DP3:3D扩散策略
扩散策略算法需要大量的演示数据才能实现较强的泛化性。然而,模仿学习算法收集任务相关的数据耗时很长。为了应对该挑战,DP3把3D视觉表示与扩散策略相整合。这种整合不仅利用了3D模态的空间理解能力,也利用扩散模型的表达能力。DP3展现出的性能:
- 有效性和高效性:DP3不仅实现了优越的精度,而且明显需要更少的演示数据和更少的训练步骤。
- 泛化性:DP3的3D特质有助于各个方面的泛化能力。
安全性:与baseline算法相比,DP3在真实世界任务中能够遵守安全约束。
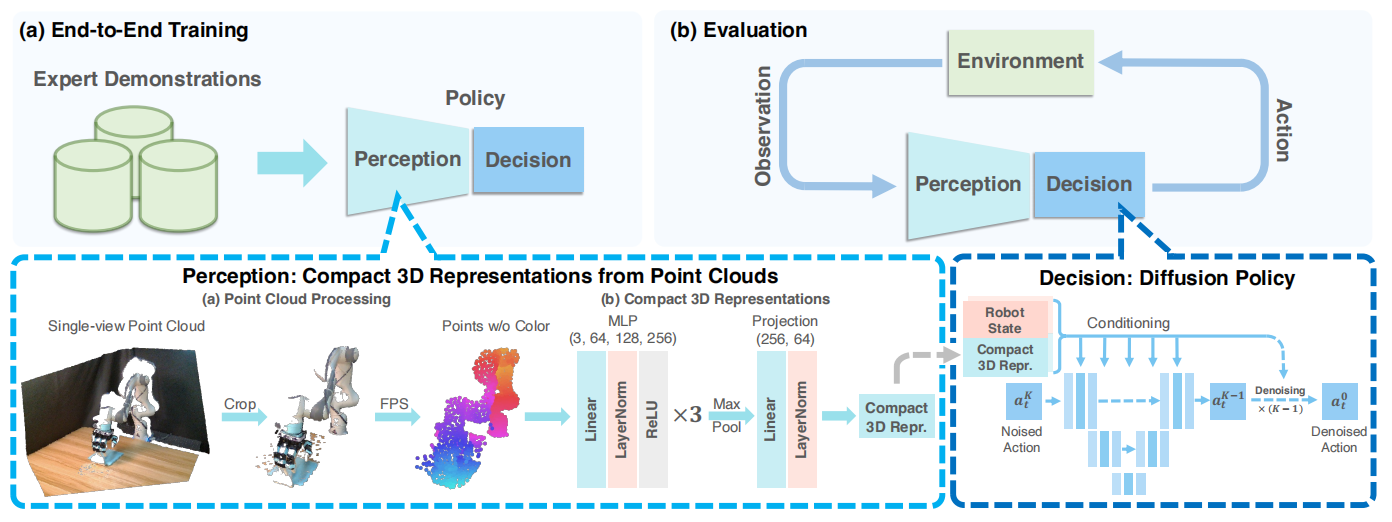
图1 DP3概览
算法设计
3D扩散策略由两个部分构成,分别是感知模块和决策模块,可见图1所示。其中,感知模块中DP3利用点云数据感知环境,且利用高效点云编码器处理视觉观测获得视觉特征;决策模块中DP3利用扩撒策略作为生成动作网络的backbone。
感知
3D场景的视觉数据可利用不同的方式表示,例如:RGB-D、点云、voxels、隐函数、以及3D高斯。相较于其它方法,点云是最高效的表示方式。基于相机内参与外参把深度图像转换为点云,去除掉与被操纵对象无关的冗余点云。接下来,利用FPS算法对点云数据进行降采样,该采样方法能够有助于覆盖3D空间和减少点云采样的随机性。
如图2所示,点云数据的编码网络为三层MLP、最大池化层、以及映射头构成。为了保持训练的稳定性,网络层之间交织着LayerNorm。经过实验,发现,这种简单的编码器性能优越于预训练点云编码器PointNeXt。
决策
DP3的决策模块被阐述为条件去噪扩撒模型,条件为3D视觉特征$v$和机器人位姿$q$。确切的说,从一个高斯噪音$a^K$开始,去噪网络$\mathbf{\epsilon}_{\theta}$执行$K$次迭代把随机噪音$a^K$变为$a^0$,可见式(1)
$$ \begin{aligned} a^{k-1}=\alpha_k(a^k-\gamma_k\mathbf{\epsilon}_{\theta}(a^k,k,v,q))+\sigma_k\mathcal{N}(0,\mathbf{I}) \end{aligned}\tag{1} $$
式(1)中$\alpha_k,\gamma_k,\sigma_k$为$k$的函数,取决于噪音调度器。
为了训练去噪网络$\mathbf{\epsilon}_{\theta}$,从数据集中随机噪音数据点$a^0$,执行扩散过程,在第$k$步获取噪音$\epsilon_k$,模型训练的目标函数为
$$ \begin{aligned} \mathcal{L}=MSE(\epsilon^k,\epsilon_{\theta}(\bar{\alpha}_ka^0+\bar{\beta}_k\epsilon^k,k,v,q)) \end{aligned}\tag{2} $$
实现细节:利用基于卷积神经网络的扩散策略和DDIM的噪音调度器。为了更好的生成高维动作,直接预测动作而不是噪音。在训练阶段,扩散的时间步为100;在推理阶段,扩散的时间步为10。在batch size为128情况下,训练3000epochs。
相关思考
总的来说,DP3就是3D视觉特征与扩散策略的结合,模型拥有有效性和高效性、较强的泛化性、以及生成安全性动作的能力。
引用方法
请参考:
li,wanye. "DP3:3D扩散策略". wyli'Blog (Mar 2024). https://www.robotech.ink/index.php/archives/352.html
或BibTex方式引用:
@online{eaiStar-352,
title={DP3:3D扩散策略},
author={li,wanye},
year={2024},
month={Mar},
url="https://www.robotech.ink/index.php/archives/352.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接