GQA:从多头checkpoints中训练通用多查询Transformer模型
自回归解码器推理的成本很高,这是因为每个解码步骤加载解码器权重和所有注意力的keys与values的内存带宽很高。多查询注意力MAQ利用多个查询头但只有一个键与值,因此内存带宽的需求大大降低。然而,MQA会导致模型质量退化且训练不稳定。而且,为了优化质量与推理速度,单独训练一个模型不可行。为了平衡模型质量与推理速度,GQA作者做出了两个贡献,分别是:
- 利用多头注意力的checkpoints可uptrained模型MQA。
- 提出了分组查询注意力,即查询头的每个子组拥有单个键与值,该注意力机制不仅质量与多头注意力相似,且与多查询注意力一样快。
Uptraining
从多头模型产生多查询模型需要两步:
- 把多头注意力的checkpoints转换成多查询注意力,转换方法可见图1所示。
- 对多查询注意力模型进行预训练,使权重参数适应新结构。
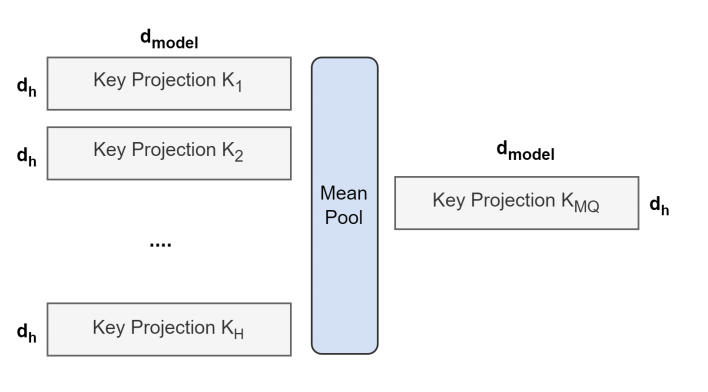
图1 多头到多查询的转换概览
分组查询注意力
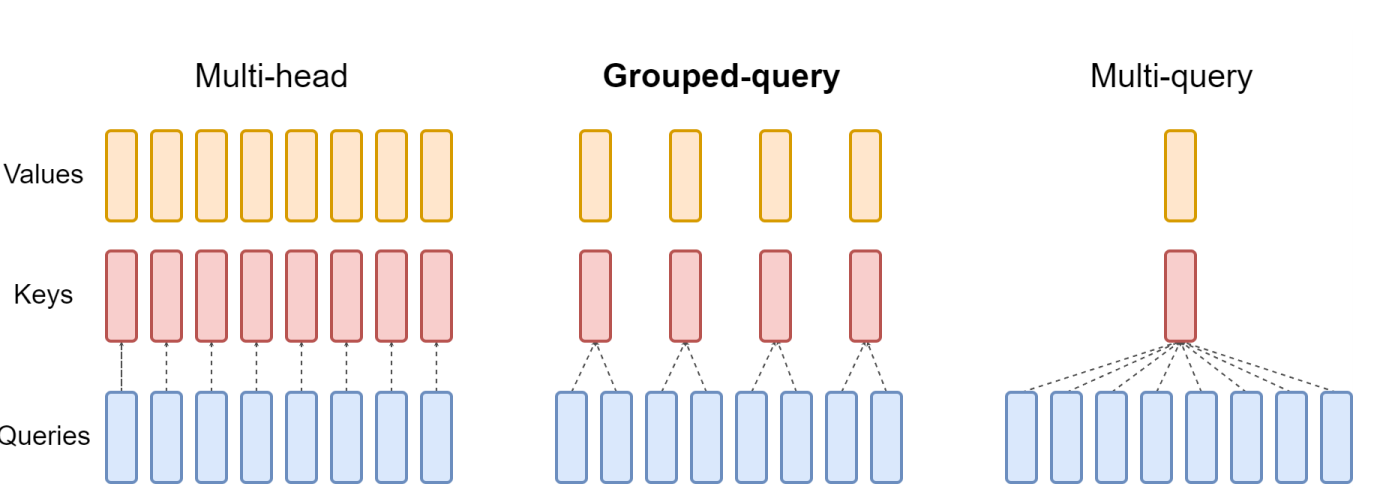
图2 分组查询方法概览
引用方法
请参考:
li,wanye. "GQA:从多头checkpoints中训练通用多查询Transformer模型". wyli'Blog (Apr 2024). https://www.robotech.ink/index.php/archives/400.html
或BibTex方式引用:
@online{eaiStar-400,
title={GQA:从多头checkpoints中训练通用多查询Transformer模型},
author={li,wanye},
year={2024},
month={Apr},
url="https://www.robotech.ink/index.php/archives/400.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接