漫谈YOLO系列算法的演进一
目标检测是计算机视觉领域重要任务之一。在深度学习时代,YOLO算法属于主流算法之一。
目标检测算法的度量与非最大值抑制
Mean Average Precision是一个常用的度量方法,用于评估检测模型的表现。在评估模型性能时,会先计算每个类别的AP,然后再求平均得到mAP。然而,对于不同的数据集,mAP的计算方法不同。
mAP的计算
在介绍不同数据集中mAP的计算方法之前,先介绍一下AP的计算方法。在二分类问题中,Precision度量模型正样本预测的精度,Recall度量模型正确预测真实正样本的比例。同时,精确率与召回率之间常常是此消彼长的指标。为了更好的权衡精确率和召回率之间的平衡,常考虑以PR曲线下面积为AP的度量结果。
VOC数据集
计算步骤:
- 对于每一个类别,通过变化阈值计算PR曲线。
- 利用PR曲线上采样的11个点的平均值作为每个类别的AP。
- 求和所有类别的AP,并求平均。
Microsoft COCO数据集
- 通过变化模型预测置信度阈值计算每个类别的PR曲线。
- 基于101个召回阈值计算每个类别的平均精度。
- 以0.05为步长在范围为0.5至0.95变化IoU阈值,计算不同IoU阈值下的AP。
- 对每个IoU阈值,求80个类别APs的平均。
- 平均所有AP作为整体的AP。
非最大值抑制
非最大值抑制是一个目标检测算法的后处理技术,用于减少重叠有界boxes。如图2所示,NMS算法。

如图3所示,左图为NMS算法处理之前目标检测算法提出的有界boxes,右图为NMS处理之后的效果。

YOLO
YOLO是一个单阶段的目标检测算法,同时预测有界boxes和类别概率。首先,一张图片被分为$S\times S$的网格,每个网络只预测一个类别,且预测$B$个boxes。每个boxes的预测,由包含对象的概率$P_c$、boxes相对单元格位置的中心点坐标$bx,by$、boxes相对整张图片的高$bh$与宽$bw$。若假设数据集中包含的类别数为$C$,那么对于一张图片,YOLO输出$S\times S\times (B\times 5+C)$个预测值。
网络架构
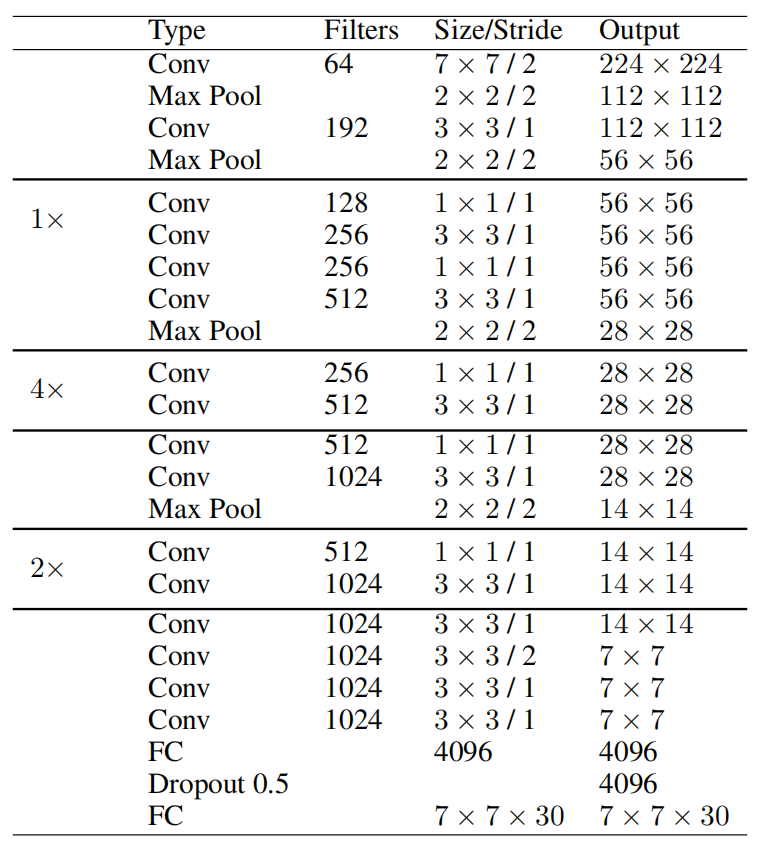
YOLOv1由24层卷积层和2层全连接层构成。除了最后一层使用线性激活函数外,其余层都是用leaky relu作为激活函数。基于GoogLeNet和NIN启发,利用$1\times 1$卷积层减少特征地图的数量和保持参数较低的数量。如表1所示,YOLOv1的网络架构。
表1:YOLO网络架构
模型训练
YOLOv1先在ImageNet数据集中分辨率为$224\times 224$的图片数据预训练20层。然后,利用随机初始化增加最后四层,在PASCAL VOC2007和VOC2012数据集中分辨率为$448\times 448$上微调。
对于数据增强,YOLOv1只对输入图片大小的$20%$做了随机的缩放和平移,而且在HSV颜色空间内利用上限系数为1.5进行随机曝光和饱和。
如图4所示,YOLOv1的损失函数由多项平方误差和构成。
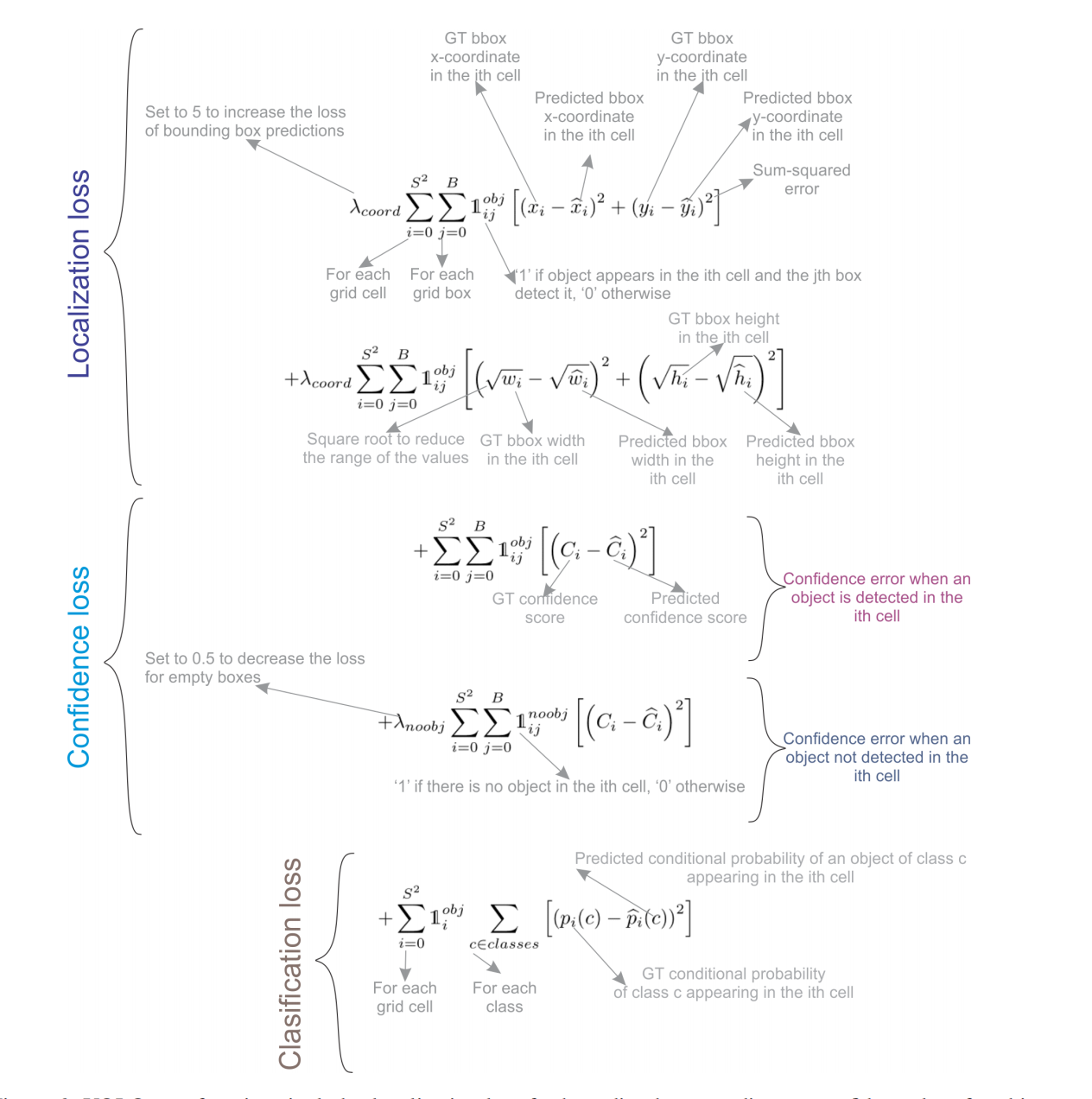
图4:YOLOv1的损失函数
优势与局限性
YOLOv1架构简单,基于单张图片一次回归使其比其它多阶段目标检测的实时检测速度更快。
然而,YOLO仍然存在三个局限:
- 一个单元格内只预测相同类别的两个有界boxes,限制了预测临近对象的能力。
- 它很难预测数据集中没有的高宽比对象。
- 由于下采样层的存在,它只学习了粗糙的对象特征。
参考文献
版权: 本篇博文采用《CC BY-NC-ND 4.0》,转载必须注明作者和本文链接
赞