FiLM:带有通用条件层的视觉推理
Feature-wise Linear Modulation(FiLM)是一个神经网络通用目的的调节方法,通过特征级别的仿射变换影响神经网络计算。实验结果,表明,FiLM层对视觉推理任务非常有效,例如:回答图片相关的问题。然而,这类问题对标准深度学习方法来说很困难。标准的深度学习主要是学习到数据中的偏差,而不是学习推理方法。
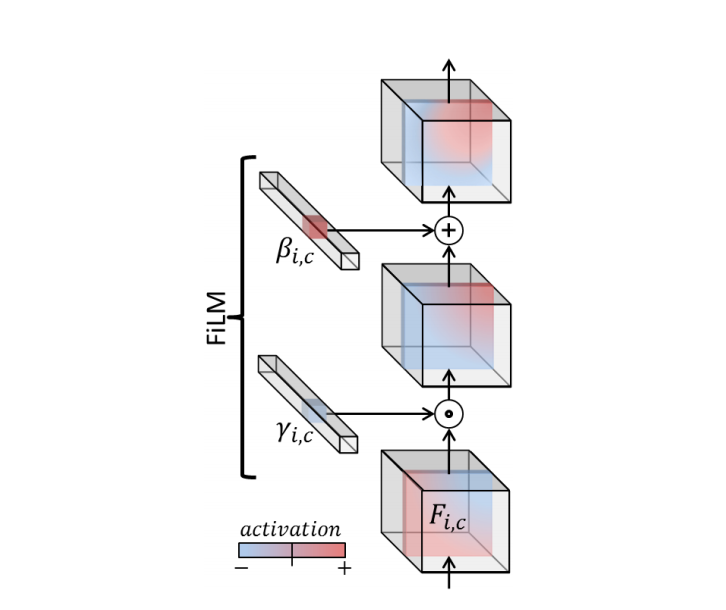
如图1所示,FiLM处理卷积网络输出的每个特征方法为
- 学习出函数$f$和$h$,使每个输入$x_i$都对应$\gamma_{i,c}$和$\beta_{i,c}$
$$ \begin{aligned} \gamma_{i,c}=f_c(x_i)\qquad\beta_{i,c}=h_c(x_i) \end{aligned}\tag{1} $$
式(1)中下标$i,c$表示第$i$个输入的第$c$个特征。
- 每个特征都经过式(2)的仿射变换
$$ \begin{aligned} FiLM(\mathbf{F}_{i,c}\vert\gamma_{i,c},\beta_{i,c})=\gamma_{i,c}\mathbf{F}_{i,c}+\beta_{i,c} \end{aligned}\tag{2} $$
其中,$\cdot$代表的是文献$[2]$中Hadamard积。
具体来说,标准深度学习能够回答单步推理的问题,例如:看一眼就知道答案的问题,需要多步推理的问题就难以回答。如图2所示,FiLM在需要多步推理的CLVER数据集中表现。

参考文献
$[1]$ Perez E, Strub F, De Vries H, et al. Film: Visual reasoning with a general conditioning layer$[C]$//Proceedings of the AAAI conference on artificial intelligence. 2018, 32(1).
$[2]$ https://en.wikipedia.org/wiki/Hadamard_product_(matrices)
引用方法
请参考:
li,wanye. "FiLM:带有通用条件层的视觉推理". wyli'Blog (Jan 2024). https://www.robotech.ink/index.php/archives/111.html
或BibTex方式引用:
@online{eaiStar-111,
title={FiLM:带有通用条件层的视觉推理},
author={li,wanye},
year={2024},
month={Jan},
url="https://www.robotech.ink/index.php/archives/111.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接