MobileVLM V2:视觉语言模型进阶
MobileVLM-v2的主要贡献,如下:
- 设计了可利用高质量多模态数据潜力的训练方法。
- 提出了一个非常轻量级的投射器,不仅显著减少了视觉tokens的数量,而且性能几乎不变。
在许多视觉语言benchmark实现了表现与推理速度新的SOTA。
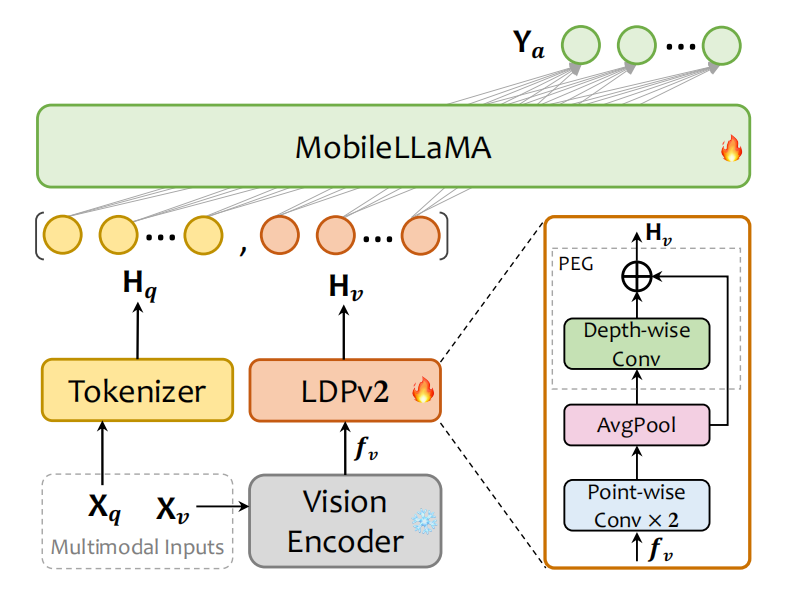
图1 MobileVLM-v2架构
视觉编码器
视觉编码器的主要作用是抽取视觉特征。在MobileVLM v2中,利用CLIP中ViT-L/14作为视觉编码器$\mathbf{F}_{enc}$。
语言模型
与MobileVLM一致,利用MobileLLaMA作为大语言模型,这样的设计好处是:
- MobileLLaMA的设计有利于部署,且在边缘设备上实时推理速度较高。
- 保持大语言模型不变,有利于研究数据量、训练策略、以及投射器的设计对性能的影响。
- MobileLLaMA拥有与LLaMA2一致的tokenizer,有助于模型蒸馏。
- 模型是基于开源数据训练,有助于确定模型是否比之前的模型性能优越,而不是因为数据泄露造成的。
轻量级下采样投射器
如图1所示,投射器LDPv2由特征变形、token缩减、以及位置信息增强构成。首先,利用两层point-wise卷积把视觉embedding的维度与LLM的特征维度相比配;接下来,利用平均池化层压缩视觉tokens的数量;最后,利用PEG和skip connection增强位置信息。与MobileVLM中LDP相比,减少了99.8%的参数量,且拥有更快的推理速度。
训练策略
大部分视觉-语言模型的训练是:freeze视觉编码器和语言模型,只训练视觉特征与语言特征对齐的模块。其中,MobileVLM的视觉-语言模型训练方式是先只训练投射器,然后微调投射器和LLM。
确切的说,MobileVLM-V2的视觉编码器利用CLIP的ViT-L/14初始化,语言模型利用MobileLLaMA初始化。在预训练阶段freezing视觉编码器,训练投射器和LLM,从而使模型能够更好的以视觉信息为条件学习文本的生成。经过图片-文本对齐预训练之后,模型拥有了理解视觉内容的能力。然而,对于下游任务,它缺乏利用视觉分析和对话的能力。由此,引入多任务训练,从而使模型能够拥有多任务分析和图文转换的能力。
相关思考
与MobileVLM相比,MobileVLM v2拥有更轻量级的下采样投射器,且进行了数据优化与多任务训练。
引用方法
请参考:
li,wanye. "MobileVLM V2:视觉语言模型进阶". wyli'Blog (Mar 2024). https://www.robotech.ink/index.php/archives/335.html
或BibTex方式引用:
@online{eaiStar-335,
title={MobileVLM V2:视觉语言模型进阶},
author={li,wanye},
year={2024},
month={Mar},
url="https://www.robotech.ink/index.php/archives/335.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接