MAE:掩码自编码是可扩展的视觉学习器
深度学习在硬件的发展下,模型越做越大,但也需要越来越多的数据。然而,标注数据的成本是很高的。在自然语言处理领域,基于自回归和自编码无监督训练的方式,解决数据少的问题。与之相对的,计算机视觉领域的掩码自编码技术发展的很缓慢。MAE作者们对这种不同的原因进行了分析,结果如下:
- 语言与视觉的信息密度不同。语言是人类创造的,拥有高度的语义和信息密度。在训练模型预测句子中丢失单词时,该任务似乎已到模型学习复杂的语言理解。然而,图片来自于自然界,拥有很强的冗余性,例如:丢失的部分可被邻居部分再次恢复,甚至直接都能被识别。
自编码器的解码器映射隐式表示到输入,对于图片来说这种映射输出是低语义的,对语言来说这种映射输出是有丰富语义的。然而,BERT基于编码器就能学习到很丰富的语义信息,MAE需要编码器和解码器才能学习到丰富的语义。
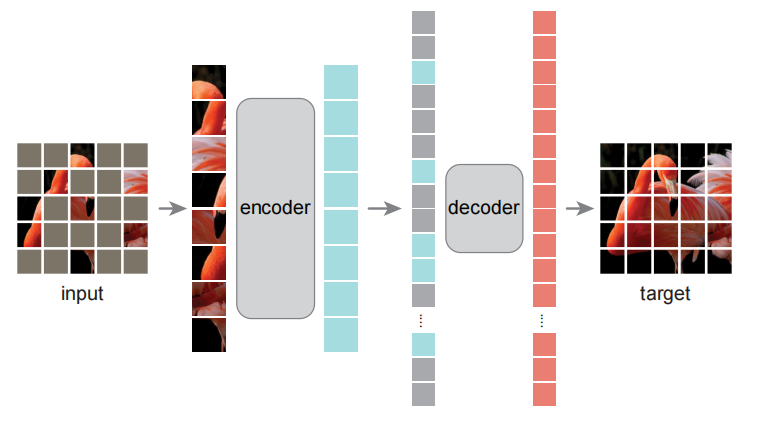
图1 MAE架构
算法设计
MAE采用了异步的编码器和解码器设计,编码器对部分观测进行编码,轻量级解码器基于隐表示和掩码进行重建。如图1所示,MAE架构。
掩码:与ViT一致,图片被分散为一系列互不重叠的patches,然后采样出一个子集,其余部分为掩码。其中,采样方式为均匀采样。为了消除信息的冗余性,利用了较高的掩码率。
编码器:与ViT一致,无掩码的patches与位置编码输入到编码器获得编码。由于掩码比率较高,所以输入编码器的数据相较于ViT较少,所以MAE的编码器对算力和内存的需求较少。
解码器:解码器以无掩码patches的编码、掩码token及其位置编码作为输入。如图1所示,每个掩码token是一个共享的和可学习的向量,用于表示丢失patches的存在。MAE的解码器只在预训练阶段使用,因此解码器的设计独立于编码器,常常设计小的解码器降低计算量和内存的需求。
目标重建:解码器的最后一层为线性映射层,其输出通道为每个patch中像素值的个数,损失函数重建像素与原始像素值之间的MSE。
相关思考
MAE论文中分析了视觉与语言的不同,提到视觉信息来源于自然界,相较于人为的语言信息有很多的冗余信息。与其说有更多的冗余信息,不如说人认识世界是离散的,例如:草坪上有只狗,我们更多关注的是狗而非其背景。若站在语义的角度,图片拥有很多低语义信息则只是基于编码器很难学习到语义信息,而语言几乎每个单词都有强的语义性则只基于编码器就能学习到语义知识。
引用方法
请参考:
li,wanye. "MAE:掩码自编码是可扩展的视觉学习器". wyli'Blog (Mar 2024). https://www.robotech.ink/index.php/archives/331.html
或BibTex方式引用:
@online{eaiStar-331,
title={MAE:掩码自编码是可扩展的视觉学习器},
author={li,wanye},
year={2024},
month={Mar},
url="https://www.robotech.ink/index.php/archives/331.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接