R-CNN系列算法的演进
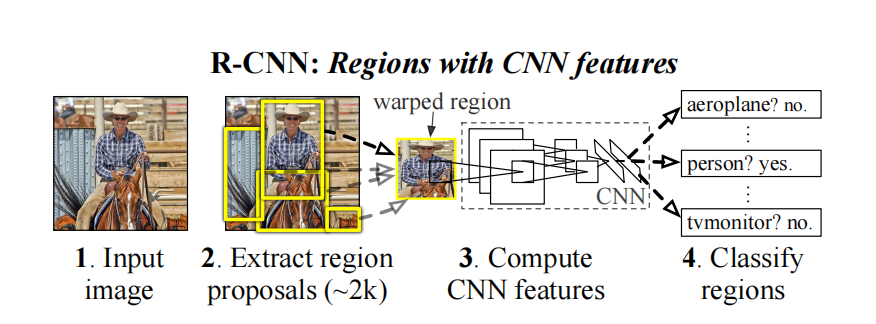
R-CNN是第一篇把CNN用于目标检测的算法。在把CNN用于目标检测时,有两大问题需要解决,分别是利用深度网络定位目标和利用少量的标注数据训练高容量模型。
对于目标定位,若把定位问题当作回归问题来处理,有研究结果表明基于DNN方式的效果并不好;若采用滑动窗口的方式,探测器很难处理不同尺寸的对象。
因此,R-CNN没有利用CNN定位对象,只是利用CNN算法提取特征。该算法主要分为四步,分别是:
- 利用Selective Search方法提出感兴趣的region。
- 利用CNN对感兴趣的region在图片分类任务上预训练之后,在目标检测领域微调。
- 从训练完成的CNN中抽取特征用于下游算法SVM,实现对象识别。
- 从训练完成的CNN中抽取特征,利用线性回归模型拟合box坐标。
由上可知,数据稀少的问题是基于预训练微调的方式处理。
值得一提的是,为了降低重复的检测,使用非最大值抑制的方式处理检测结果。
Fast R-CNN
与R-CNN相比,Fast R-CNN采用许多创新方法,提高了训练速度和推理速度。
正如Fast R-CNN所述,目标检测算法有两个主要的挑战:
- 大量的候选对象需要处理。
- 候选对象的定位是粗糙的,需要精细化。
在Fast R-CNN作者看来,R-CNN拥有以下缺点:
- 训练是一个多阶段的流程。
- 训练需要大量的时间和空间。
- 推理速度很慢。
同时,作者们认为R-CNN之所以很慢,是因为卷积神经网络在执行前向过程时,并没有共享计算。
在Fast R-CNN被提出之前,SPPnets加速R-CNN。其加速方式主要是利用最大化池化操作抽取特征地图,从而共享计算。然而,在Fast R-CNN作者看来,SPPnets具有以下缺点:
- 与R-CNN一样,仍然是一个多阶段的。
- 与R-CNN不一样的是,由于微调时无法更新卷积层网络参数,限制了CNN的表达力。
为了解决以上模型存在的缺陷,Fast R-CNN拥有以下优势:
- 较高的检测质量。
- 训练是单阶段的。
- 训练可更新所有网络参数。
- 无需硬盘缓存特征。
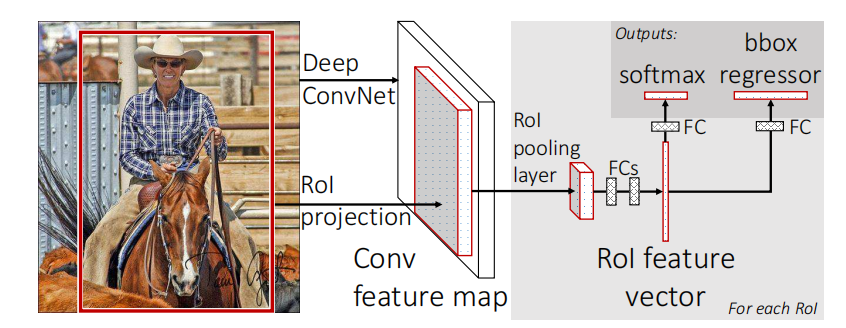
根据图2,可知,Fast R-CNN的输入为整张图片和候选对象集。首先,利用多层卷积神经网络处理整张图片,再利用最大化池化层产生特征地图。然后,再对每个候选对象从特征地图抽取固定长度的特征向量。最后把特征输入到全连接层,并形成两个兄弟分支,一个分支预测K个类别的概率和是否背景的概率,另一个用于预测四真实值,分别对应box左上角顶点坐标、box的宽与高。由此,多任务损失函数产生了。
值得一提的是,微调时,SPPnet无法更新空间金字塔池化层以下卷积层的权重,主要是因为若每个训练样本(Region of Interest)来自不同的图片,反向传播是非常的不高效。这种不高效主要原因是RoI有很大的感受野,且横跨整个输入图片,因此训练输入是很大的。
为了应对这种不高效,Fast R-CNN利用特征共享的优势制定了高效训练方法层级采样:
- 采样$N$张图片
- 每张图片采样$R/N$个感兴趣区域($R$为mini-batch的大小)用于本次训练。
此外,根据Fast R-CNN架构可知其是单阶段,而不是多阶段,因此训练和推理速度有很大的提高。
Faster R-CNN
在Fast R-CNN之后,阻挡训练和推理速度的就只有区域提出了。之前两个版本的R-CNN,均是利用选择性搜索进行区域提出。这种方式是基于低级别特征融合像素,速度很慢,且在CPU上运行。
Faster R-CNN另辟蹊径,提出了RPN(Regoin Proposal Networks)网络,可见图1所示。该网络是全卷积神经网络,可端到端训练,共提出$k$个boxes,有两个输出,一个输出box内存在对象的概率,输出维度为$2k$;另一个输出每个box的坐标,输出维度为$4k$。
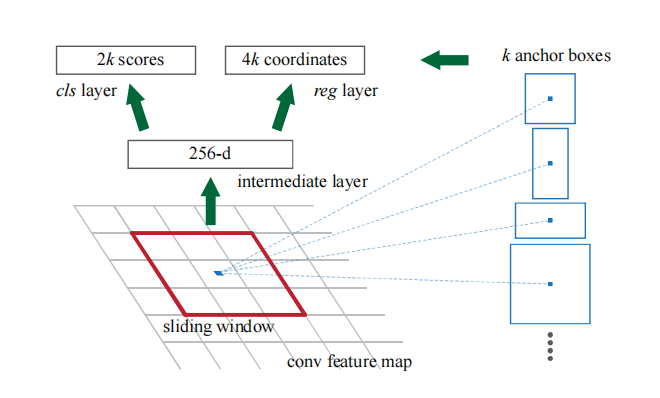
为了提高训练速度和推理速度,Fast R-CNN与RPN共享卷积特征,即它们的卷积特征地图由底层的卷积层输出。如图3所示,RPN网络利用滑动窗口从整张图片的特征地图中抽取特征,用于提出box。
为了RPN网络与目标检测网络共享卷积特征,提出了一种交替优化方法:
- 利用ImageNet预训练模型初始化共享卷积网络,且端到端的在区域提出任务上微调。
- 利用ImageNet预训练模型初始化Fast R-CNN网络中共享卷积网络,利用步骤1中RPN网络提出候选区域,训练目标检测网络。
- 用检测网络初始化RPN网络,固定共享卷积部分,只微调专属于RPN网络的部分。
- 固定检测网络中共享卷积部分,只微调Fast R-CNN的全连接层。
此时,两个网络共享相同的卷积层,从而提高了训练与推理速度。
值得一提的是,对于RPN网络的损失函数是一个多任务损失函数,且能够应对大小变化的区域,具体可参见文献[4]。
Mask R-CNN
与Faster R-CNN网络相比,Mask R-CNN网络只是增加了一个预测目标掩码的分支,可见图4所示。
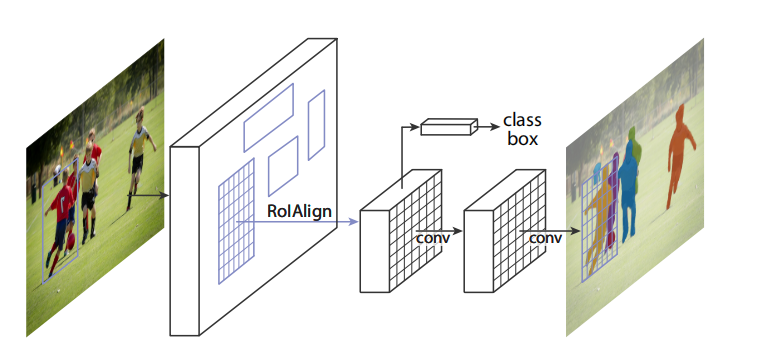
在计算机视觉中,目标检测的目标是从一张图片中定位每个对象,且预测对象的类别;语义分割的目标是把每个像素分类成一个固定类别集合,不用区分对象。实例分割即是语义的,也是检测的。因此,实例分割经常与目标检测任务相结合。
直觉上来说,Mask R-CNN是Faster R-CNN的一个扩展。然而,与实例分割相比,Faster R-CNN网络的设计并不是输入与输出之间的像素对齐。其中,最明显的网络模块是RoIPool,一种抽取特征的空间量化技术。为了解决这种不对齐,Mask R-CNN利用了一个简单无量化的层,被称为RoIAlign,精确的保存了空间位置。简单来说,RoIAlign没有采用量化技术,且对RoI的每个bin的四个采样点,利用双线性插值的方法计算其值。
版权: 本篇博文采用《CC BY-NC-ND 4.0》,转载必须注明作者和本文链接