PaLI-X:多语言的视觉-语言模型扩展
Flamingo研究的动机是实现视觉语言模型的少样本学习;BLIP-2研究的动机是视觉与语言更精细的对齐;PaLM-E研究的动机是多模态模型适应机器人操纵任务的方法及视觉信息的编码方法。PaLI-X在PaLI模型基础之上研究视觉-语言模型的扩展和训练方法。如图1中左图所示,随着模型的扩展,PaLI模型在不同任务上性能都得到了提升,甚至超越了专业模型。同时,PaLI-X也提升了少样本微调和微调在Pareto边界上SOTA的结果,可见图1中右图所示。与PaLI相比,PaLI-X不仅扩展到更大的模型,还在多任务上同时微调。
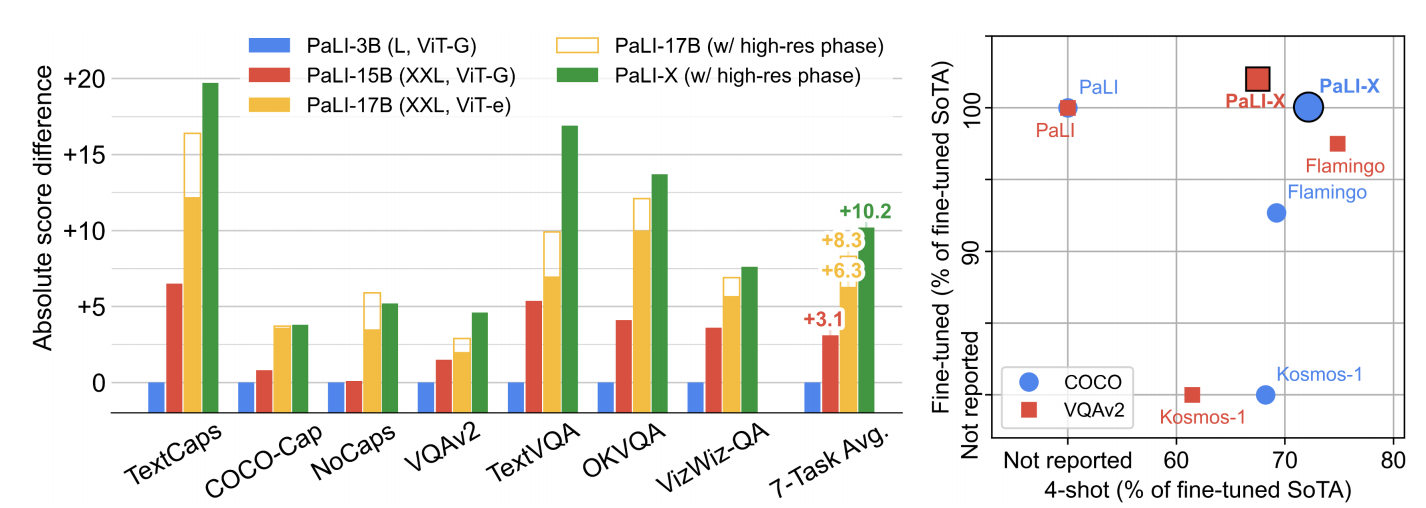
图1 [左]PaLI-X与PaLI在图片描述和VQA基准测试方面的比较。[右]PaLI-X与其它模型在少样本微调和微调帕累托边界上性能比较
PaLI-X论文的主要贡献,如下:
- 扩展的视觉语言模型在多种任务上实现了优越性能。同时,发现视觉元件和语言元件的共同扩展对模型的性能有益处,且这种扩展方法处于未饱和。
- 基于前缀-填空和掩码token填空任务相结合的混合目标训练能够显著提升少样本微调和微调在Pareto边界上SOTA的结果。
- 高容量的ViT-22B在图片分类任务和OCR标签分类任务上联合训练,能够显著提升视觉-语言任务的性能。
- PaLI-X在多任务上同时微调,能够提高模型性能。这是第一个在多任务上同时微调,且不降低性能的模型。
在详细介绍PaLM-X之前,先介绍一下上下文学习的相关工作。上下文学习首次出现于GPT3,作者们发现大语言模型只需要少量样本微调就可以在没有见过的任务上微调。之后,通过改进提示样本的方式进行上下文学习,例如:思维链、Least-to-Most提示。从Flamingo开始,基于视觉-文本交织的数据训练模型实现多模态模型的少样本微调性能。
算法设计
PaLI-X模型遵循编码器和解码器架构,图片通过ViT编码器得到Encoding。视觉编码与文本编码共同输入到encoder-decoder架构,可见图2所示。
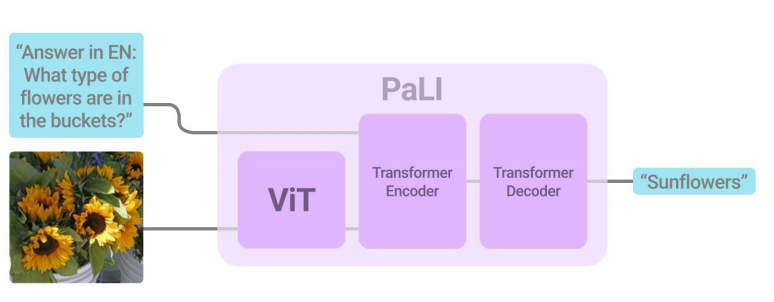
图2 PaLI-X架构
视觉编码器为22B参数的ViT,在GCP视觉接口利用OCR标注WebLI的数据集和JFT分类数据集上预训练。对于视频数据,每帧图片独立的输入到ViT,把每张图片所有patch分别进行flatten操作,然后再concat到一起,最后所有图片的embedding在时间维度上聚合。
基于UL2作为Encoder-decoder的初始架构,该模型在与UL2相似的文本混合数据上预训练。视觉编码经过映射层之后,与文本编码concat到一起输入encoder-decoder。输入模型的文本通常由一个提示构成,用于标记任务的类型和编码任务需要的文本。对于需要OCR能力的任务,作者们要么利用视觉编码器的文本编码能力,要么从上游OCR系统中抽取token作为辅助文本输入。
在少样本学习阶段,对于每个给定的目标样本都有一系列的“标记的”样本,被称为shots或exemplars。这里存在一个假设:这些exemplars包含目标样本预测所需要的信息。简单来说,与大语言模型的指令微调数据格式相似,把exemplars与目标样本共同输入模型预测目标样本的答案。同时,作者们还进行了两个优化,一个是exemplars在编码器和解码器之间的分布,另一个是注意力重新加权的机制。
预训练数据与Miture
预训练数据主要是基于WebLI的10B图片数据,且被网页和文本标注,覆盖100种语言。同时,还创建了Episodic WebLI数据,每episode对应于图片-文本对的集合。这种数据是根据URL域进行聚合得到,从而鼓励模型注意一个"episode"中样本。最终,发现这些数据对提升模型的少样本学习能力很重要。预训练数据还有一份mixture,它由VTP、VQA-CC3M等数据构成。
模型训练
模型训练分为两个阶段。在阶段一,视觉编码器被forzen,模型的其它参数在所有Mixture数据上训练,且图片的分辨率固定为$224\times224$。在阶段二,只利用OCR相关的目标和目标检测的目标继续训练模型,且在该期间图片的分辨率逐渐增加,从而进行多阶段训练。
相关思考
总的来说,大模型backbone架构方面都是基于Transformer,模态之间融合的架构会有些许不同,例如:BLIP-2利用Q-Former进行融合、Flamingo利用Gated交叉自注意力层进行融合。接下来,就是训练数据和训练方式的差别了。
引用方法
请参考:
li,wanye. "PaLI-X:多语言的视觉-语言模型扩展". wyli'Blog (Mar 2024). https://www.robotech.ink/index.php/archives/321.html
或BibTex方式引用:
@online{eaiStar-321,
title={PaLI-X:多语言的视觉-语言模型扩展},
author={li,wanye},
year={2024},
month={Mar},
url="https://www.robotech.ink/index.php/archives/321.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接