BeT:一次克隆K个模式
行为克隆算法的前提假设是数据来自于解决特定任务单一模式的专家演示。然而,真实世界的预先收集的数据包含行为的多个模式,即使是同一个人对同样的行为也会展示多种模式。另一方面,Transformer模型容量足够大,且拥有建模多种token的能力。因此,BeT把Transofmer与Behavior Cloning相结合以能够预测多峰分布的动作。
同时,作者们在5个数据集中进行实验,结果表明:
- 在多模态数据集上,与之前的行为建模算法相比,BeT能够实现较高的性能。
- BeT能够覆盖数据集中的主要模式,而不是一个模式。
如图1所示,BeT的架构。
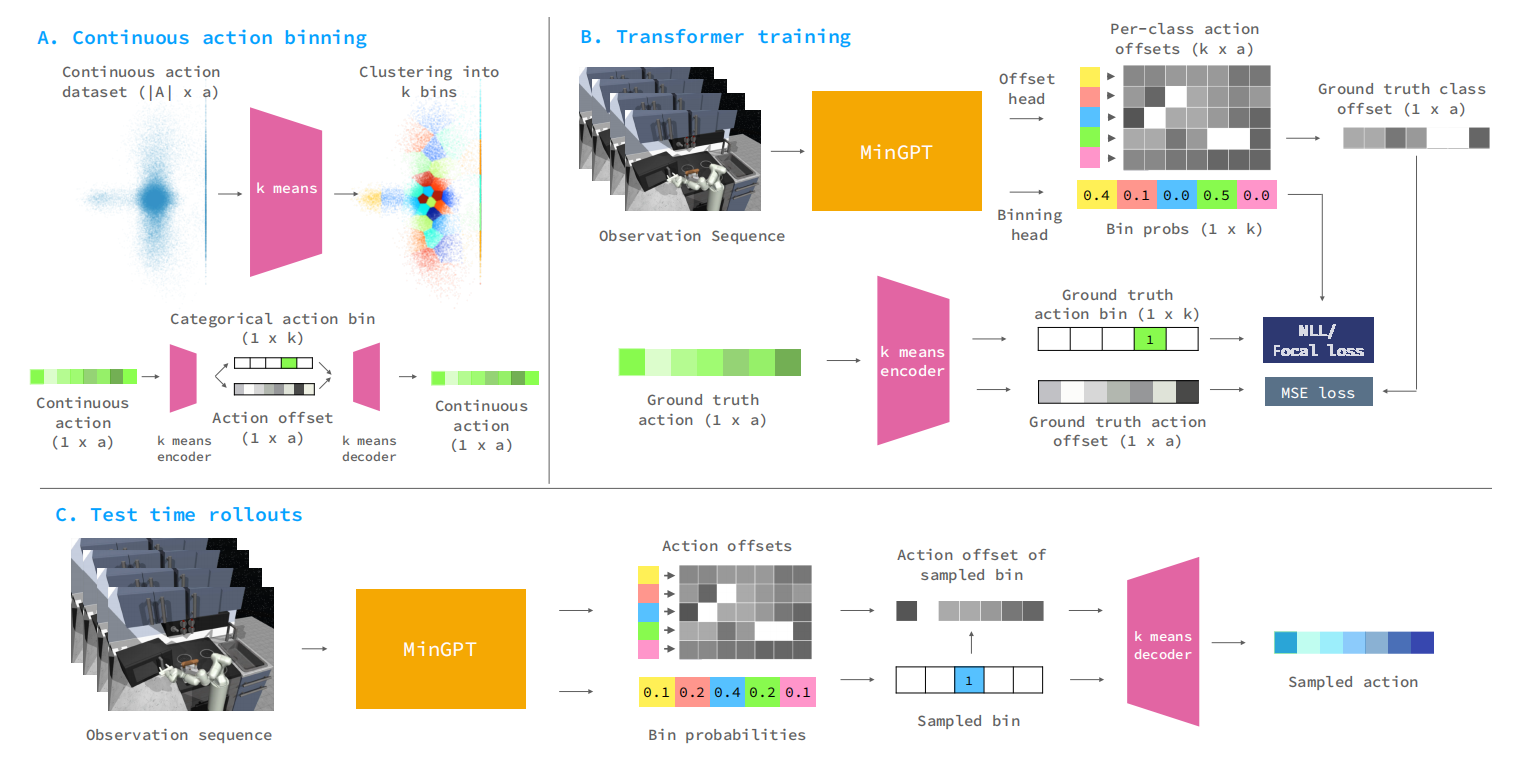
图1 BeT架构
图1中MiniGPT实际上是GPT3。
算法设计
虽然Transformer成为了序列到序列建模的标准骨架,但是它被设计为处理离散tokens和不连续值。同时,对于建模高纬连续变量的多峰分布,本身就是非常大的挑战。因此,作者们把动作分为两个部分,分别是类别变量表示动作的中心和一个动作的残差量。通过预测残差量的方式,降低了离散化连续动作造成的可信度损失。
确切的说,BeT基于Transformer的Decorder架构进行序列到序列的建模。主要的创新点就是动作离散化,首先把数据集中动作利用K-means算法进行聚类,形成$k$个聚类中心。然后,每个动作与最近聚类中心的距离作为残差项,可见图1.A所示。在模型训练阶段,把最近$h$个观测序列作为输入预测$k$个聚类中心的概率分布,以及$k\times\vert A\vert$残差矩阵($\vert A\vert$为动作的维度)。其中,$k$个聚类中心的概率分布以Focal Loss作为损失函数(可见式(1)所示),而残差项以Masked Multi-Task Loss为损失函数(可见式(2)所示),可见图1.B。测试阶段,先基于聚类中心概率分布选择聚类中心,再基于聚类中心选择残差向量,聚类中心与残差向量求和为最终动作序列。
$$ \begin{aligned} \mathcal{L}_{focal}(p_t)=-(1-p_t)^{\gamma}log(p_t) \end{aligned}\tag{1} $$
相较于Cross-Entropy,Focal Loss更关注容易分类错误的Hard样本,因此非常适合样本不平衡的问题,两者的比较可见图2所示。
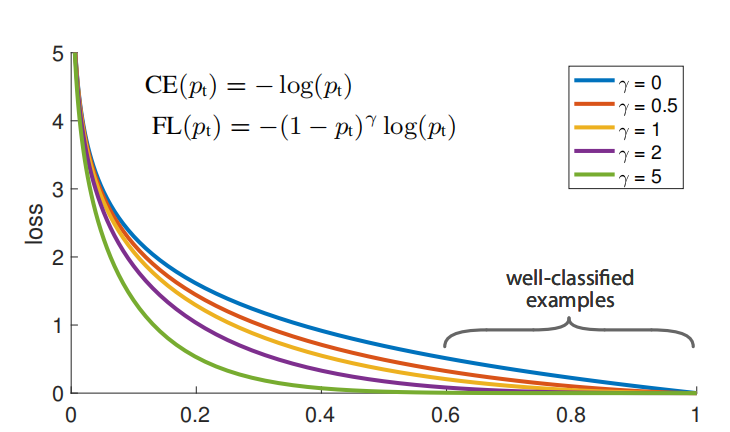
图2 CE与Focal Loss的比较
$$ \begin{aligned} MT-Loss(\mathbf{a},(<\hat{a}_i^{(j)}>)_{j=1}^k)=\sum_{j=1}^k\mathbb{I}[\lfloor\mathbf{a}\rfloor =j]\cdot\Vert <\mathbf{a}>-<\hat{a}^{(j)}> \Vert_2^2 \end{aligned}\tag{2} $$
式(2)中$\mathbb{I}$为指示函数,$\lfloor\mathbf{a}\rfloor$为动作$\mathbf{a}$对应的聚类中心,$<\mathbf{a}>$为动作的残差项。
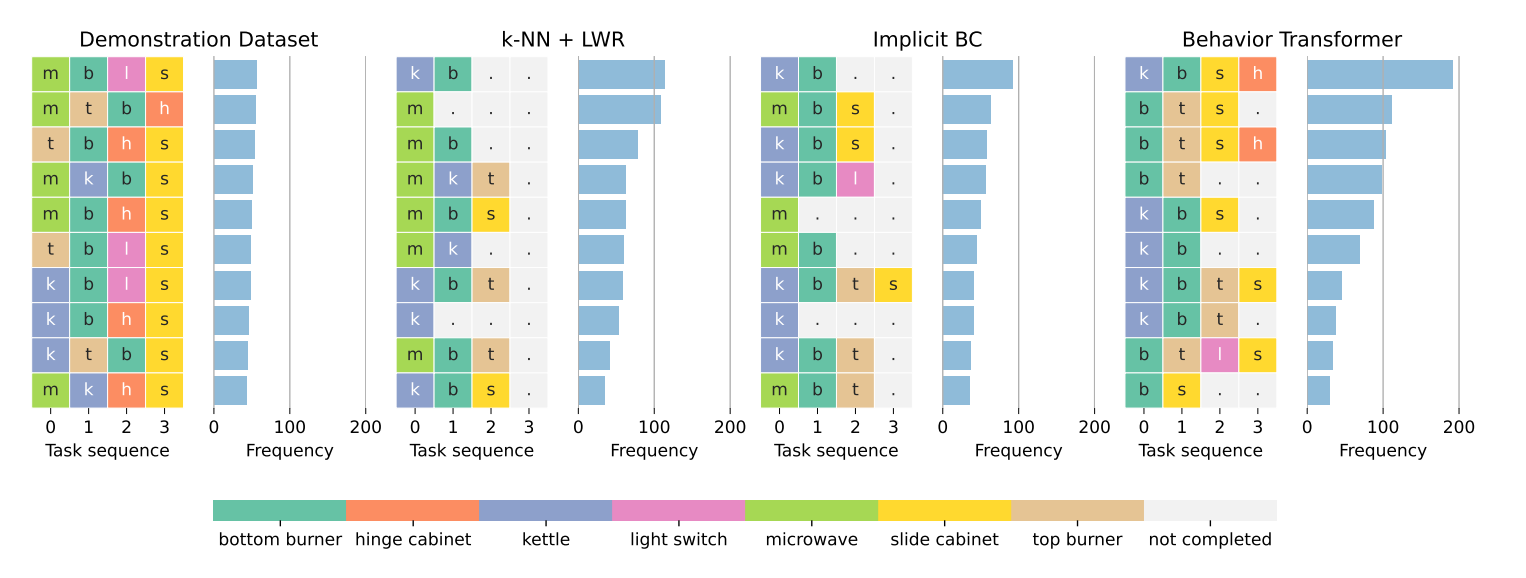
图3 厨房环境中模型效果
如图3所示,BeT与其它算法在厨房环境中的比较,不同的颜色代表不同任务。由此可见,BeT算法能够执行更长期的任务,且能够维护执行任务的多样性。
相关思考
BeT一个很明显的缺点就是K-means算法中$k$的选择,不同$k$对模型的效果是一个值得研究的方面。
这种动作离散化的方式与RT系列模型,把动作的每个维度分解成离散桶的方式不同。确切的说,BeT的动作分解更能降低动作离散化带来的可信度损失。
引用方法
请参考:
li,wanye. "BeT:一次克隆K个模式". wyli'Blog (Feb 2024). https://www.robotech.ink/index.php/archives/224.html
或BibTex方式引用:
@online{eaiStar-224,
title={BeT:一次克隆K个模式},
author={li,wanye},
year={2024},
month={Feb},
url="https://www.robotech.ink/index.php/archives/224.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接