ExBody:富有表达力的WBC
对于机器人来说,由于自由度与物理能力限制的原因,往往倾向于产生不自然的运动形态,这种运动呈现不自然且缺乏优美与个性化。为了使人形机器人学习出与人体运动在表达性与丰富性上相媲美的全身运动控制策略,ExBody作者们通过把大规模人类运动捕获数据与强化学习相结合,学习出可直接部署到真实机器人上的全身控制器。同时,为了解决机器人局限性导致直接精确模仿参考运动不可行的问题,提出以参考运动与root运动命令作为控制器的输入。确切的说,机器人的upper body模仿各种各样人类运动以提高表达性,松弛双腿运动模仿项以提高鲁棒性。如图1所示,ExBody框架概览。
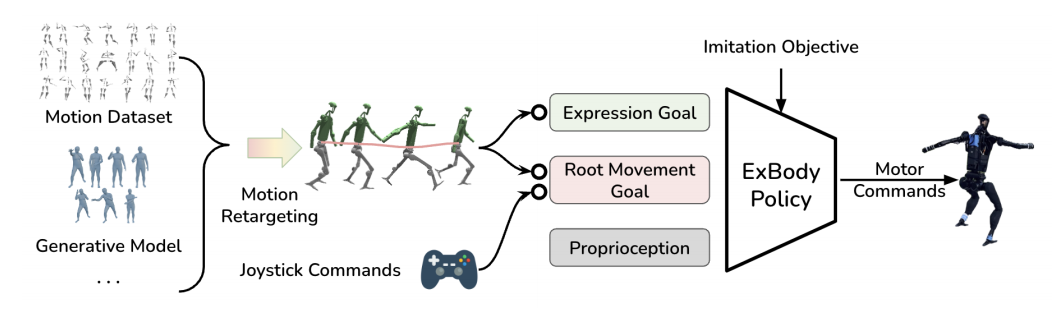
图1 ExBody框架概览
算法设计
ExBody作者们把人形运动控制视作学习一个目标为条件的电动机策略$\pi:\mathcal{G}\times\mathcal{S}\to\mathcal{A}$。其中,$\mathcal{G}$为确定行为的目标空间,$\mathcal{S}$为观测空间,$\mathcal{A}$为包含关节位置与力矩的动作空间。
a)命令为条件的运动控制:以线速度$\mathbf{v}\in\mathbb{R}^3$、身体位姿$rpy\in\mathbb{R}^3$、以及root关节处的身体高度$h$为命令的强劲控制策略。确切的说,root运动控制的目标空间为$\mathcal{G}^m=\langle\mathbf{v},rpy,h\rangle$。观测空间包含机器人当前的本体感知信息$s_t=[w_t,r_t,p_t,\Delta y,q_t,\dot{q}_t,\mathbf{a}_{t-1}]^T$。其中,$w_t$为机器人root的角速度,$r_t,p_t$为旋转角与俯仰角。需要注意的是,控制策略无法观测到当前速度$\mathbf{v}$、身体绝对高度$h$、以及当前偏航角$y_t$,这些信息对于真实机器人属于特权信息。作者们使策略观测到当前偏航角与期望偏航角的差值$\Delta y$,把全局量转换到局部坐标系,从而有利于部署期间的控制。动作$\mathbf{a}_t\in\mathbb{R}^{19}$是关节比例控制器的目标位置。
b)极具表达性的全身控制:对于控制命令,还包含机器人的运动描述,即目标空间$\mathcal{G}=\mathcal{G}^e\times\mathcal{G}^m$,其表达性目标$\mathbf{g}^e\sim\mathcal{G}^e$包含期望关节角度与各种各样3D关键点。确切的说,$\mathcal{G}^e=\langle\mathbf{q},\mathbf{q}\rangle$只包含上半身的关节与关键点。其中,$\mathbf{q}\in\mathbb{R}^9$为上半身的9个执行其关节位置,$\mathbf{p}\in\mathbb{R}^{18}$为两个肩膀、两个肘、以及左右手的3D关节点。
Human行为数据的整理策略
由于Unitree H1机器人无法与真实环境进行大量的交互,因此作者们选择了部分CMU MoCap数据集,筛选掉了包含与他人、沉重物品或粗糙领域物理交互的数据。同时,作者们通过数据散点图可视化的方式对数据进行利分析。
运动重定向到硬件
为了考虑H1机器人与人体上拓扑的不同,作者们直接把局部关节旋转映射到机器人骨架。对于机器人,肩膀与髋关节有三个垂直连接的旋转关节点击相连接,与人体运动AMASS和HumanML3D数据集的球关节相对应。在重定向期间,把3个髋关节或肩关节视为1个球关节。在重定向之后,把用4元数表示的球关节$\mathbf{q_m^i}=(q_x,q_y,q_z,q_w)$映射为3个关节的旋转角度$\mathbf{m}=[m_1,m_2,m_3]\in\mathbb{R}^3$。为了实现这种转换,先把四元数转换为角与轴
$$ \begin{aligned} \theta=2arccos(q_w),\mathbf{a}=\frac{1}{\sqrt{1-q_w^2}}\begin{pmatrix}q_x\\q_y\\q_z\end{pmatrix} \end{aligned}\tag{1} $$
式(1)中$\mathbf{a}$为旋转轴,$\theta$为旋转角。然后,通过$\mathbf{m}=\theta\mathbf{a}$的方式映射角度。对于1D的关节,直接映射对应的角度即可。
基于Human Mocap数据引导状态初始化
对于仿真中每个环境机器人的初始状态,从数据集中随机采样得到初始状态$g=[g^e,g^m]$。
奖励
对于每一步,环境的奖励由表达性目标、root运动目标追踪、以及正则化项构成。如表1所示,模仿奖励由上半身关节参考位置$\mathbf{q}_{ref}\in\mathbb{R}^9$、上半身关键点参考位置$\mathbf{p}_{ref}\in\mathbb{R}^{18}$、身体参考速度$\mathbf{v}_{ref}$、身体旋转与俯仰真实数据$\mathbf{\Omega}_{ref}^{\phi\theta}$和参考数据$\mathbf{\Omega}^{\phi\theta}$构成。
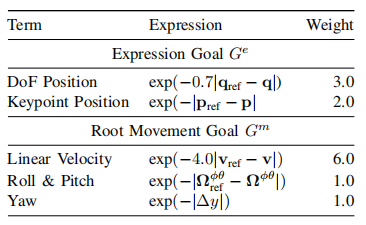
表1 表达性奖励明细
对于,正则化奖励可见表2所示。
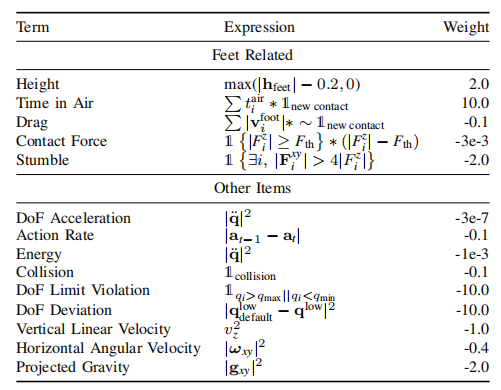
表2 正则化奖励明细
相关思考
ExBody为人形机器人富有表达力运动和奖励设计开辟了新思路,开辟了基于学习范式的全身控制策略开发。总的来说Exbody通过设置上半身与下半身不同的奖励函数,从而使机器人不仅能够学习出富有表达力的运动,且运动鲁棒性较强。正如作者所述,本项工作有望启发通用人形机器人全身操作与导航的研究。
引用方法
请参考:
li,wanye. "ExBody:富有表达力的WBC". wyli'Blog (Apr 2024). https://www.robotech.ink/index.php/archives/474.html
或BibTex方式引用:
@online{eaiStar-474,
title={ExBody:富有表达力的WBC},
author={li,wanye},
year={2024},
month={Apr},
url="https://www.robotech.ink/index.php/archives/474.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接