漫谈YOLO系列算法的演进四
YOLOR与YOLOv4属于同一个研究团队发布的模型。该团队开发了一个多任务学习方式,以学习一个通用表示和利用子网络学习任务特定表示的方式创建一个适用于各种任务的模型。
YOLOX
YOLOX在YOLOv3基础之上改进的,主要的变化是:anchor-free架构、多正样本、解耦的头部、高级标签分配、以及稳健的数据增强。
- anchor-free:自YOLOv2之后,所有YOLO系列均是基于锚点的检测器。YOLOX受到一些无锚点的目标检测网络架构启发,例如:CornerNet、CenterNet、FCOS,回到了无锚点架构,从而简化了训练和解码过程。
- 多正样本:为了补偿锚点缺失,把中心$3\times 3$区域指定为正样本,这种方式被称为中心采样。
- 解耦的头部:为了解决分类置信度和定位精度不对齐的现象,YOLOX把Head分为两个部分,一部分用于分类任务,一部分用于回归任务,可见图1所示。
- 高级标签分配:若多个对象的box重叠,从而导致真实标签分配很模糊,YOLOX把标签分配问题看作最优传输问题,提出了simOTA。
- 增强版的数据增强:YOLOX利用MixUP与Mosaic增强作为数据增强。同时,发现这两种增强方式会导致ImageNet预训练失效,因此减少了预训练的步骤。
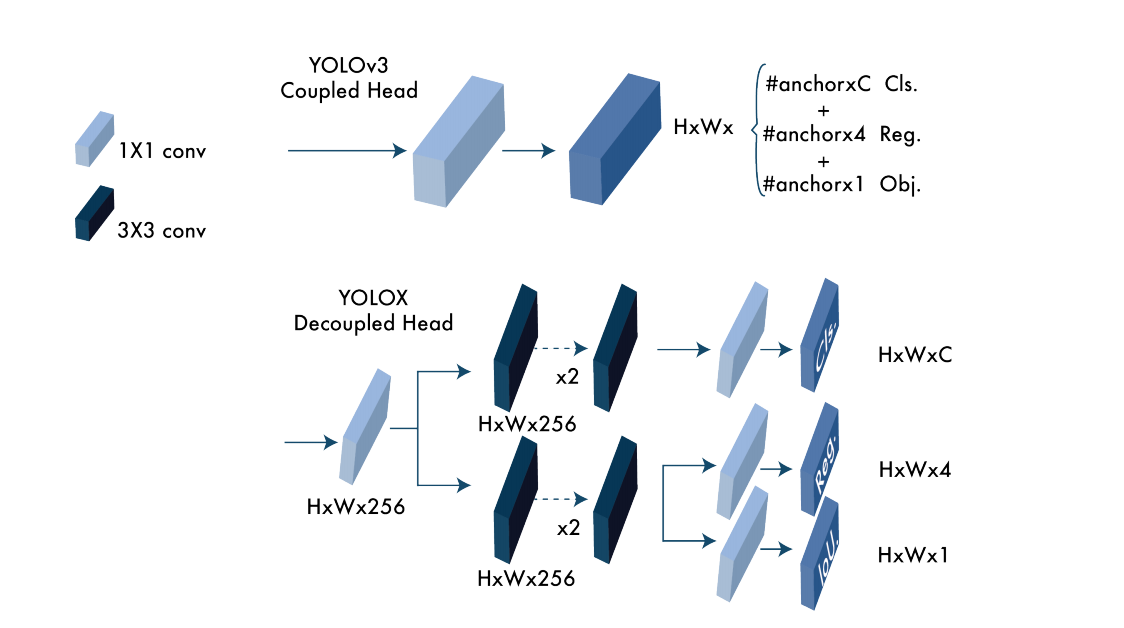
图1 YOLOv3与YOLOX之间Head的不同
YOLOv6
YOLOv6网络设计由RepVGG或CSPStackRep作为backbone,neck为PAN,和一个高效的解耦策略。除此之外,YOLOv6还引入了训练后量化和渠道级别蒸馏的量化技术,从而产生更快、更精确的检测器。如图2所示,YOLOv6的网络架构。
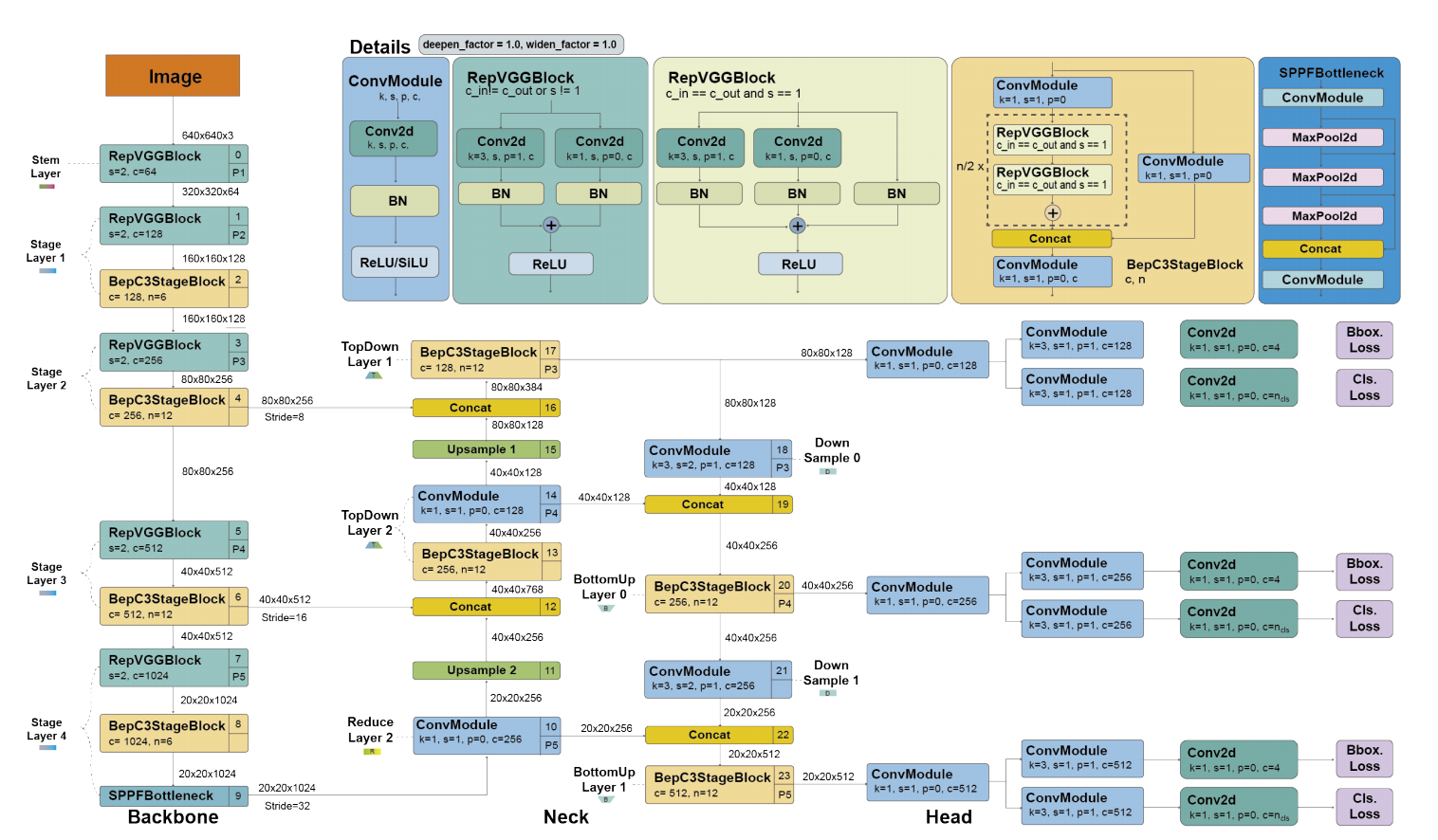
图2 YOLOv6网络架构
主要的贡献如下:
- 基于RepVGG的新backbone,与之前YOLO backbones相比,具有更高的并行度。对于neck部分,使用由RepBlocks或CSPStackRep块增强PAN。与YOLOX一致,开发了一个高效的解耦head。
- 利用TOOD中引入任务对齐学习方式的标签分配。
- VariFocal损失作为分类损失,SIoU或GIoU作为回归损失。
- 对于回归和分类任务的自蒸馏。
- 利用RepOptimizer和渠道级别蒸馏作为检测的量化技术。
同时,作者们提出了8个扩展的模型,以便于应用在各种设备上。
YOLOv7
YOLOv7与YOLOR、YOLOv4的是同一个作者提出,发布于2022年6月。在当时,在速度和精度上超过了所有检测器。与YOLOv4一样,也是利用MS COCO数据集训练,无预训练backbones。YOLOv7提出了一组架构的创新和一系列BoF,从而在不影响推理速度的情况下提高了精度,只是增加了训练时间。如图3所示,YOLOv7网络架构。
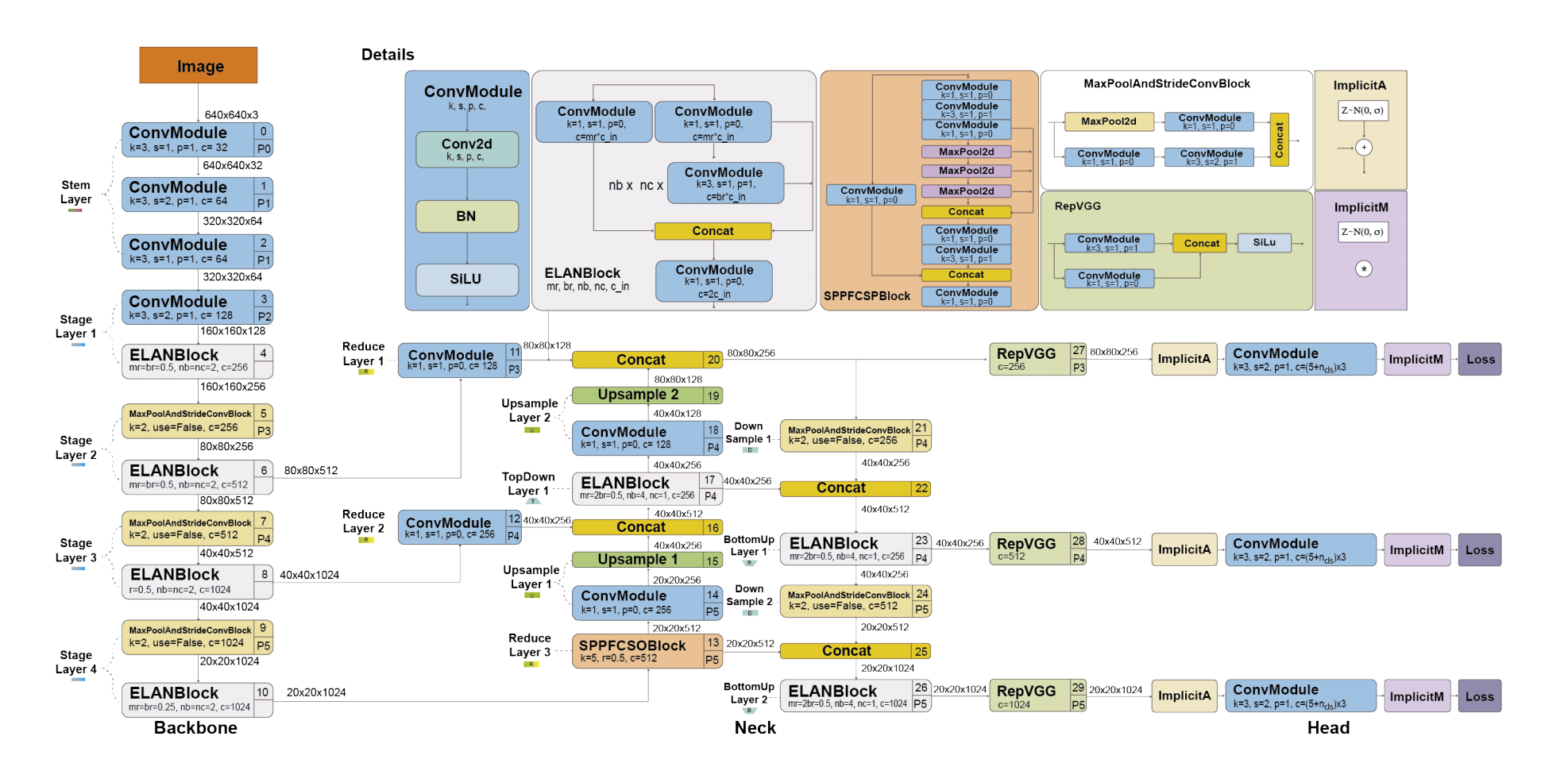
图3 YOLOv7网络架构
YOLOv7架构的改变如下:
- 扩展的高效层聚合网络(E-ELan)。ELAN是一个允许深度模型通过控制最短最长梯度路径而更高效的学习和拟合。YOLOV7使用的E-ELAN适用于无限堆叠的计算块模型。E-ELAN通过shuffling和merging方式组合特征提升模型学习,且不会破坏原始梯度路径。
- 基于concatenation模型的扩展。通过调整一些模型属性扩展生成不同sizes的模型。YOLOv7架构是一个基于concatenation的架构,其扩展技术,例如:深度扩展,可以引起过渡层的输入与输出比率发生变化,从而导致硬件使用的减少。YOLOv7提出了一个新的扩展基于concatenation模型的策略,该方式以同一比率扩展深度和宽度,同时维护最优模型结构。
YOLOv7中的BoF:
- 规划的重参数卷积。 与YOLOv6相似,YOLOv7也受到RepConv的启发。然而,作者们发现RepConv中identity connection会破坏ResNet中残差和DeseNet的concatenation。因此,移除了RepConv中identity connection。
- 辅助head的粗标签分配和lead head的精细标签分配。lead head负责最终的输出,辅助head帮助训练。
- conv-bn-activation中批次归一化。在推理阶段,把批次归一化的均值和方差整合到卷积层的偏差和权重中。
- YOLOR中的隐知识。
- 指数移动平均作为最终推理的模型。
YOLOv7与YOLOv4和YOLOR的对比
与YOLOv4相比,YOLOv7在参数量减少了75%,在计算量上降低了36%,同时提升平均精度1.5%。
与YOLOv4-tiny相比,YOLOv7-tiny参数量降低了39%,计算量降低了49%,同时维持了相同平均精度。
最后,与YOLOR相比,YOLOv7参数量降低了43%,计算量降低了15%,平均精度提高了0.4%。
参考文献
版权: 本篇博文采用《CC BY-NC-ND 4.0》,转载必须注明作者和本文链接