Flamingo:少样本学习的视觉语言模型
在Flamingo之前,多模态模型主要的范式是预训练-微调。然而,有效的微调需要大量的标注数据,也需要精细的超参数微调,且微调需要更新全部参数,这种成本是很高的。虽然基于对比目标的多模态模型能够实现新任务上的少样本学习,但是只能应对有限的情况,无法应用于开放任务,例如:视觉问题回答、看图说话。大语言模型GPT3只需要根据新任务少量的提示-输入-输出的数据就能够实现较强的表示,这种范式被称为少样本学习。FLamingo在这一背景下被提出,它利用一个视觉模型感知视觉场景和语言模型执行推理。新的架构元件连接视觉模型和语言模型,且只有新元件参与训练。基于Perceiver视觉感知模型,Flamingo能够处理高分辨率图片和视频。如图1所示,Flamingo的网络架构。
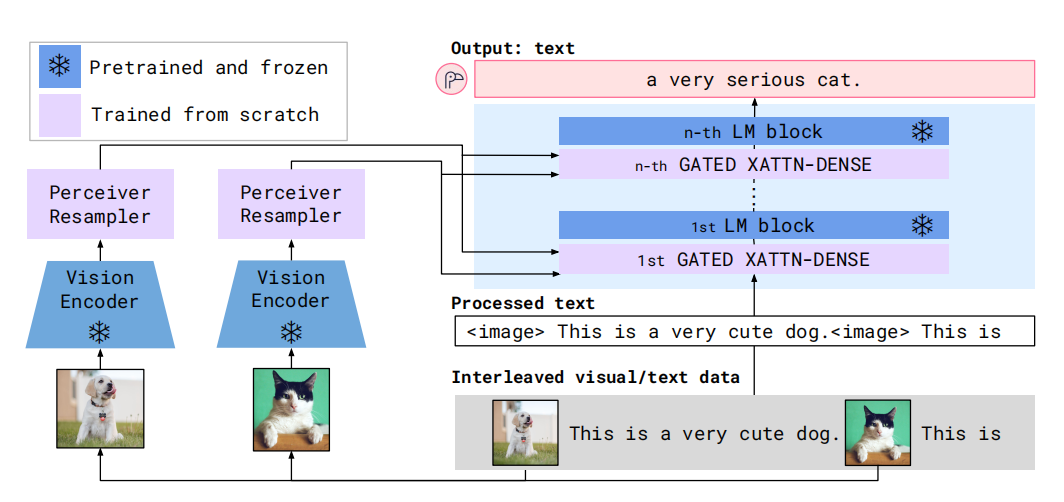
图1 Flamingo架构
算法设计
Flamingo可接受文本与图片、视频交织的数据作为输入或输出。首先,Perceiver Resampler接受视觉编码器的时空特征,输出固定数量的视觉tokens。接下来,视觉token与语言模型的输入和输出在交叉注意力层交互,从而包含下一个token预测的视觉信息。Flamingo的目标函数为
$$ \begin{aligned} p(y\vert x)=\prod_{l=1}^Lp(y_l\vert y\lt l,x\le l) \end{aligned}\tag{1} $$
式(1)中$y_l$为第$l$个语言token,$x_l$为第$l$个视觉token。
视觉处理与Perceiver Resampler
视觉编码器为预训练的Normalizer-Free ResNet,基于图片-文本对数据集和对比目标进行预训练。对于图片作为输入,编码器以2D空间网络为输入,输出1D的序列;对于视频作为输入,在1FPS采样的帧作为输入,且独立的编码获得3D时空特征网络,最后被flatten为1D。
Perceiver Resampler接受大小可变的特征地图,然后输出为固定长度的视觉编码,从而降低视觉文本交叉注意的计算成本。与Perceiver和DETR相似,学习了一个预定义数量的隐式输入queries。
视觉表示为条件的forzen语言模型
以Perceiver产生的视觉表示为条件,Transformer的decoder进行文本生成。

图2 XATTN-DENSE架构
如图2所示,文本与视觉交互的门控交叉注意力dense模块。为了确保初始化时,条件模型与原始语言模型产生相同的结果,利用tanh门控机制。其中,参数$\alpha$为可学习参数,且被初始化为0。
基于Chinchilla模型,构建了1.4B、7B、以及70B参数量的模型,分别被称为Flamingo-3B、Flamingo-9B、Flamingo-80B。这些模型的参数量主要增加在forzen的语言模型和可训练的视觉-文本门控交叉注意力dense模块,而视觉编码器和Perceiver参数量保持不变。
多视觉输入支持: 图片或视频的注意力掩码
根据式(1),整个模型是以之前的文本和图片为输入,掩码了整个序列中后续的文本和视觉。这种掩码的方式限制了每个文本token注意到的视觉token。对于给定文本token,交叉注意力模块只会注意到它之前出现的视觉token,而不是之前所有的视觉token。然而,在自注意力模块会关注到之前所有视觉token。这种单个图片交叉注意力机制允许模型可接受任何数量的视觉输入。Flamingo中,作者们限制每个序列中图片数量为5。
在视觉语言混合数据集上训练
Flamingo模型的训练是基于三种混合数据,分别是来自于互联网的图片-文本交织数据集、图片-文本对、以及视频-文本对。
M3W:Interleaved image and text dataset。Flamingo模型的少样本能力依赖于在文本-图片交织数据上的训练,这些数据均来自于互联网的网页。通过在纯文本中嵌入
Pairs of image/video and text。这两部分数据主要由作者收集得到,且进行了与M3W一样的嵌入。
如图3所示,训练数据的样例。

图3 训练数据
具体来说,模型训练时,通过最小化每个数据集有权似然和负值的方式实现。
$$ \begin{aligned} \sum_{m=1}^M\lambda_{m}\cdot\mathbb{E}_{(x,y)\sim\mathcal{D}_{m}}[-\sum_{l=1}^Llogp(y_l\vert y\lt l,x\le l)] \end{aligned}\tag{2} $$
式(2)中$\mathcal{D}_m$和$\lambda_m$分别为第m个数据集和权重。调节每个数据集的权重对最终的性能很重要。作者们还发现,累积整个数据集梯度的方式更新模型,其性能优越于"round-robin"的方式。
少样本上下文学习的任务适应
模型训练完成之后,利用上下文学习评估模型快速适应新任务的能力,其提示由(image,text)或(video,text)与视觉query构成,可见图4所示。。对于模型零样本泛化能力,利用两个纯文本作为任务的提示进行探索。
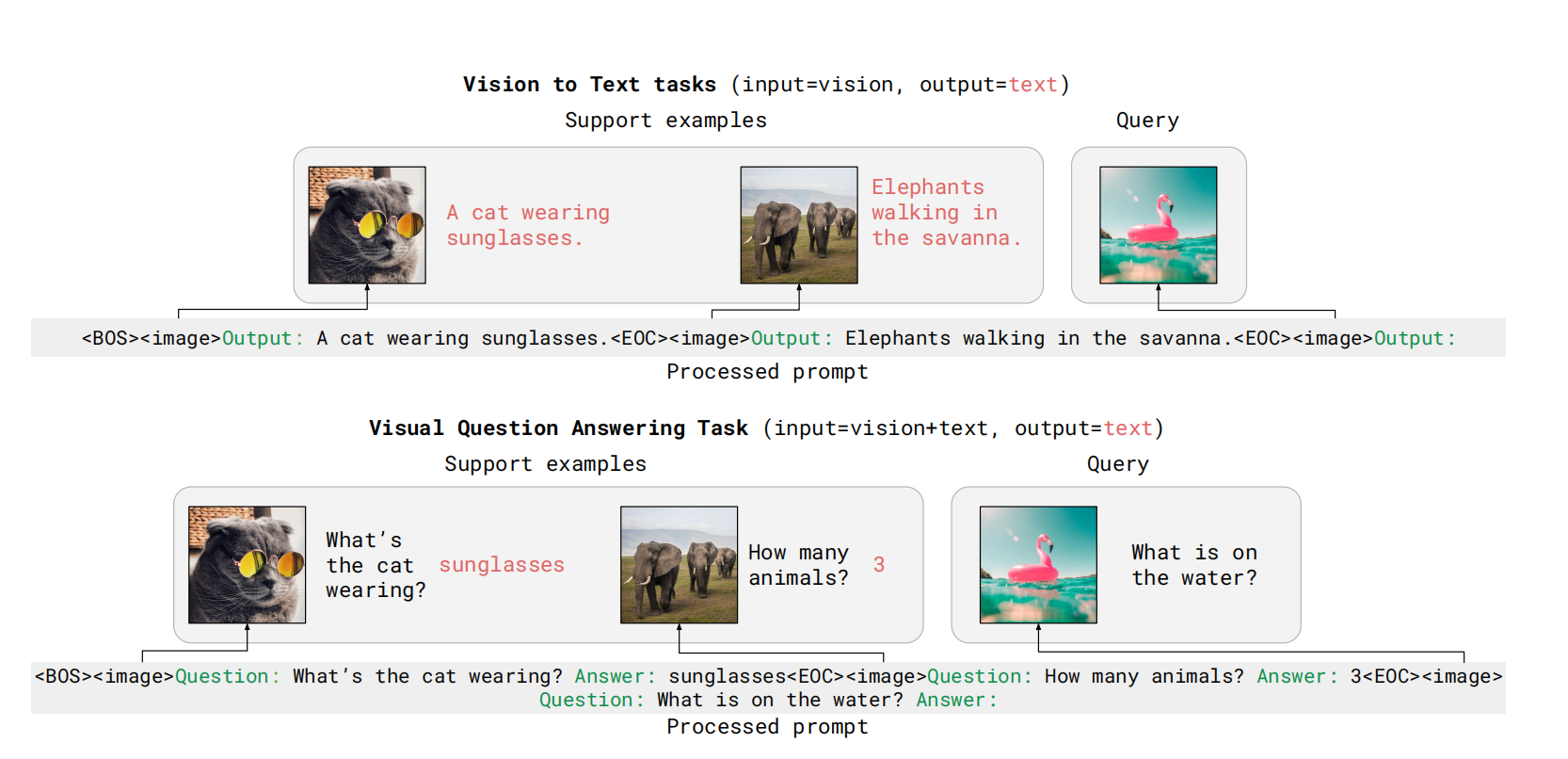
图4 上下文学习的数据
相关思考
基于Transformer Decoder架构的模型,只能输出与输入文本长度一致的文本。那么,如何才能生成变长或长度高于输入的文本呢?最终模型的生成,知识文本的生成,无视觉模态的生成。
引用方法
请参考:
li,wanye. "Flamingo:少样本学习的视觉语言模型". wyli'Blog (Mar 2024). https://www.robotech.ink/index.php/archives/299.html
或BibTex方式引用:
@online{eaiStar-299,
title={Flamingo:少样本学习的视觉语言模型},
author={li,wanye},
year={2024},
month={Mar},
url="https://www.robotech.ink/index.php/archives/299.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接