漫谈YOLO系列算法的演进二
YOLOv2的backbone架构是Darknet-19,由19个卷积层和5个最大化池化层构成。与YOLOv1相似,在$3\times3$卷积层之间利用$1\times1$卷积层减少参数的数量。除此之外,还使用batch normalization加快模型收敛速度。如表1所示,YOLOv2的网络架构。YOLOv2对每个单元格预测5个有界boxes,可见图1所示。每个boxes对应5个预测值和20个类别概率,可见图2所示。
目标检测网络的分类head用带有1000个过滤器的单个卷积层替换了最后4个卷积层,然后是全局平均池化和Softmax层。
表1 YOLOv2网络架构
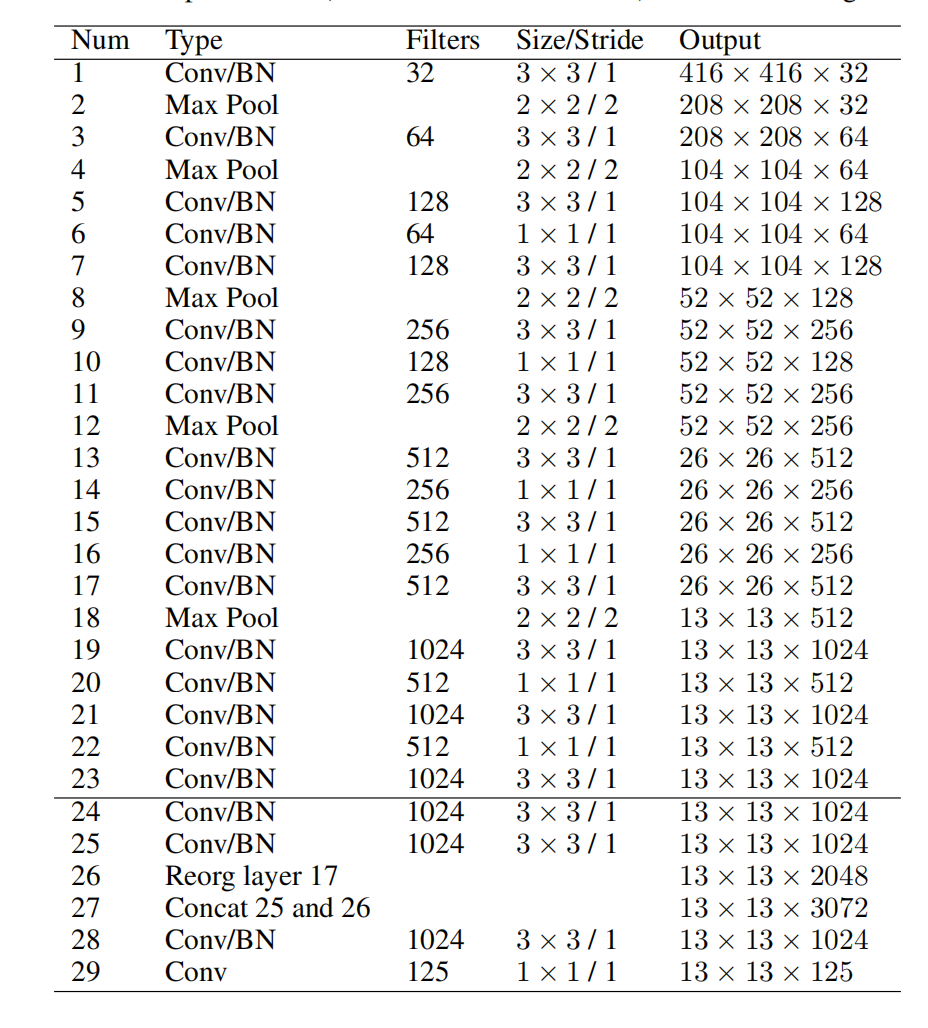
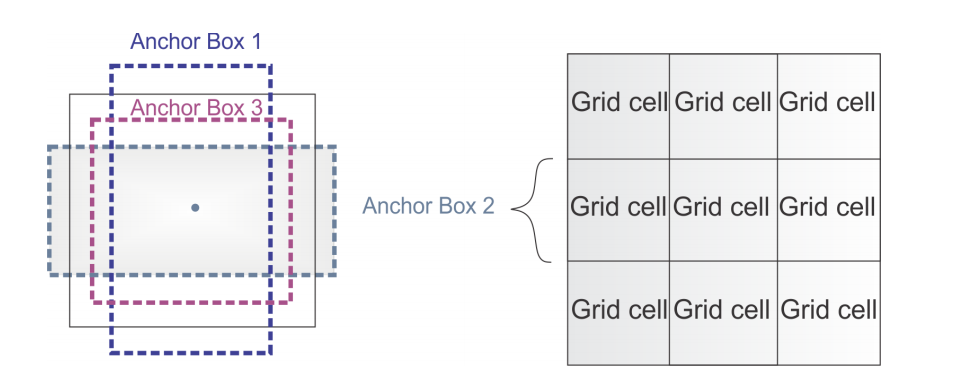
图1 YOLOv2的anchor-boxes
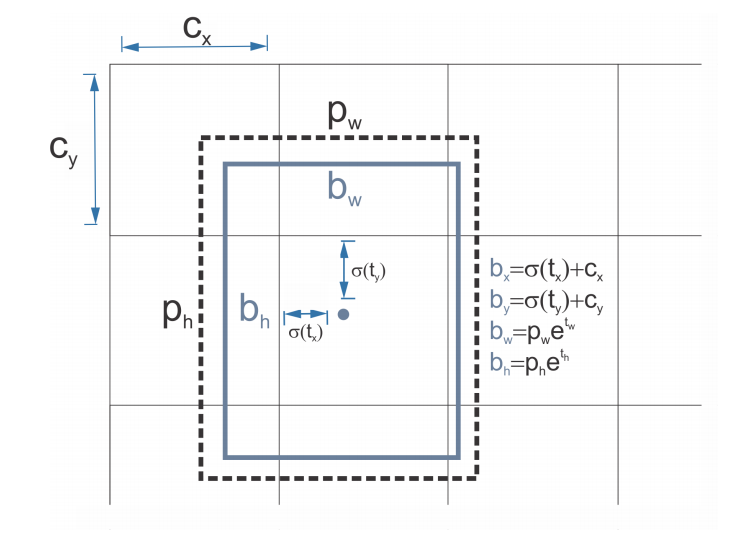
图2 YOLOv2的有界boxes预测
YOLOv2的另一个创新点是分类任务和检测任务的联合训练。简单来说,利用来自于COCO有标签的目标检测数据学习有界boxes坐标,利用来自于ImageNet分类数据增加其能够检测的种类。在训练时,结合了两份数据,在训练检测任务时,梯度反向传播检测网络;在训练分类任务时,梯度反向传播架构分类的部分。最终,YOLO模型能够检测超过9000个类别。
YOLOv3
YOLOv3的backbone是Darknet-53,如图2所示。
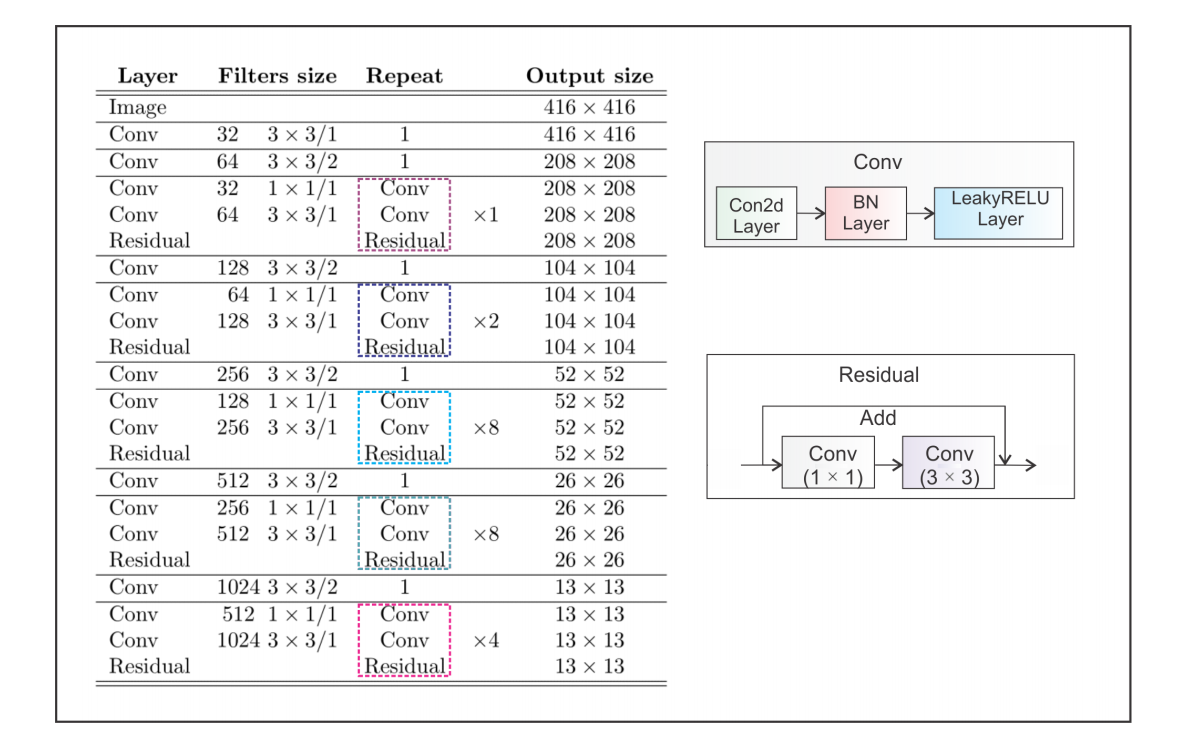
图2 YOLOv3 Backbone的架构
YOLOv3的另一个特点是多规模预测,它预测多个尺寸的网格。这有助于获得精细的boxes,明显提升了小boxes预测的性能。如图3所示,多规模检测架构。
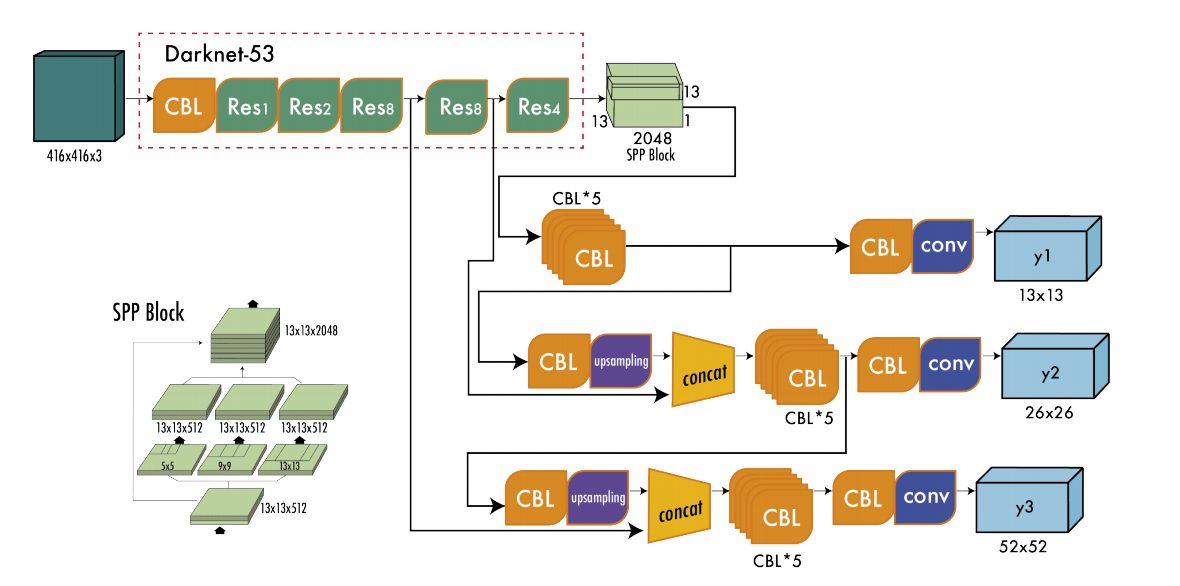
图3 YOLOv3 Multi-scale检测架构, CBL:Convolution-BatchNorm-Leaky ReLU
多规模预测的输出$y_1$等同于YOLOv2的输出;输出$y2$由Darknet-53的$Res\times4$和$Res\times8$concat之后预测的输出;输出$y_3$也是多层级特征concat之后的输出。对于有80个类别的COCO数据集,每个输出通道的大小为$N\times N\times[3\times(4+1+80)]$。
如图4所示,自从YOLOv3之后目标检测网络被分为三大部分,分别是Backbone,Neck,head。其中,Backbone负责从图片中抽取有用特征。Neck负责连接backnbone与head,以聚集和精炼特征,从而提高不同规模的空间和语义信息。Head基于特征进行预测,一个典型的多任务预测。
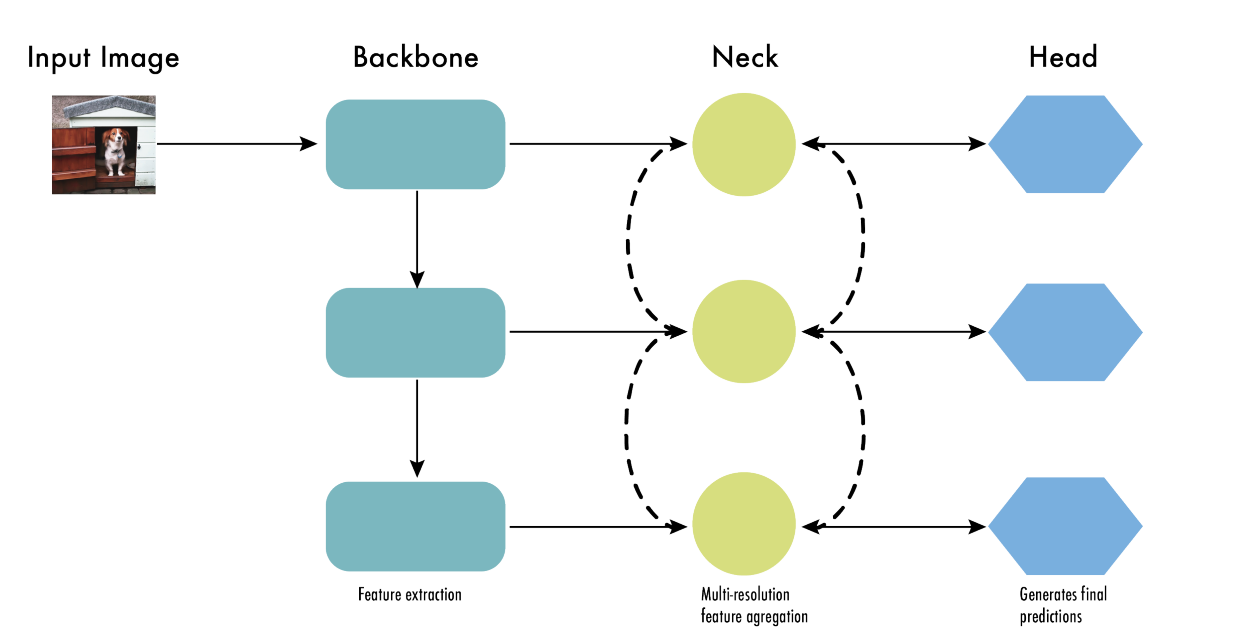
图4 目标检测网络架构
参考文献
版权: 本篇博文采用《CC BY-NC-ND 4.0》,转载必须注明作者和本文链接