MoE(一):网络架构演进与特性
MoE拥有很强的表达能力,在深度学习领域取得显著成果。同时,根据论文《Mixtures of Experts Unlock Parameter Scaling for Deep RL》,可知,MoE可解锁深度RL的参数扩展。那么,混合专家模型MoE究竟是什么呢?
网络架构
MoE通常由Experts网络和Gating网络构成。其中,Gating网络也称为router。专家网络主要学习特定的技能知识,router通常起到负载平衡和专家平衡调度的功能。
原则上,专家网络和router只需要满足输入的大小相同和输出的大小相同。实践中,大部份情况是专家的网络架构通常相同。然而,Gating网络处于不断的演进。
网络架构演进
MoE网络架构通常围绕着专家调度方式而演进的,从而实现专家利用的平衡和提高训练稳定性。
Sparse Gating
混合专家模型与深度神经网络结合,起源于《Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer》,提出了两种Gating方式:
Softmax Gating:可训练权重矩阵$W_g$与输入相乘,即
$$ \begin{aligned} G_{\sigma}(x)=Softmax(x\cdot W_g) \end{aligned}\tag{1} $$
Noise Top-K Gating:每个输入对应Top-K专家,且噪音项有助于负载平衡
$$ \begin{aligned} G(x)=Softmax(KeepTopK(H(x),k)) \end{aligned}\tag{2} $$
$$ \begin{aligned} H(x)_i=(x\cdot W_g)_i+StandardNormal()\cdot Softplus((x\cdot W_{noise})_i) \end{aligned}\tag{3} $$
$$ \begin{aligned} KeepTopK(v,k)_i=\begin{cases}v_i & if~v_i~is~in~the~top~k~elements~of~v. \\ -\infty &otherwise \end{cases} \end{aligned}\tag{4} $$
专家选择Tokens
为了解决存在部分专家未被充分训练的情况,《Mixture-of-Experts with Expert Choice Routing》通过每个专家选择特定数量的Top-k Token的方式直接解决专家利用不平衡的问题。该方式使每个Token对应的专家数量不同,而每个专家处理的Token数量的方式相同的。
显而易见的,专家选择Token的调度方式,很容易出现Token Dropping的现象。
Soft Gating
为了解决训练不稳定、Token Dropping、专家扩展不稳定的、或微调效率不高的问题,《From Sparse to Soft Mixtures of Experts》把Sparse转变为了Soft。确切的说,通过把输入的不同加权组合喂给每个专家,即施加了一个隐式的Soft。实际上,每个专家也只是处理部分组合Tokens。
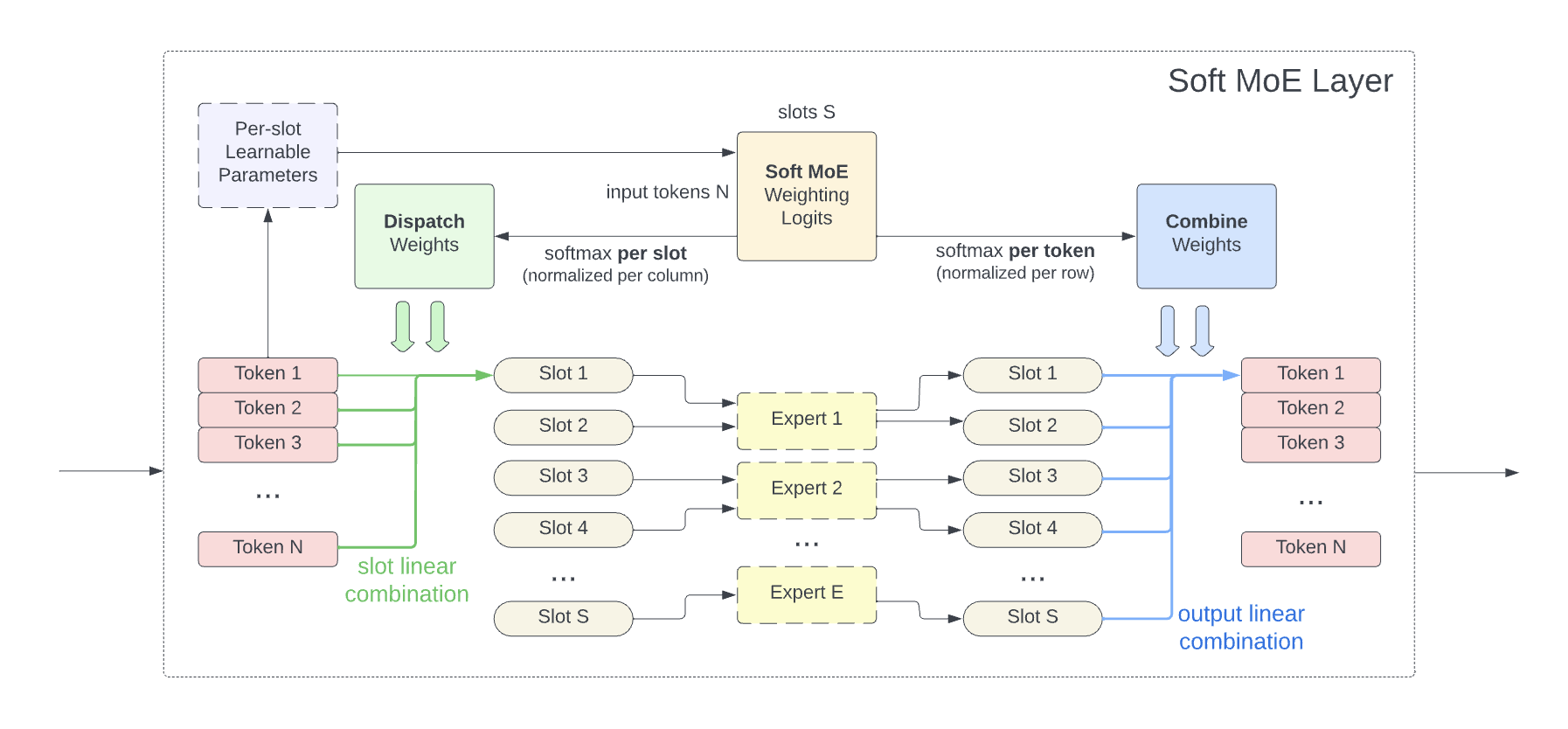
图1 Soft MoE
根据图1可知,每个专家处理同等数量的slot,而每个slot对应不同权重下的输入和。由此,slot总数量对MoE训练的时间复杂度影响很大。
简单来说,Soft MoE在稀疏性和训练稳定性之间寻求了一个balance。
Plus: 专家的调度方法,还有k-means聚类、线形规划、hashing、以及RL方法。
网络架构特性
MoE网络架构不仅扩展了模型容量,且只引入了很小的计算预算。这是因为router把每个输入分配给特定的一些专家,从而只需要少量计算就可以实现推理。由此,MoE不仅表达能力强,且训练和推理成本相对较低。
引用方法
请参考:
li,wanye. "MoE(一):网络架构演进与特性". wyli'Blog (Jul 2025). https://www.robotech.ink/index.php/archives/745.html
或BibTex方式引用:
@online{eaiStar-745,
title={MoE(一):网络架构演进与特性},
author={li,wanye},
year={2025},
month={Jul},
url="https://www.robotech.ink/index.php/archives/745.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接