PaLM-E:一个Embodied多模态语言模型
PaLM-E架构的核心思想是把连续的观测,例如:图片、状态估计、传感器数据,注入到预训练语言模型的embedding空间。这种注入的实现方式为把连续观测编码为与语言token的embedding维度相同embedding。PaLM-E是语言模型PaLM与视觉编码器的整合。如图1所示,PaLM-E的架构。
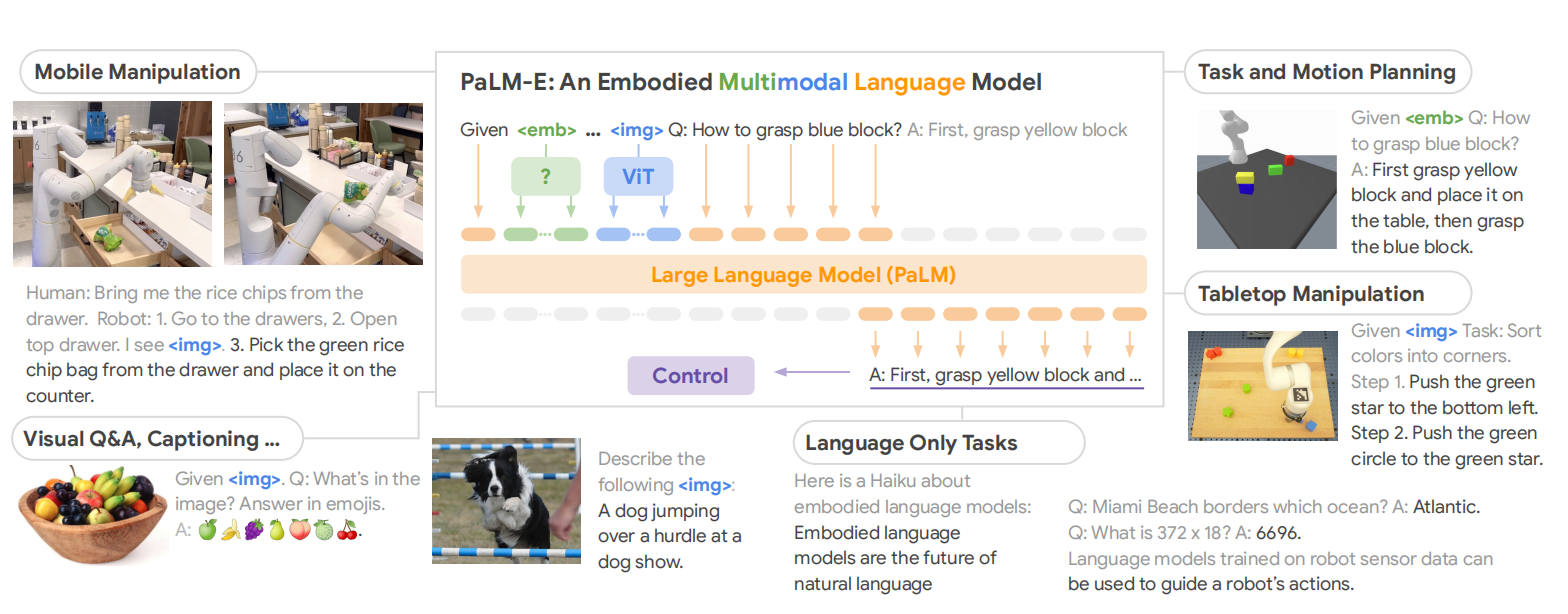
图1 PaLM-E 是一个通用的多模态语言模型,适用于具身推理任务、视觉语言任务和语言任务。PaLM-E 将视觉语言领域的知识转移到具身推理中——从在具有复杂动态和物理约束的环境中进行机器人规划,到回答有关可观察世界的问题。PaLM-E 以多模态句子(即标记序列)为对象,其中来自任意模态(例如图像、神经 3D 表示或状态,绿色和蓝色)的输入与文本标记(橙色)一起插入到 LLM 中,作为端到端训练的输入。
算法设计
若大语言模型为Decorder-only,那么建模为
$$ \begin{aligned} p(w_{1:L})=\prod_{l=1}^Lp_{LM}(w_l\vert w_{1:l-1}) \end{aligned}\tag{1} $$
若大语言模型为Prefix-decorder-only,那么建模为
$$ \begin{aligned} p(w_{n+1:L}\vert w_{1:n})=\prod_{l=n+1}^Lp_{LM}(w_l\vert w_{1:l-1}) \end{aligned}\tag{2} $$
对于连续观测,训练了一个编码器$\phi:\mathcal{O}\to\mathcal{X}^q$,把一个连续观测映射成$q$个向量。最终,这些观测embedding与文本embedding交织作为前缀。与PaLI不同,观测embeddings不会被嵌入到固定位置,而是动态的嵌入到文本。因此,不同的位置可训练不同的编码器$\phi_j$。
PaLM-E是一个产生文本的生成模型,为了把输出与embodiment相连接,区分了两种情况。若任务只是输出文本,例如:问题回答、场景描述,那么模型的输出直接被考虑为任务的解决方案。若任务是解决一个规划或控制,那么PaLM-E以低级别命令为条件输出文本,这些文本被视为高级别策略,最后由低级别策略执行。
不同传感器的输入或场景表示
不仅考虑整个场景的编码,还考虑场景中单个对象的编码。对于状态估计向量,直接通过MLP映射为embedding,用于描述场景中对象的状态。其中,状态可以包含姿势、大小、颜色等。
对于视觉信息,作者们考虑了ViT的许多变体,例如ViT-4B、ViT-22B,用于捕获语义信息。更进一步的,还研究了ViT+TL,TL为token leaner网络。最终,ViT的输出embedding通过仿射变换映射到语言模型的embedding空间。
虽然ViT编码了语义信息,但是这种表示是结构化的,类似于静态网络,而不是实例对象的集合。由于LLM是基于token学习的,所以需要区分出单个实例。作者们通过实例分割的方式获得单个对象,从ViT得到对应的编码。
对于实例编码,作者们还尝试了OSRT,该方法不需要分割图像,而是利用对象的外部知识。同时,OSRT的变体SRT还可以编码3D视觉信息。
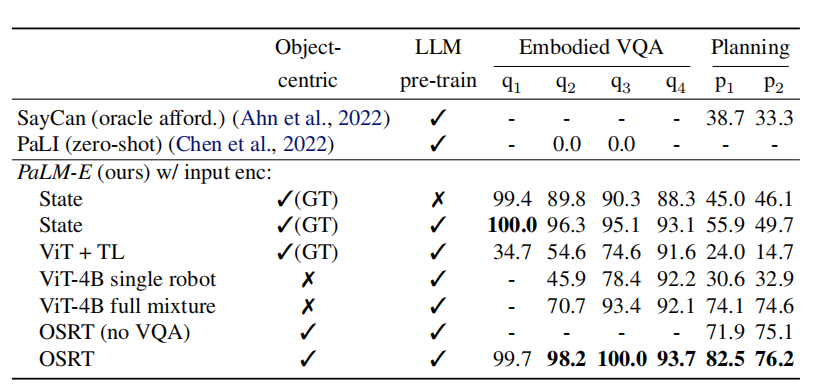
表1 不同视觉编码器在TAMP环境下的比较
模型训练
在模型训练阶段,作者们使用了跨任务的联合训练,提高了模型的迁移性。联合训练主要是指不同任务的数据集混合,用于训练。同时,基于视觉编码的训练被称为软提示,与normal软提示相关。
其中,模型训练阶段视觉编码器ViT和投射器参与训练,LLM参数被Freezing。若视觉编码器为OSRT,那么视觉编码器在训练阶段也被Freezing。
相关思考
与Flamingo和BILP-2相比,PaLM-E关注的是对视觉信息的编码。其中,Flamingo通过门控交叉自注意力层对视觉-语言进行融合,而BLIP-2提出了Q-Former对不同模态的信息进行对齐或融合。在不同模态对齐方面,PaLM-E只是通过训练投射器的方式实现。
引用方法
请参考:
li,wanye. "PaLM-E:一个Embodied多模态语言模型". wyli'Blog (Mar 2024). https://www.robotech.ink/index.php/archives/318.html
或BibTex方式引用:
@online{eaiStar-318,
title={PaLM-E:一个Embodied多模态语言模型},
author={li,wanye},
year={2024},
month={Mar},
url="https://www.robotech.ink/index.php/archives/318.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接