat analogous to having more compute.
算法效率的提高使研究人员能够在给定的时间和金钱内进行更多感兴趣的实验。除了衡量整体进展之外,算法效率的提高还可以加速未来的人工智能研究,这在某种程度上类似于拥有更多的计算能力。
AI进展的其它测量
In addition to efficiency, many other measures shed light on overall algorithmic progress in AI. Training cost in dollars28 is related, but less narrowly focused on algorithmic progress because it’s also affected by improvement in the underlying hardware, hardware utilization, and cloud infrastructure. Sample efficiency is key when we’re in a low data regime, which is the case for many tasks of interest. The ability to train models faster29 also speeds up research and can be thought of as a measure of the parallelizability30 of learning capabilities of interest. We also find increases in inference efficiency in terms of GPU time31, parameters16, and flops meaningful, but mostly as a result of their economic implicationsB rather than their effect on future research progress. Shufflenet13 achieved AlexNet-level performance with an 18x inference efficiency increase in 5 years (15-month doubling time), which suggests that training efficiency and inference efficiency might improve at similar rates. The creation of datasets/environments/benchmarks is a powerful method of making specific AI capabilities of interest more measurable.
除了效率之外,许多其他指标也揭示了人工智能的整体算法进展。训练成本(美元)28 与算法进展相关,但不太局限于算法进展,因为它还受到底层硬件、硬件利用率和云基础设施改进的影响。当我们处于低数据状态时,样本效率是关键,许多感兴趣的任务都是这种情况。更快地训练模型的能力29 也加快了研究速度,可以被认为是衡量感兴趣的学习能力的可并行性30 的指标。我们还发现,在 GPU 时间31、参数16 和 flops 方面,推理效率的提高意义重大,但主要是因为它们的经济影响B,而不是它们对未来研究进展的影响。Shufflenet13 在 5 年内(15 个月翻倍时间)实现了 AlexNet 级别的性能,推理效率提高了 18 倍,这表明训练效率和推理效率可能会以相似的速度提高。创建数据集/环境/基准是一种使感兴趣的特定 AI 功能更易于衡量的强大方法。
主要局限性
- We have only a small number of algorithmic efficiency data points on a few tasks. It’s unclear the degree to which the efficiency trends we’ve observed generalize to other AI tasks. Systematic measurement could make it clear whether an algorithmic equivalent to Moore’s LawC in the domain of AI exists, and if it exists, clarify its nature. We consider this a highly interesting open question. We suspect we’re more likely to observe similar rates of efficiency progress on similar tasks. By similar tasks, we mean tasks within these sub-domains of AI, on which the field agrees we’ve seen substantial progress, and that have comparable levels of investment (compute and/or researcher time).
- Even though we believe AlexNet represented a lot of progress, this analysis doesn’t attempt to quantify that progress. More generally, the first time a capability is created, algorithmic breakthroughs may have reduced the resources required from totally infeasibleD to merely high. We think new capabilities generally represent a larger share of overall conceptual progress than observed efficiency increases of the type shown here.
- This analysis focuses on the final training run cost for an optimized model rather than total development costs. Some algorithmic improvements make it easier to train a model by making the space of hyperparameters that will train stably and get good final performance much larger. On the other hand, architecture searches increase the gap between the final training run cost and total training costs.
- We don’t speculateE on the degree to which we expect efficiency trends will extrapolate in time, we merely present our results and discuss the implications if the trends persist.
- 我们在少数任务上只有少量的算法效率数据点。我们观察到的效率趋势在多大程度上可以推广到其他人工智能任务尚不清楚。系统测量可以明确人工智能领域是否存在与摩尔定律C 相当的算法,如果存在,则可以阐明其性质。我们认为这是一个非常有趣的开放性问题。我们怀疑我们更有可能在类似的任务上观察到类似的效率进步率。我们所说的类似任务是指人工智能这些子域内的任务,该领域同意我们已经看到了实质性的进展,并且具有可比的投资水平(计算和/或研究人员的时间)。
- 尽管我们认为 AlexNet 代表了很多进展,但这种分析并不试图量化这种进展。更一般地说,第一次创建一种能力时,算法突破可能已经将所需的资源从完全不可行D 降低到仅仅很高。我们认为,新功能通常比此处显示的观察到的效率提高占整体概念进步的更大份额。
- 本分析侧重于优化模型的最终训练运行成本,而非总开发成本。一些算法改进通过扩大能够稳定训练并获得良好最终性能的超参数空间,使模型训练变得更加容易。另一方面,架构搜索会增加最终训练运行成本与总训练成本之间的差距。
- 我们不会推测效率趋势会随时间推移而变化的程度,我们只是展示结果并讨论趋势持续时的影响。
测量与AI政策
We believe32 that policymaking related to AI will be improved by a greater focus on the measurement and assessment of AI systems, both in terms of technical attributes and societal impact. We think such measurement initiatives can shed light on important questions in policy; our AI and Compute4 analysis suggests policymakers should increase funding for compute resources for academia, so that academic research can replicate, reproduce, and extend industry research. This efficiency analysis suggests that policymakers could develop accurate intuitions about the cost of deploying AI capabilities—and how these costs are going to alter over time—by more closely assessing the rate of improvements in efficiency for AI systems.
我们相信32,通过更加关注人工智能系统的测量和评估(无论是技术属性还是社会影响),与人工智能相关的政策制定将得到改善。我们认为,此类测量举措可以阐明政策中的重要问题;我们的人工智能和 Compute4 分析表明,政策制定者应增加对学术界计算资源的资助,以便学术研究可以复制、再现和扩展行业研究。这项效率分析表明,通过更仔细地评估人工智能系统效率的提高速度,政策制定者可以对部署人工智能能力的成本以及这些成本将如何随时间变化形成准确的直觉。
展望
If large scale compute continues to be important to achieving state of the art (SOTA) overall performance in domains like language and games then it’s important to put effort into measuring notable progress achieved with smaller amounts of compute (contributions often made by academic institutions). Models that achieve training efficiency state of the arts on meaningful capabilities are promising candidates for scaling up and potentially achieving overall top performance. Additionally, figuring out the algorithmic efficiency improvements are straightforwardF since they are just a particularly meaningful slice of the learning curves that all experiments generate.
如果大规模计算对于在语言和游戏等领域实现最先进 (SOTA) 的整体性能仍然很重要,那么就必须努力衡量用较少的计算量(通常由学术机构做出的贡献)取得的显著进展。在有意义的能力上达到训练效率最先进水平的模型是有希望扩大规模并可能实现整体顶级性能的候选者。此外,理解算法效率改进很简单,因为它们只是所有实验产生的学习曲线中特别有意义的一部分。
We also think that measuring long run trends in efficiency SOTAs will help paint a quantitative picture of overall algorithmic progress. We observe that hardware and algorithmic efficiency gains are multiplicative and can be on a similar scale over meaningful horizons, which suggests that a good model of AI progress should integrate measures from both.
我们还认为,衡量 SOTA 的长期效率趋势将有助于定量描绘出整体算法进步的图景。我们观察到,硬件和算法的效率提升具有乘法效应,并且在有意义的范围内可以达到类似的规模,这表明一个好的 AI 进步模型应该整合两者的指标。
Our results suggest that for AI tasks with high levels of investment (researcher time and/or compute) algorithmic efficiency might outpace gains from hardware efficiency (Moore’s Law). Moore’s Law was coined in 1965 when integrated circuits had a mere 64 transistors (6 doublings) and naively extrapolating it out predicted personal computers and smartphones (an iPhone 11 has 8.5 billion transistors). If we observe decades of exponential improvement in the algorithmic efficiency of AI, what might it lead to? We’re not sure. That these results make us ask this question is a modest update for us towards a future with powerful AI services and technology.
我们的结果表明,对于需要大量投资(研究人员的时间和/或计算)的 AI 任务,算法效率可能会超过硬件效率的提升(摩尔定律)。摩尔定律诞生于 1965 年,当时集成电路只有 64 个晶体管(增加了 6 倍),并天真地推断出个人电脑和智能手机(iPhone 11 有 85 亿个晶体管)。如果我们观察到 AI 算法效率数十年来呈指数级提升,这会带来什么?我们不确定。这些结果让我们提出这个问题,这对我们来说是向拥有强大 AI 服务和技术的未来迈进的适度更新。
For all these reasons, we’re going to start tracking efficiency SOTAs publicly. We’ll start with vision and translation efficiency benchmarks (ImageNetG and WMT14), and we’ll consider adding more benchmarks over time. We believe there are efficiency SOTAs on these benchmarks we’re unaware of and encourage the research community to submit them here(opens in a new window) (we’ll give credit to original authors and collaborators).
出于所有这些原因,我们将开始公开跟踪效率 SOTA。我们将从视觉和翻译效率基准(ImageNetG 和 WMT14)开始,并考虑随着时间的推移添加更多基准。我们相信这些基准上有一些我们不知道的效率 SOTA,并鼓励研究界在此处提交它们(我们将向原作者和合作者致谢)。
Industry leaders, policymakers, economists, and potential researchers are all trying to better understand AI progress and decide how much attention they should invest and where to direct it. Measurement efforts can help ground such decisions. If you’re interested in this type of work, consider applying to work at OpenAI’s Foresight or Policy team!
行业领袖、政策制定者、经济学家和潜在的研究人员都在努力更好地了解人工智能的发展,并决定他们应该投入多少注意力以及将其引导到何处。测量工作可以帮助做出这样的决定。如果你对这类工作感兴趣,可以考虑申请加入 OpenAI 的 Foresight 或 Policy 团队!
引用方法
请参考:
li,wanye. "AI与效率". wyli'Blog (Aug 2024). https://www.robotech.ink/index.php/archives/593.html
或BibTex方式引用:
@online{eaiStar-593,
title={AI与效率},
author={li,wanye},
year={2024},
month={Aug},
url="https://www.robotech.ink/index.php/archives/593.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接