分布式RL:训练框架
面对复杂任务时,RL算法需要与环境交互生成大量的数据用于学习,才能实现期望的性能。对于大量数据需求的挑战,有两种应对方法,分别是分布式训练和提升样本效率。其中,分布式训练是指智能体与数千个仿真环境交互以生成训练数据;样本效率提升的主要目的是提高利用有限数据的能力。基于此,本文尝试回答以下问题
- 分布式训练框架是怎样的呢?
- 分布式训练在连续控制领域的应用是怎样的呢?
分布式训练
在扩展形式角度上,分布式训练有两种方式,一种是扩展到集群中数千台机器,另一种是在一台GPU服务器上创建数千个并行仿真环境。其中,扩展到数千台机器的典型工作有《Distributed Prioritized Experience Replay》的Ape-X分布式框架;引入off-policy纠正范式的IMPALA算法,用于缓解分布式on-policy中actors与learners之间滞后的问题。在扩展目的上,分布式可分为数据收集和梯度收集,例如:Ape-X扩展目的是收集数据,A3C扩展目的是收集梯度。
在连续控制领域的应用状况
在连续控制领域,在一台GPU服务器创建数千个仿真环境,通常基于PPO算法训练模型。之所以采用PPO算法,这是因为其拥有简单性和易扩展性的特点。
在笔者的实践经验中,发现,虽然扩展数千个仿真环境提高了数据收集能力,但是每个智能体的探索能力是一致的,收集到的数据偏向于同质化。同时,PPO属于on-policy的算法,其样本效率不高。由此,通常需要复杂的超参数调节、环境设计、以及MDP设计,才能实现较强的性能。对于机器人控制任务来说,RL的超参数不仅包含算法本身的参数,还包含环境的超参数,多达数百,这是很费时费力的。
相关分布式训练框架
简单介绍一下Ape-X和PQL分布式训练框架,IMPALA训练框架之前已经介绍过。
Ape-X
简单来说,Ape-X框架是分布式的收集数据,通过一个共享的actor网络与环境交互收集数据和一个共享的经验回放实现分布式。如图1所示,Ape-X原理图。其中,经验回放是优先级经验回放,可用的优先级评价方式为:TD-Error$\vert\delta_i\vert$和TD-Error与随机优先级的结合$P(i)=\frac{p_i^{\alpha}}{\sum_kp_k^{\alpha}},p_i=\vert\delta_i\vert+\epsilon$。
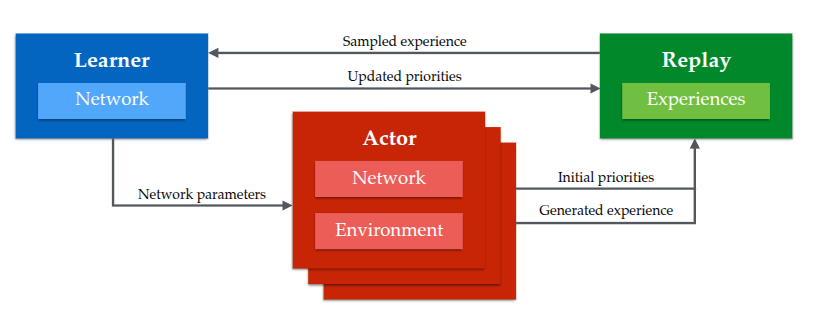
图1 Ape-X原理图
其中,TD-Error与随机优先级结合的原因是:只利用TD-error是一种贪心的选择,会造成尾部样本很少访问到,容易过拟合。其中,$\alpha$控制随机与贪心之间的平衡,其值为1时属于均匀优先级。
最后,为了弥补优先级回放带来的偏差,对Q-learning的更新$\delta_i$进行了加权,权重系数为$w_i=(\frac{1}{N}\cdot\frac{1}{P(i)})^{\beta}$。若$\beta\to1$,那么对偏差的纠正能力越强。若$\beta,\alpha$同时接近于$1$,不仅更加激进的优先采样且更强的纠正。在实验中,作者们对$\beta$采用线性衰退的方式调度。
PQL
在一个actor-critic Q-Learning方法中,由策略函数、Q价值函数、以及环境构成。从智能体与环境交互收集数据,到价值函数更新,最后到策略网络更新,三者串行进行。为了最大化学习速度和减少等待时间,作者们并行化三个元件的计算,因此采用了off-policy范式的RL,即PQL是一个并行化的off-policy训练范式。在实践中,作者们利用了DDPG。如图2所示,在PQL中并行化数据收集为Actor、并行化策略学习为P-learner、以及并行化价值学习为V-learner。
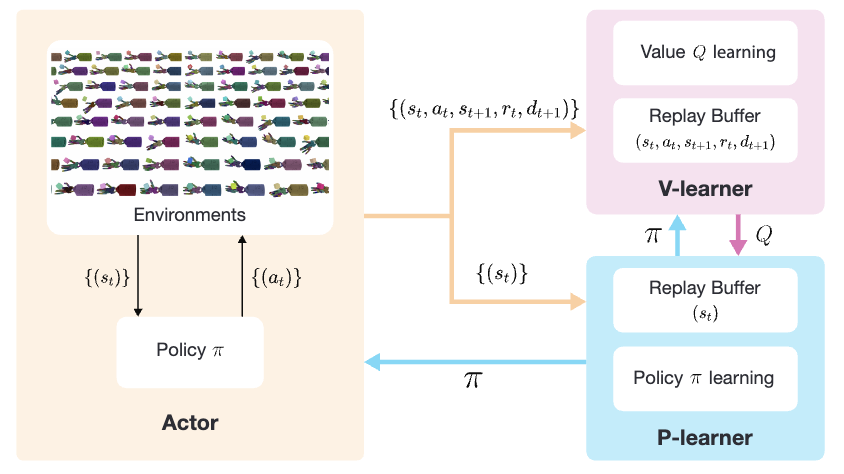
图2 PQL原理图
- 对于Actor进程,智能体按照一个探索策略与数千个环境交互,因此维护了一个与P-learner中策略网络$\pi^{p}(s_t)$周期性同步的局部策略网络$\pi^{a}(s_t)$。
- 对于V-learner,作者们创建了一个训练价值函数的专用进程,从而实现连续更新。为了减少策略和数据的跨进程通信,维护了一个局部的策略网络和replay-buffer。其中,策略网络也周期的与P-learner同步。
- 与V-learner方式相似,P-learner也维护了一个局部replay-buffer和一个周期性更新的价值函数。
- 对于数据迁移,若有$N$个并行环境,那么Actor执行策略生成N对$(s_t,a_t,s_t,r_t,d_{t+1})$交互数据。然后,发送一个batch的交互数据到V-learner,对于P-learner只发送状态$\{(s_t)\}$序列。
- 对于网络迁移,V-learner周期性的发送价值函数参数到P-learner,而P-learner周期性的发送策略网络到Actor和V-learner。
平衡机制
若每个进程彼此独立地尽可能快的运行,那么可能导致训练的不稳定,因此通过如下两个比率控制更新频率:
$$ \begin{aligned} \beta_{a:v}:=\frac{f_a}{f_v}~and~\beta_{p:v}:=\frac{f_p}{f_v} \end{aligned} $$
式中$f_a$表示每个单位时间Actor与每个环境交互的步数,$f_v$为每个单位时间V-learner中$Q$函数的更新步数,$f_p$为每个单位时间策略网络的更新步数。这两个比率有利于控制每个进程的资源分配和减少PQL的表现方差,$\beta_{p:v}$与TD3中策略网络更新频率慢于价值网络的理论相一致。
混合探索
许多探索策略无法使智能体快速的学习到较优性能的策略,为了提升样本多样性,作者们对DDPG的探索策略进行了扩展。DDPG中通过设置不相关和零均值标准差$\sigma$的高斯噪音到策略输出,即$(a_t=max(min(\pi(s_t)+\mathcal{N}(0,\sigma)a_u),a_l),a_t\in[a_l,a_u])$。由于很难确定较合适的探索噪音,因此作者们每个环境设置一个$\sigma$。确切的说,$i^{th}$环境的高斯噪音级别从$[\sigma_{min},\sigma_{max}]$中均匀采样,即$\sigma_i=\sigma_{min}+\frac{i-1}{N-1}(\sigma_{max}-\sigma_{min})$
综上所述,与Ape-X相比,PQL的优势为:
- 专门设计为单台机器的GPU上进行大规模并行仿真训练。
- 解耦合和并行化策略学习与Q函数学习。
- 每个leearner分配一个局部replay buffer
- 设计了一个在单台机器上平衡不同并行进行计算资源的机制。
最终,实验表明PQL不仅训练速度快,且性能优越。
引用方法
请参考:
li,wanye. "分布式RL:训练框架". wyli'Blog (Feb 2025). https://www.robotech.ink/index.php/archives/711.html
或BibTex方式引用:
@online{eaiStar-711,
title={分布式RL:训练框架},
author={li,wanye},
year={2025},
month={Feb},
url="https://www.robotech.ink/index.php/archives/711.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接