MobileVLM:移动设备的视觉语言助手
MobileVLM是第一个开放的、移动规模的视觉语言模型,且模型是基于开放数据集训练的。该篇论文主要贡献如下:
- 第一个详细的、可复制的、性能优越的视觉语言模型,应用于移动设备场景。
- 在视觉编解码器设计和系统性评估视觉语言模型对训练范式、输入分辨率、以及模型大小敏感性的消融实验。
- 在视觉与文本特征之间设计了高效投射器,不仅更好的对齐了多模态特征,且减少了推理成本。
MobileVLM可在移动和低成本设备上高效运行,其在Qualcomm移动CPU上推理速度21.5token/s,在Jetson Orin GPU上推理速度为65.3 token/s。
算法设计
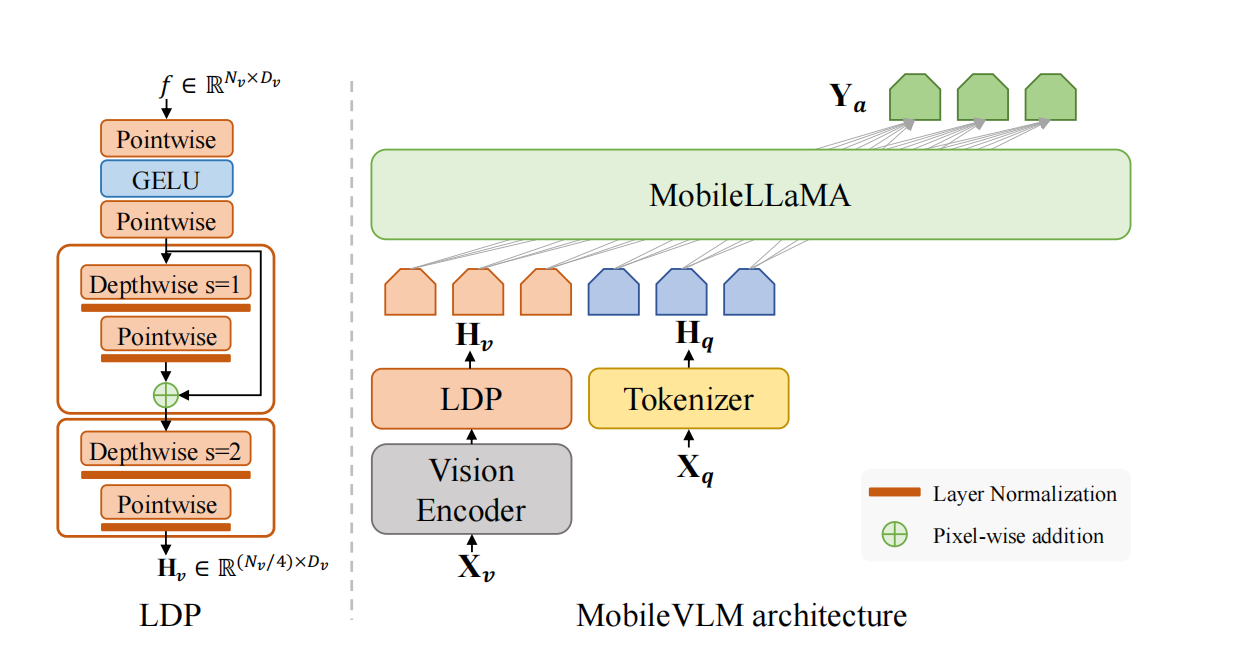
图1 MobileVLM架构
在图1中,Pointwise被称为逐点卷积;而Depthwise被称为深度卷积。其中,逐点卷积与常规卷积一致,只是卷积核大小为$1\times 1\times M$,$M$表示输入通道数。与常规卷积操作不同(可见图2所示),深度卷积的每个卷积核只对单个通道进行卷积,即没有通道间求和的运算,形成的通道数与输入通道数一致。逐点卷积可用于扩展通道或压缩输入通道;深度卷积和逐点卷积均可用于减少了参数量。

图2 卷积运算示意图
如图2所示,常规卷积运算示意图。具体来说,其计算方法为
$$ \begin{aligned} \mathbf{Z}^p=\mathbf{W}^p\otimes\mathbf{X}+b^p=\sum_{d=1}^D\mathbf{W}^{p,d}\otimes\mathbf{X}^d+b^p \\ \mathbf{Y}^p=f(\mathbf{Z}^p) \end{aligned} $$
架构设计
如图1所示,MobileVLM由三个组件构成,分别是:
- 视觉编码器
- 适用于边缘设备的LLM
- 高效的投射器LDP,用于对齐视觉-文本空间
$\mathbf{X}_v\in\mathbb{R}^{H\times W\times C}$表示输入的图片,视觉编码器$\mathbf{F}_{enc}$抽取视觉特征$f\in\mathbb{R}^{N_{v}\times D_{v}}$。其中,$N_v=\frac{HW}{P^2}$表示图片patches的数量,$D_v$指示视觉embedding的隐藏层大小。投射器$\mathbf{P}$把视觉特征压缩且投射到文本embedding空间,即
$$ \begin{aligned} \mathbf{H}_v=\mathbf{P}(f),f=\mathbf{F}_{enc}(\mathbf{x}_v) \end{aligned}\tag{1} $$
视觉tokens$\mathbf{H}_v\in\mathbb{R}^{(N_v/4)\times D_t}$和文本tokens$\mathbf{H}_q\in\mathbb{R}^{N_t\times D_t}$输入到LLM,预测响应$\mathbf{Y}_a=\{y_i\}_{i=1}^L$,此过程被描述为
$$ \begin{aligned} p(\mathbf{Y}_a\vert\mathbf{H}_v,\mathbf{H}_q)=\prod_{i=1}^Lp(y_i\vert\mathbf{H}_v,\mathbf{H}_q,y\lt i) \end{aligned}\tag{2} $$
视觉编码器:预训练CLIP的ViT-L/14。
MobileLLaMA
对于语言模型,作者们利用了参数量较小的LLaMA,被称为MobileLLaMA,从而有利用部署。大语言模型架构的设计可见表1所示。
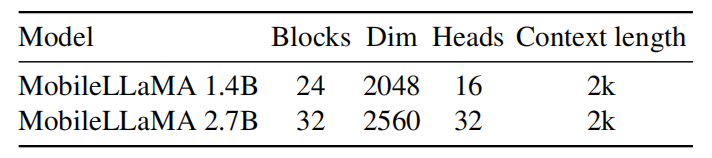
表1 大语言模型的架构设置
确切来说,大语言模型使用了SentenPiece作为tokenizer,且embedding从头开始训练,这种方式有益于模型蒸馏。在预训练阶段,由于计算资源的限制,所有模型的上下文长度被限制为2k。然而,根据Chen等人工作上下文长度可被进一步扩展到8k。其它元件的设置如下:
高效的投射器
视觉编码与语言模型之间的投射器存在两种范式,分别是Q-Former和MLP。其中,Q-Former能够控制每个query中视觉token的数量,从而抽取最相关的视觉信息。然而,Q-Former损失了位置信息且拟合速度慢,也无法在边缘设备上高效推理。与之相对的,MLP保留了空间位置信息,但包含了无用的视觉信息。受到CPVT的启发,利用卷积增强模型的位置信息。同时,视觉tokens之间也可进行局部交互。确切的说,利用步长为2的depth-wise convolution作为卷积运算,从而对视觉tokens进行下采样以提高效率。然而,这种下采样破坏下游任务的性能。因此,作者们设计了性能优越的轻量级下采样投射器LDP代替单个位置编码生成器PEG,可见图1所示。最终,LDP模块有20M参数,推理速度高于视觉编码器81倍。
为了提高训练稳定性且不影响batch大小,利用了Layer Normalization。由于投射器已经非常轻量化,所以没有采用RepVGG和MobileOne最新的移动重参数化设计。
引用方法
请参考:
li,wanye. "MobileVLM:移动设备的视觉语言助手". wyli'Blog (Mar 2024). https://www.robotech.ink/index.php/archives/328.html
或BibTex方式引用:
@online{eaiStar-328,
title={MobileVLM:移动设备的视觉语言助手},
author={li,wanye},
year={2024},
month={Mar},
url="https://www.robotech.ink/index.php/archives/328.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接