LL3DA:Omini-3D理解-推理-规划的视觉交互指令微调
在LL3DA之前,3D视觉-语言多模态工作主要把2D视觉特征投射到3D空间,作为3D场景的表示,例如:3D-LLM。然而,这种方式需要大量的计算资源。与之不同,LL3DA以3D点云数据为输入,对文本指令和视觉提示进行响应。这种设计不仅能够处理置换不变3D场景embeddings与LLM的embeddings空间的矛盾,也能够抽取交互意识的3D场景embedding,用于高效指令跟随。
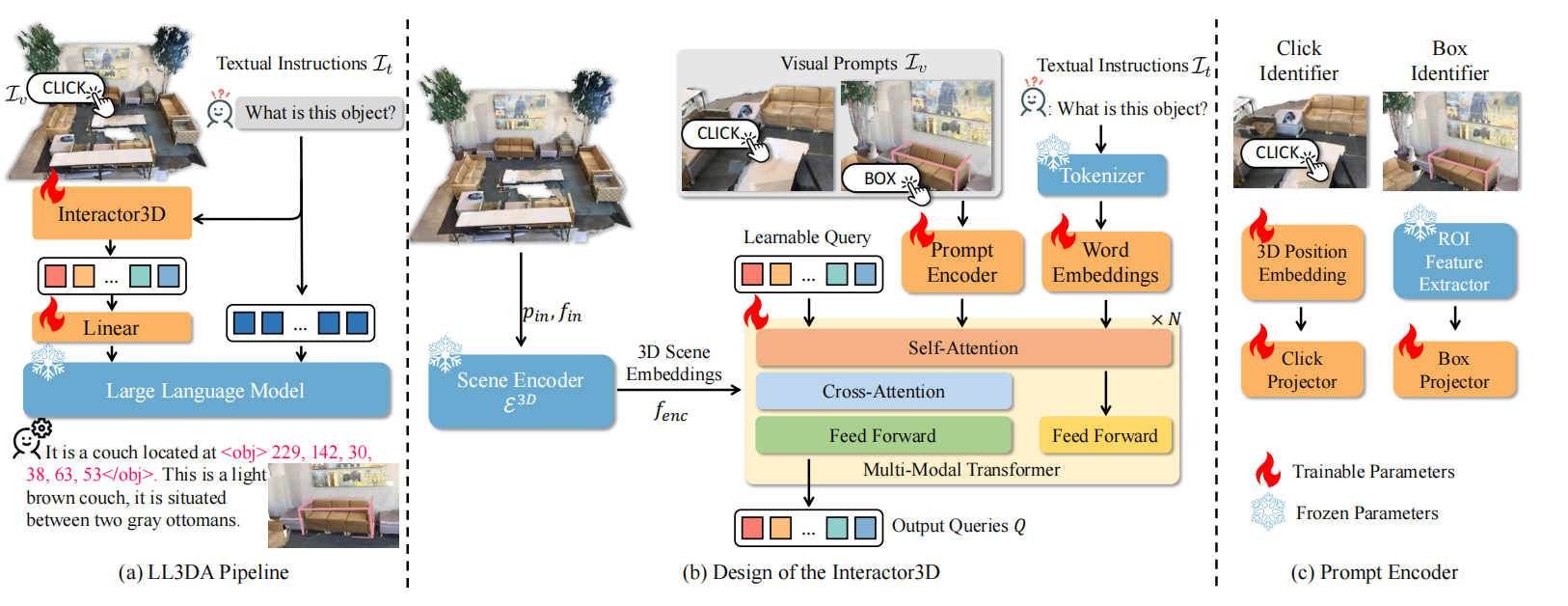
图1 LL3DA概览
问题格式
模型的输入输出:如图1.a所示,模型的输入由点云$PC$、文本指令$\mathcal{I}_t$,以及潜在视觉交互$\mathcal{I}_v$。点云$PC=[p_{in},f_{in}]\in\mathbb{R}^{N\times(3+F)}$,$p_{in}\in\mathbb{R}^{N\times 3}$和$f_{in}\in\mathbb{R}^{N\times F}$分别为点的坐标和辅助特征,主要由颜色、normal和高度构成。模型的输出为自然语言,且部分语言可被翻译成3D坐标。
指令格式:文本指令$\mathcal{I}_t$以"### human:"为标识符,模型的响应以"### assistant:"为标识符。这种方式可以赋予模型识别上下文信息的能力,从而执行多轮对话。
坐标表示:为了使LLM能够感知和响应3D坐标,把3D点和3D有界boxes转换为文本。确切来说,空间点被表示为"
模型设计
如图1.a所示,模型通过Interactor3D从视觉提示、文本指令、以及3D场景中抽取场景embeddings。然后,场景embeddings被投射为文本指令的前缀,作为LLM的输入。如图1.b所示,Interactor3D由3D场景编码器$\varepsilon^{3D}$、视觉提示编码器、以及Q-Former构成。
场景编码器:利用在ScanNet检测中预训练的掩码transformer的编码器作为$\varepsilon^{3D}$,其中输入为$PC$,输出为3D的embeddings,可见式(1)
$$ \begin{aligned} f_{enc}=\varepsilon^{3D}(PC)=\varepsilon^{3D}(p_{in};f_{in})\in\mathbb{R}^{M\times d} \end{aligned}\tag{1} $$
式(1)中$f_{enc}$由基于FPS算法采样的$M$个点的$d$维特征构成。在训练阶段,场景编码器的权重被forzen,不参与训练。
视觉提示编码器:作者们只考虑两种常见的视觉交互,分别为用户点击和3Dbox注释。每个用户的点击被输入的3D场景大小标准化到$[0,1]$,再被3D傅立叶位置编码函数编码为:
$$ \begin{aligned} pos(p_{click}=[sim(2\pi p_{click}\cdot B);cos(2\pi p_{click}\cdot B)]) \end{aligned}\tag{2} $$
式(2)中$B\in\mathbb{R}^{3\times(d/2)}$为可学习的矩阵。
box注释被预训练的3D目标检测器抽取的ROI特征$f_{box}\in\mathbb{R}^d$所表示。最终,用户点击特征和box注释特征被全链接神经网络分别投射
$$ \begin{aligned} & f_{click}=FFN_{click}(pos(p_{click})) \\ & f_{box}=FFN_{box}(f_{box}) \end{aligned}\tag{3} $$
在实践中,每个视觉提示利用8个tokens表示。
多模态Transformer:该模块的主要承担的角色分别是:
- 处理置换不变3D场景编码与位置敏感的因果LLM直接的矛盾。
- 弥补单模态专家模型之间的间隔。
这一模块主要是基于BLIP-2中Q-Former的思想,抽取查询编码$Q\in\mathbb{R}^{32\times768}$,再基于简单的线性投射器投射到LLM的embedding空间。其中,Q-Former只是利用BERT初始化了word和位置的embeddings。
LLM:大语言模型就是基于Transformer解码器的生成模型LaMMA2或OPT。模型训练阶段,该模块被frozen。
多模态指令微调
基于3D-DC和3D-QA任务的数据集对模型进行训练,其目标函数为最大化目标响应序列$s$的似然:
$$ \begin{aligned} {\theta}^{*}=\underset{\theta}{argmax}P(s\vert PC;\mathcal{I}_v;\mathcal{I}_t;\theta) \end{aligned}\tag{4} $$
在实践中,以PC、$\mathcal{I}_v$、$\mathcal{I}_t$、历史$(i-1)$个tokens$s_{[1,\ldots,i-1]}$为输入,交叉熵为损失函数预测第$i$个token$s_{[i]}$
$$ \begin{aligned} \mathcal{L}(\theta)=-\sum_{i=1}^{|s|}logP(s_{[i]}\vert PC;\mathcal{I}_v;\mathcal{I}_t;\theta;s_{[1,\ldots,i-1]}) \end{aligned}\tag{5} $$
相关思考
LL3DA借鉴了BLIP-2中Q-Former的视觉特征抽取方法,把其扩展到了3D场景,从而提高了模型处理三维视觉的能力。三维视觉特征抽取之后,与视觉-语言多模态大模型的训练和架构几乎一致。
引用方法
请参考:
li,wanye. "LL3DA:Omini-3D理解-推理-规划的视觉交互指令微调". wyli'Blog (Mar 2024). https://www.robotech.ink/index.php/archives/354.html
或BibTex方式引用:
@online{eaiStar-354,
title={LL3DA:Omini-3D理解-推理-规划的视觉交互指令微调},
author={li,wanye},
year={2024},
month={Mar},
url="https://www.robotech.ink/index.php/archives/354.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接