BLIP-2:基于视觉编码器和大语言模型的语言-视觉预训练
多模态模型的预训练成本越来越高,且之前的模型在对齐模态上的能力不足够,例如:Flamingo利用以视觉为条件的文本生成损失,仍不足以弥合模态之间的间隔。BLIP-2通过轻量级的Quering Transformer弥合模态之间的间隔,且经历两个阶段的预训练。第一阶段基于frozen视觉编码器进行视觉-语言表示学习,第二阶段基于frozen语言模态进行视觉语言生成学习。在性能,BLIP-2拥有少于Flamingo54倍的参数,且在VQAv2数据集表现高于Flamingo80B 8.7%。如图1所示,BLIP-2架构。
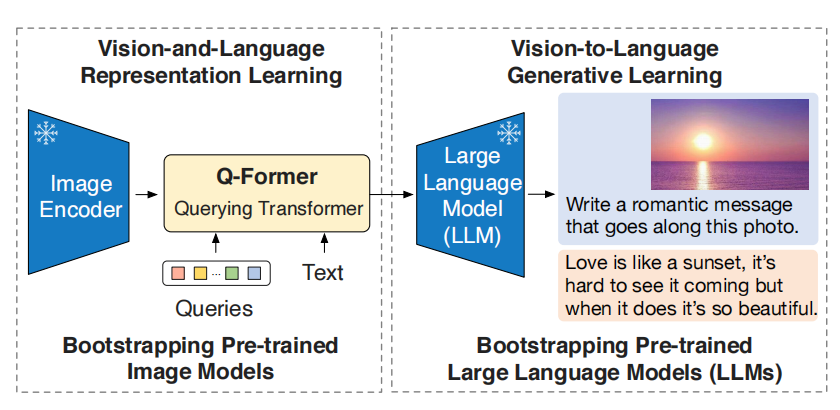
图1 BLIP-2架构
算法设计
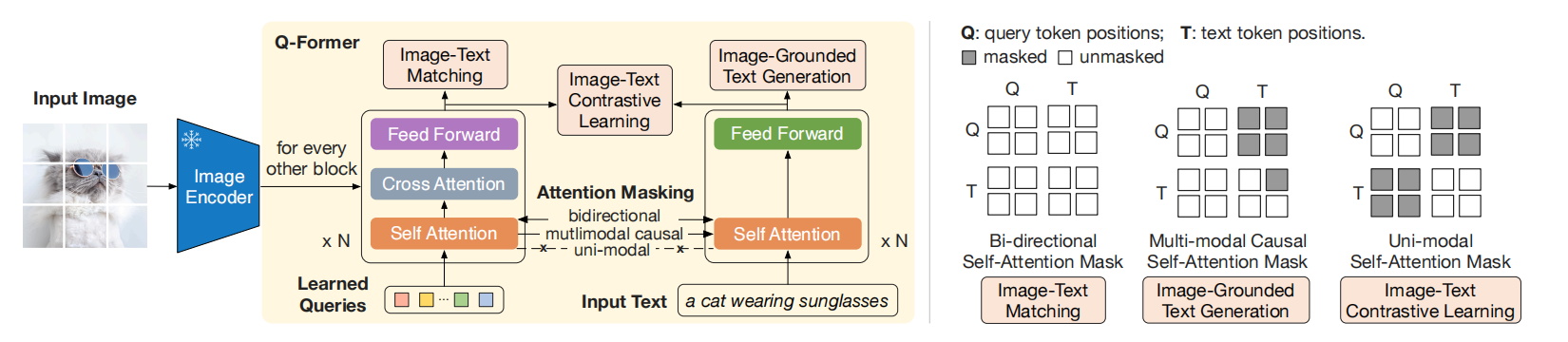
图2 (左)Q-Former架构和BLIP-2的第一阶段视觉语言表示学习。 我们共同优化三个目标,这些目标强制执行查询(一组可学习的嵌入)抽取与文本最相关的视觉表示。(右)每个目标的自注意力掩蔽策略来控制查询与文本交互。
模型架构
如图2所示,由两个transformer子模块构成,分别是:
- 与frozen图片编码器交互的transformer,用于抽取视觉特征。
- 一个文本transformer,可作为文本编码器,也可作为文本解码器。
其中,queries为可查询参数,通过交叉注意力层与图片特征交互,主要目的是学习出与文本相关的视觉表示。此外,queries还通过自注意力与文本交互。根据预训练任务的不同,通过不同的注意力掩码控制queries与文本的交互。Q-Former的自注意力模块用BERT(base)初始化,而交叉注意力随机初始化。
基于forzen图片编码器的视觉-语言表示学习
在表示学习阶段,基于图片-文本对数据对Q-Former进行预训练。在该阶段,Q-Former只与图片编码器相连接。与BLIP一致,该阶段联合优化三个目标函数,不同的目标函数在queries与文本之间有不同的掩码。接下来,分别对三个任务详细介绍。
ITC:图片-文本对比学习
通过对齐图片表示和文本表示,使两个表示之间的互信息最大化。其中,图片transformer输出表示$Z$来自于每个query,文本transformer输出文本表示$t$来自于[CLS]token。由于每个query对应一个表示$Z$,所以计算所有query输出与$t$的相似度,选择最大的作为相似度值。在该任务中,为了避免信息泄漏,采用单模态注意力机制,文本与图片之间不允许交互,可见图2所示。
ITG:基于图片的文本生成
该任务以视觉为条件生成文本。由于Q-Former不允许文本token直接与forzen的视觉编码器直接交互,所以query被迫抽取所有与文本相关的视觉信息。在query与文本token交互中采用了注意力掩码,主要目的是query不能主动与文本token交互,文本token可与query交互,从而使query被迫抽取文本相关的视觉信息,可见图2所示。
ITM:图片-文本匹配
该任务的主要目的是学习图片与文本之间更精细的对齐,这是一个二分类问题。在该任务中,query与token之间采用了双向自注意力机制。从而,图片Transformer输出的query embedding捕获了多模态信息。然后,把该embedding输入到线性二分类器中获得logit,平均化所有logit获得最终的分数。为了创建信息丰富的负样本,基于Li等人和BLIP工作中策略进行了hard负样本挖掘。
这里的多目标优化属于多任务学习,通常把多个目标函数加权求和作为损失函数。
基于frozen大语言模型的视觉-语言生成学习
如图3所示,作者们利用了全连接层把query的embedding $Z$线性投射为与文本embedding相同维度的编码。在表示学习阶段,Q-Former已经抽取了语义信息相关的视觉表示,且移除了不相关的视觉信息。因此,减少了大语言模型学习视觉-语言对齐的负担,缓和了灾难性遗忘的问题。
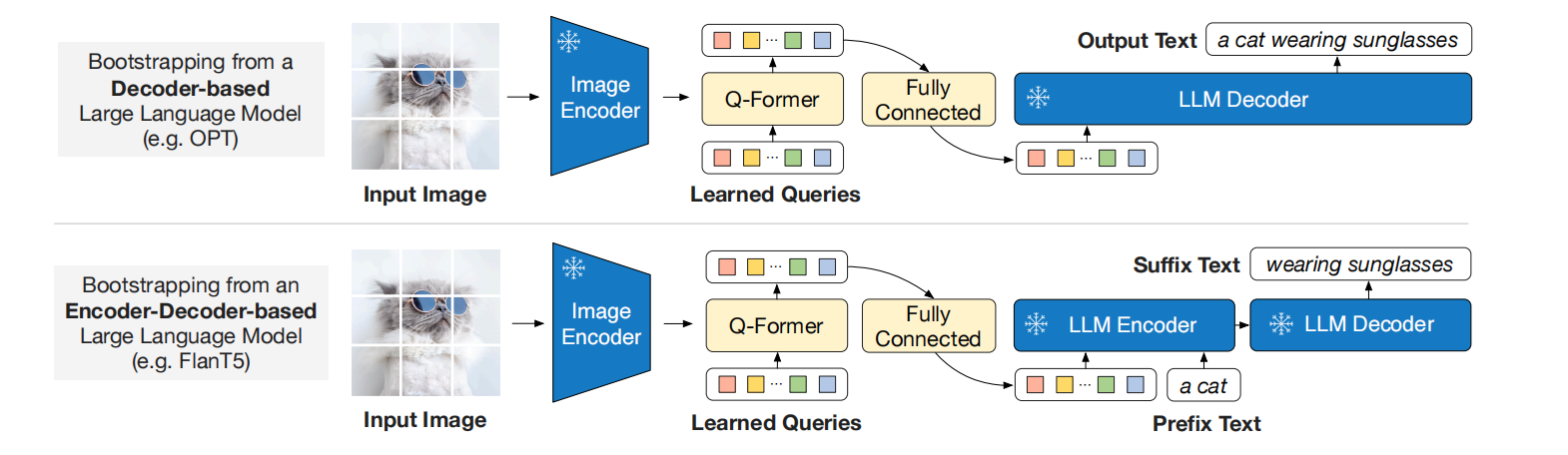
图3 Q-Former预训练的第二阶段
作者们进行了两种类型的大语言模型实验,分别是基于解码器的大语言模型和编码器-解码器的大语言模型。其中,解码器大语言模型实验中以语言建模损失为目标函数;编码器-解码器大语言模型实验中以prefix语言建模损失为目标函数,文本被分为prefix-suffix,prefix与$Z$ concat到一起输入到编码器,而suffix部分用作生成的目标。
相关思考
Q-Former的网络架构让笔者有点耳目一新,里面有Transformer架构的思想,也有Bert架构的思想。可学习的查询queries即通过交叉注意力与视觉交互,也通过自注意力与文本交互。若交叉注意力被理解为不同模态之间的交互,那么在自注意力模块中queries被看作与文本来自于相同的模态。由此,queries的主要目的是抽取与语言信息相关的视觉信息,而图片Transformer输出的embedding只含有与语言信息相关的视觉embedding。
这里的query的自注意力总感觉多余,唯一的解释无非是利用自注意力机制的特征提取能力。BLIP和BLIP-2的论文题目都提到了Bootstrapping,根据图3可知,这个词主要含义是从LLM中获取文本生成能力。
引用方法
请参考:
li,wanye. "BLIP-2:基于视觉编码器和大语言模型的语言-视觉预训练". wyli'Blog (Mar 2024). https://www.robotech.ink/index.php/archives/313.html
或BibTex方式引用:
@online{eaiStar-313,
title={BLIP-2:基于视觉编码器和大语言模型的语言-视觉预训练},
author={li,wanye},
year={2024},
month={Mar},
url="https://www.robotech.ink/index.php/archives/313.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接