F3RM:在复杂3D环境中实现Robot操作的方法
一个仓库机器人从杂乱的储物箱中分拣物品从而完成订单任务,这不仅仅需要拥有视觉和语言的语义理解能力从而识别正确的物品,也需要理解物品的几何形状的能力从而稳定的抓取物品。F3RM作者以机器人能够根据少量抓取演示或文本描述从而抓取新物品为研究目标,构建了一个预训练视觉embedding为基础的系统,可见图1所示。
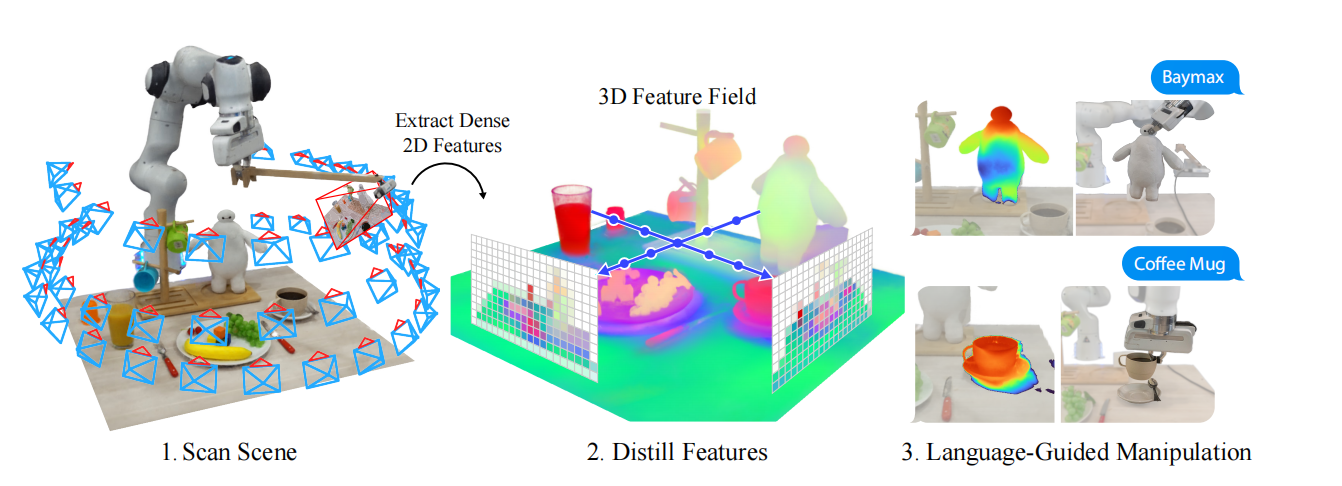
图1 F3RM工作的步骤
首先,F3RM智能体基于RGB相机扫描桌面获取一些列图片。然后,这些图片拥有构建桌面的神经辐射场(NeRF),从而产生了场景描述,被称为Distilled Feature Field(DFF),拥有把2D特征地图映射到3D空间。最后,机器人根据参考演示和语言指令抓取用户指定的物品。
为了应对特征提取耗时较长的问题,F3RM利用了NeRF中层级哈希网格。其中,层级哈希网格技术有:pixelNeRF和Nerfstudio。对于视觉-语言模型,CLIP产生图片级别的特征,而3D特征抽取需要稠密2D描述,作者们利用MaskCLIP中重参数化技巧解决该问题。
Feature Field Distillation
DDF是NeRF的扩展版,重构的不是像素值,而是来自于视觉编码器$\mathbf{f}_{vis}$的2D特征地图。与NeRF不同,特征域是一个把3D坐标$\mathbf{x}$映射为特征向量$\mathbf{f}(\mathbf{x})$的函数,即函数$\mathbf{f}$不依赖于相机的视角方向$\mathbf{d}$。那么,特征向量为
$$ \begin{aligned} \mathbf{F}(\mathbf{r})=\int_{t_n}^{t_f}T(t)\sigma(\mathbf{r}_t)\mathbf{f}(\mathbf{r}_t)dt\qquad with\qquad T(t)=exp(-\int_{t_n}^t\sigma(\mathbf{r}_s)ds) \end{aligned}\tag{1} $$
式(1)中$\mathbf{r}$为相机射线对应于一个特定像素,$t$为射线距离,$\sigma$为NeRF的密度函数,$T(t)$为累积透明度。
那么,对于2D特征地图集合$\{\mathbf{I}^f_i\}_{i=1}^N$,特征蒸馏的目标函数为
$$ \begin{aligned} \mathcal{L}_{feat}=\sum_{\mathbf{r}\in\mathcal{R}}\Vert\hat{\mathbf{F}}(\mathbf{r})-\mathbf{I}^{f}(\mathbf{r})\Vert_2^2 \end{aligned}\tag{2} $$
式(2)中$\mathbf{I}^f=\mathbf{f}_{vis}(\mathbf{I})$,$\mathbf{I}$表示RGB图片。
确切的说,$\mathbf{I}^f$来自于CLIP。其中,CLIP中利用了MaskCLIP的重参数技巧,也利用插值位置编码以容纳更大的图片,从而允许抽取稠密、高分辨率patch级别的2D特征。这种特征蒸馏方法可把三维坐标转化为语义向量,即把三维空间结构与语义向量对齐。
利用特征域表示6自由度位姿
如图2.a所示,为了构建夹抓位姿,作者们对每个任务$M$基于3D高斯采样$N_q$个查询点$\mathcal{X}=\{\mathbf{x}\in\mathbb{R}^3\}_{N_q}$。其中,3D高斯的均值和方差手动调整从而使其能够覆盖目标对象的一部分、重要的相关环境部分、以及free空间。每个采样点对应特征域中的一个特征向量。为了考虑采样点在局部空间中的占用度量,作者们通过NeRF中密度函数得到权重$\alpha$,从而对特征向量进行加权,可见式(3)
$$ \begin{aligned} \mathbf{f}_{\alpha}(\mathbf{x})=\alpha(\mathbf{x}),where\quad \alpha(\mathbf{x})=1-exp(-\sigma(\mathbf{x})\cdot\delta)\in(0,1) \end{aligned}\tag{3} $$
式(3)中$\delta$为相邻样本之间的距离。
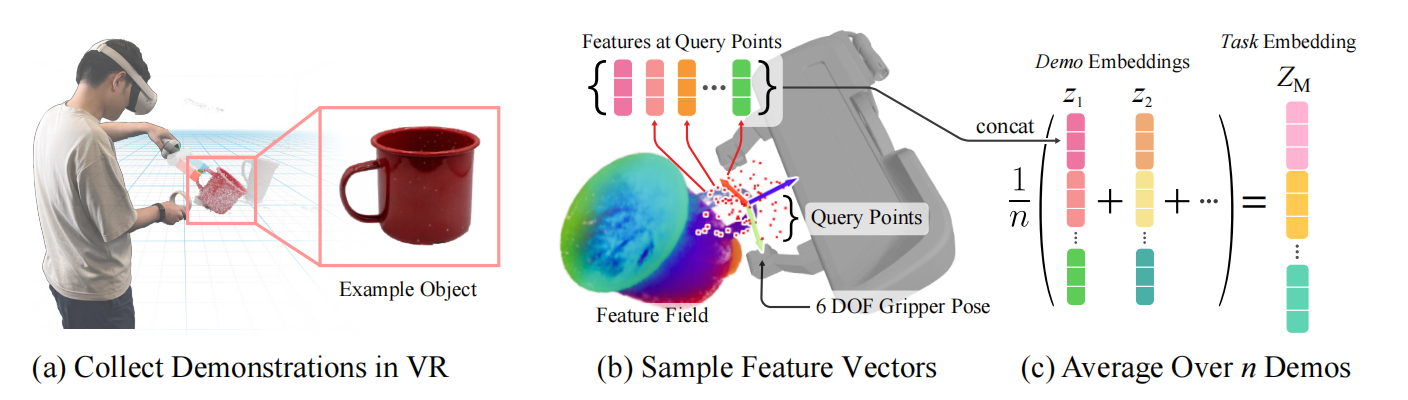
图2 六自由度位姿的表示
由此,采样的查询点对应的特征构成集合$\{\mathbf{f}_{\alpha}(\mathbf{x})\vert\mathbf{x}\in\mathbf{T}\mathcal{X}\}$,集合中所有向量按特征维度进行concat,形成一个向量$\mathbf{z}_{\mathbf{T}}\in\mathbb{R}^{N_q\cdot\vert f\vert}$。最终,查询点$\mathcal{X}$与与embedding $\mathbf{z_T}$构成位姿$\mathbf{T}$的编码。如图2.c所示,任务的embedding为演示数据中所有位姿编码$\mathbf{z_T}$的平均值。
位姿的推断: 首先,从工作空间中采样一个稠密的voxel网格,网格之间的距离为$\delta$。对于voxel网络,根据$\alpha(\mathbf{v})\lt\epsilon_{free}$移除free空间;根据voxel特征$\mathbf{f}_{\alpha}(\mathbf{v})$与任务编码$\mathbf{Z}_{M}$之间的余弦相似度,一处任务不相关的voxels。为了得到完整的位姿$\mathcal{T}=\{T\}$,对剩下的每个voxel采样$N_r$个旋向。接下来,就是位姿优化。
位姿优化: 基于成本函数优化初始位姿,可见式(4)所示
$$ \begin{aligned} \mathcal{J}_{pose}(\mathbf{T})=-cos(\mathbf{z_T},\mathbf{Z}_{M}) \end{aligned}\tag{4} $$
作者们利用Adam优化器选择与任务相似度最高的位姿。在每个优化步骤中,会裁剪掉成本最高的位姿;还会根据夹抓voxel与场景voxel之间的重叠程度过滤掉部分位姿,从而避免碰撞。最后,会得到一个排序的位姿列表,选择序列位置最高的位姿执行。
开放文本语言引导的操作
如图3所示,基于语言引导的操纵分为两大步,第一步寻找与语言编码最相近的两个演示,每个演示的embedding为所有采样点特征的平均值;第二步是位姿推断。由于笔者认为该技术过于繁杂且不实用,所以就不过多的介绍了。
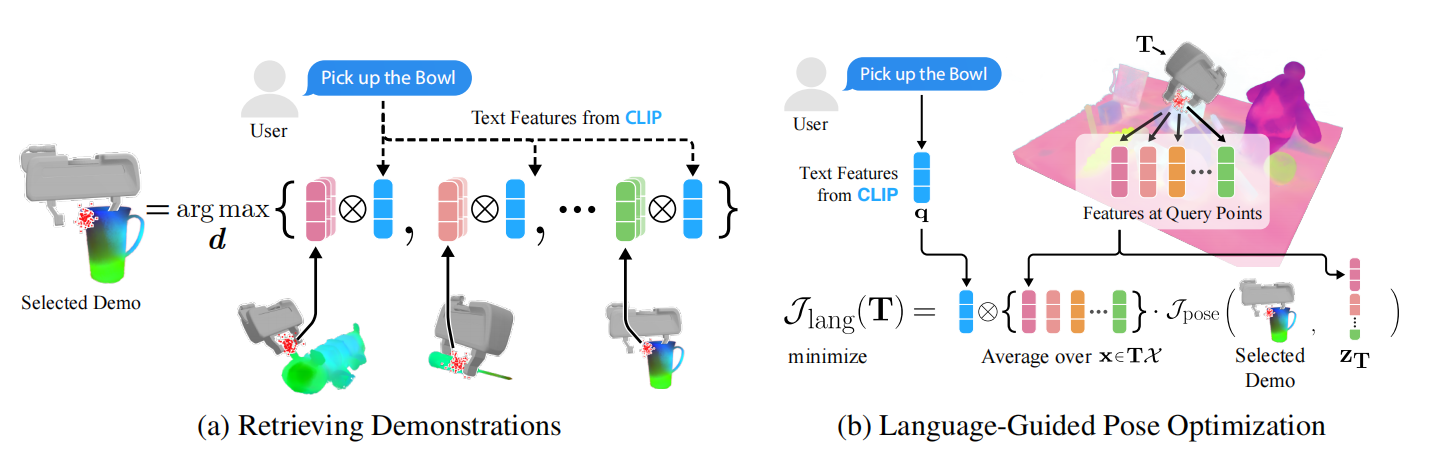
图3 语言引导操纵的流程
相关思考
相较于具身智能,基于3D视觉的操作到来的时间更短。F3RM的方式相对玄幻,需要把位姿$\mathbf{T}$与嵌入到embedding空间,这种方式的泛化性有很大的质疑。这种方式很复杂,很多技术细节也没有搞懂。
引用方法
请参考:
li,wanye. "F3RM:在复杂3D环境中实现Robot操作的方法". wyli'Blog (Mar 2024). https://www.robotech.ink/index.php/archives/348.html
或BibTex方式引用:
@online{eaiStar-348,
title={F3RM:在复杂3D环境中实现Robot操作的方法},
author={li,wanye},
year={2024},
month={Mar},
url="https://www.robotech.ink/index.php/archives/348.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接