LLaMA:开放且高效的基础语言模型
LLaMA是一系列开源的基础语言模型,模型大小从7B到65B。其中,13B参数的LLaMA性能优越于175B参数的GPT3,65B参数量的LLaMA与Chinchilla-70B和PaLM-540B的模型性能一致。语言模型扩展到足够的尺寸,可拥有少样本泛化的能力。然而,Hoffmann等人表明:在给定计算资源下,最优的性能不是最大的模型实现的,而是小模型在大量数据上训练实现的。经过实验发现,模型的大小与tokens的数量应该同比例的扩展,才能使模型的性能发挥到极致。然而,Hoffmann等人研究没有考虑推理成本,只考虑了训练成本。由此,LLaMA作者们希望能够在各种各样推理预算下能够训练出最优性能的模型。
预训练数据
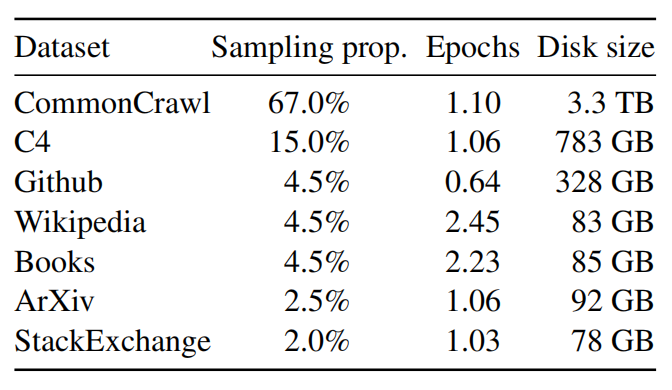
图1 预训练数据
在模型训练方法上,LLaMA与GPT3、GPT-NeoX一致。对于tokenizer,作者们利用了Sentence-Piece的BPE算法。
架构
在Transformer基础之上,根据GPT3、PaLMHE GPTNeo的工作进行了优化。
- 与GPT3一致,对transformer的每个子层的输入进行了标准化,不再对输出进行标准化。其中,标准化函数为RMSNorm。
- 与PaLM一致,利用SwiGLU激活函数代替ReLU激活函数。同时,也利用$\frac{2}{3}4d$代替$4d$
- 与GPTNeo,利用RoPE作为位置编码。
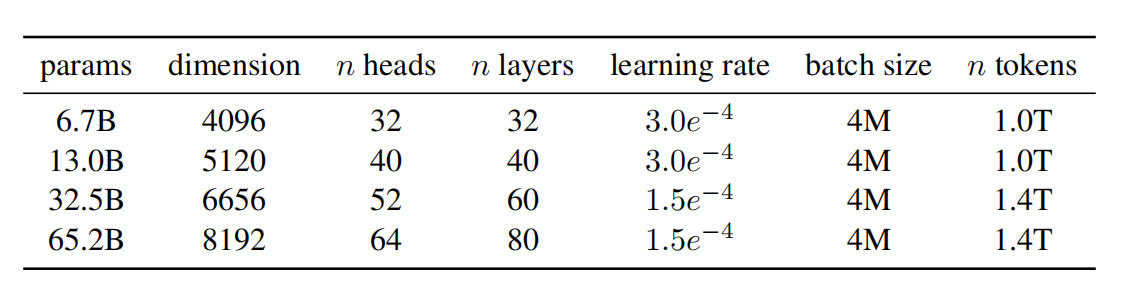
图2 模型相关的超参数
模型训练时,优化器为AdamW,其超参数可见图2所示。同时,学习率的调度为余弦调度,以便于最终学习率为最大学习率的10%。权重衰减系数为0.1,梯度裁剪1.0,warmup步数为2000。
高效的实现
为了提高模型训练速度,进行了如下优化:
- 受到Rabe等人启发,对多头注意力进行了高效的实现,形成了xformers。其中,backward方法来自于FlashAttention。
- 受到Korthikanti等人的启发,减少了激活重复计算。
相关思考
LLaMA架构综合了各种Transformer设计优化,这些优化方法在其它大模型中也都能看到其身影,值得一读。
引用方法
请参考:
li,wanye. "LLaMA:开放且高效的基础语言模型". wyli'Blog (Mar 2024). https://www.robotech.ink/index.php/archives/338.html
或BibTex方式引用:
@online{eaiStar-338,
title={LLaMA:开放且高效的基础语言模型},
author={li,wanye},
year={2024},
month={Mar},
url="https://www.robotech.ink/index.php/archives/338.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接