CPVT:ViT的条件位置编码
在ViT中,可学习的绝对位置编码限制了模型输入序列的长度。同时,由于位置编码向量的唯一性造成模型不具有平移等变性。若直接抛弃掉位置编码,反而导致模型的性能降低;若对位置编码进行插值,从而处理更长的输入序列,则需要在下游任务中模型微调才能拥有较好的性能;若利用相对位置编码,因无法提供绝对位置信息导致性能略差于绝对位置编码。CVPT的作者们认为:视觉任务中成功的位置编码应满足:
- 可使输入序列拥有序列不变性,且偏向于平移等变性。
- 能够处理比训练数据中更长的序列。
- 拥有提供绝对位置信息的能力。
条件位置编码
作者们发现,利用位置编码描述局部关系,足以满足以上三个要求。首先,虽然输入数据的序列影响局部关系,但是对象的平移不响应局部关系。其次,由于每个token只增加局部位置信息,所以很容易泛化到更长序列。最后,若只要有一个输入token的绝对位置可知,那么其它输入token的绝对位置可通过相互关系推断出来。在视觉领域,零填充可作为绝对位置信息,从而模型可推断每个token的绝对位置。
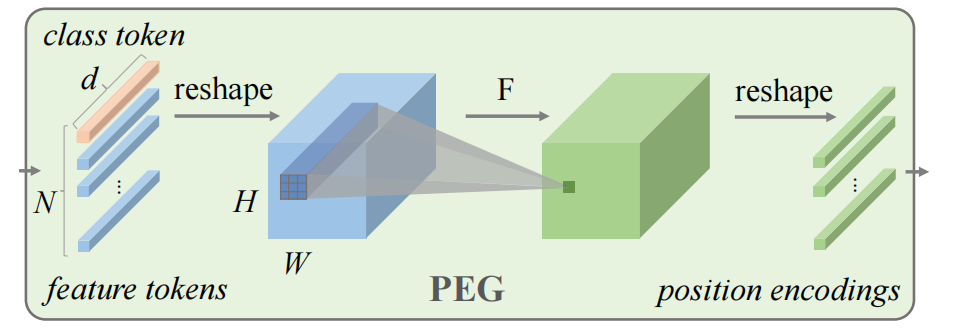
图1 PEG原理图
由此,作者们提出了位置编码生成器PEG,以输入token的局部邻居为条件动态的生成位置编码,可见图1所示。确切的说,PEG先把flatten后的DeiT输入序列$X\in\mathbb{R}^{B\times N\times C}$变形为${X}'\in\mathbb{R}^{B\times H\times W\times C}$。接下来,函数$\mathcal{F}$被重复利用在${X}'$的局部patch,产生条件位置编码$E^{B\times H\times W\times C}$。在PEG中,函数$\mathcal{F}$通常为卷积,其核大小为$k(k\ge3)$,且进行$\frac{k-1}{2}$的零填充。
条件位置编码ViT
如图2.b所示,基于条件位置编码,作者们提出了CPVT。其中,PEG加入的位置对模型性能影响很大,可见论文中相关实验。在分类任务上,图2.a和图2.b均利用cls_token作为可学习的分类token。然而,cls_token不具有平移等变性,可直接利用全局平均池化GAP代替,可见图2.c所示。
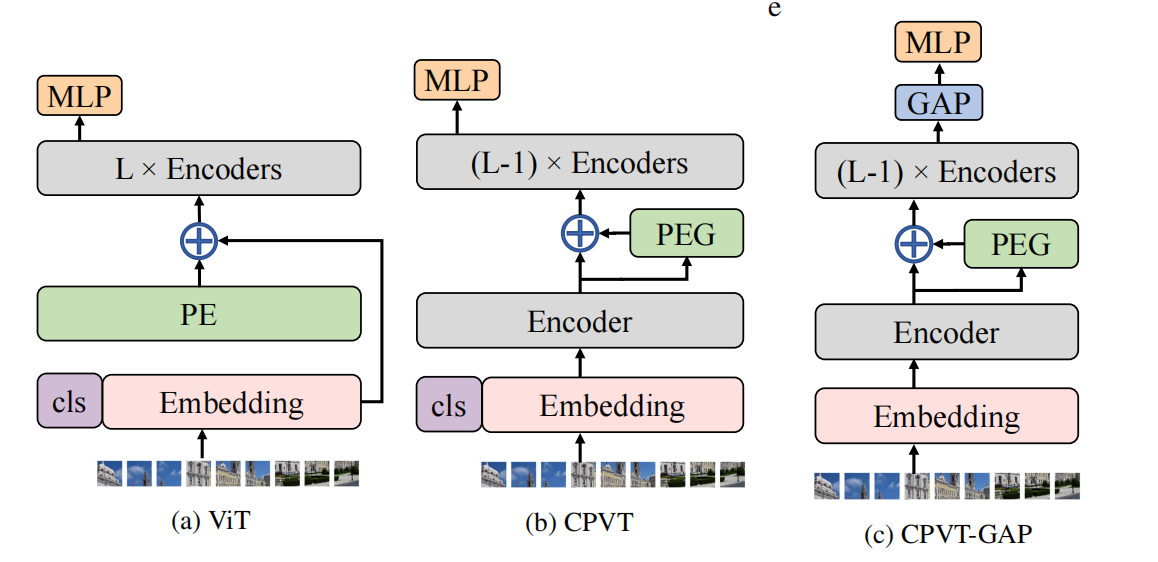
图2 ViT与位置编码的结合
引用方法
请参考:
li,wanye. "CPVT:ViT的条件位置编码". wyli'Blog (Apr 2024). https://www.robotech.ink/index.php/archives/378.html
或BibTex方式引用:
@online{eaiStar-378,
title={CPVT:ViT的条件位置编码},
author={li,wanye},
year={2024},
month={Apr},
url="https://www.robotech.ink/index.php/archives/378.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接