VoxPoser:利用大语言模型为机器人操作创建可组合的3D价值地图
语言是一个被压缩的媒介,人类通过它提炼与交流对世界的知识与经验。大语言模型作为捕获这种抽象的有前景的方式,通过把世界投射到语言空间从而学习表示世界。同时,大语言模型非常擅长推断语言为条件的affordance和约束。由此,VoxPoser作者们利用大语言模型的写代码能力,创建了稠密的3D体素网格地图,且通过协调感知模块把这些信息放入到视觉空间。然后,再把价值地图视作直接合成机器人轨迹的规划器的目标函数。简单来说VoxPoser从LLMs中抽取affordances与约束,用于在观测空间中创建3D价值地图,从而引导机器人交互。
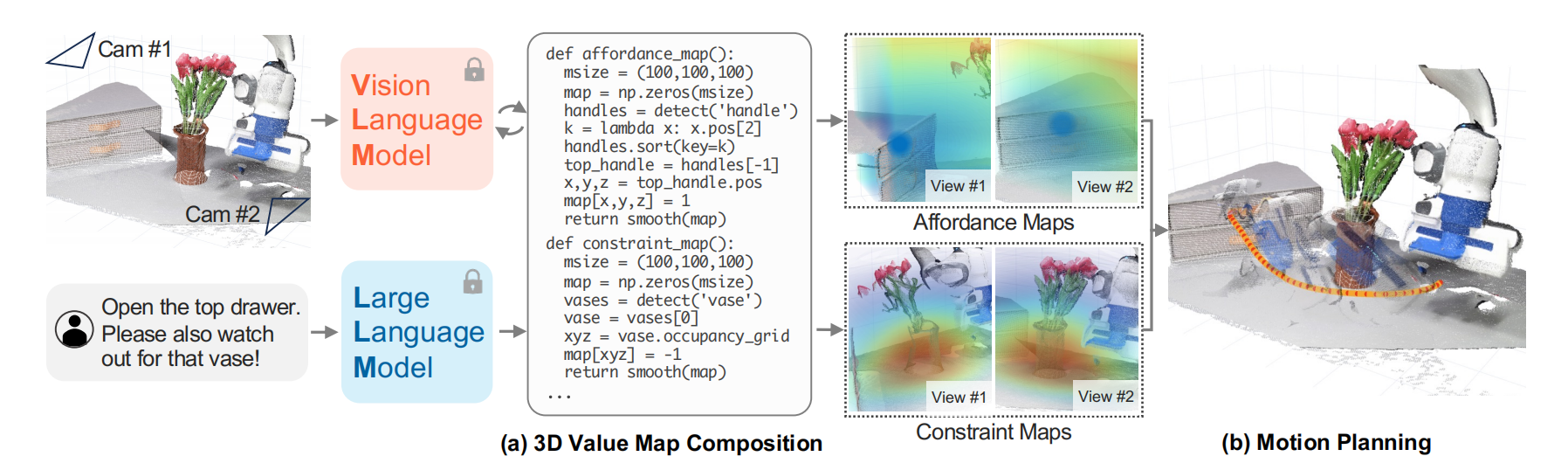
图1 VoxPoser概览
算法设计
考虑由自然语言指令$\mathcal{L}$确定的操作问题,该问题可被分解成子问题$\mathcal{L}\to(\mathcal{l}_1,\mathcal{l}_2,\ldots,\mathcal{l}_n)$,且每个子问题可确定一个可操作的任务。作者们所要研究的问题是对于机器人$\mathbf{r}$为任务$\mathcal{l}_i$生成运动轨迹$\tau_i^{\mathbf{r}}$。其中,$\tau_i^{\mathbf{r}}$被表示为一个稠密的末端执行器waypoints数组,且每个waypoint由期望的6-DoF末端执行器位姿、末端执行器速度、以及夹抓动作构成。由此,对于给定子任务$\mathcal{l}_i$,该优化问题为
$$ \begin{aligned} \underset{\tau_i^r}{min}\{\mathcal{F}_{task}(\mathbf{T}_i,l_i)+\mathcal{F}_{control}(\tau_i^r)\}\quad subject\quad to\quad\mathcal{C}(\mathbf{T}_i) \end{aligned}\tag{1} $$
式(1)中$\mathbf{T}_i$为环境状态的演化;$\tau_i^{\mathbf{r}}\subseteq\mathbf{T}_i$为机器人轨迹;$\mathcal{F}_{task}$用于估计$\mathbf{T}_i$完成指令$\mathcal{l}_i$的程度;$\mathcal{F}_{control}$用于确定控制成本;$\mathcal{C}(\mathbf{T}_i)$指示运动学与动力学约束。
理解语言指令
大量的任务可被观测空间中一个体素价值地图$\mathbf{V}\in\mathbb{R}^{w\times h\times d}$所表示,用于引导场景中“感兴趣实体”的运动,例如:末端执行器、一个对象、或对象的部分。例如:考虑“打开顶层抽屉”的任务,那么由大语言模型推断出它的第一个子任务是“抓取抽屉的把手”,可见图1所示。该任务的“感兴趣实体”是末端执行器,体素价值地图应该反应出吸引末端执行器向抽屉把手运动。通过进一步的命令“注意花瓶”,那么地图应反应出对花瓶的排斥。若利用$\mathbf{e}$表示“感兴趣实体”、$\tau^{\mathbf{e}}$表示它的轨迹,那么$\mathcal{F}_{task}$通过累积末端执行器$\mathbf{e}$穿越指令$\mathcal{l}_i$的价值地图$\mathbf{V}_i$的值所近似,即$\mathcal{F}_{task}=-\sum_{j=1}^{\vert\tau_i^{\mathbf{e}}\vert}\mathbf{V}(p_j^{\mathbf{e}})$,其中$p_j^{\mathbf{e}}\in\mathbb{N}^3$为$\mathbf{e}$在阶段$j$的位置$(x,y,z)$。
作者们发现,通过互联网规模的数据预训练大语言模型,使其不仅仅展现识别“感兴趣实体”的能力,且可通过写Python程序的方式创建反应任务指令的价值地图。确切的说,若指令被给定作为代码中的评论,那么大语言模型可被提示调用感知模块获得相关物品的空间-几何信息,也可被用于生成Numpy运算用于操作3D数组,也可以规定相关位置精确的值,即价值地图$\mathbf{V}_i^t=VoxPoser(\mathbf{o}^t,l_i)$。其中,$\mathbf{o}^t$为时刻$t$的RGB-D观测,$l_i$为当前指令。由于生成的$\mathbf{V}$为稀疏的,所以通过平滑运算稠密化voxel地图。
其它轨迹参数化:利用LLMs创建的价值地图$\mathbf{V}:\mathbb{N}^3\to\mathbb{R}$用于优化路径。同时,还在任务相关目标上创建了旋转地图$\mathbf{V}_r:\mathbb{N}^3\to SO(3)$,还创建了夹抓地图$\mathbf{V}_g:\mathbb{N}^3\to\{0,1\}$用于控制夹抓的状态以及速度地图$\mathbf{V}_v:\mathbb{N}^3\to\mathbb{R}$用于确定目标速度。
零样本轨迹合成
在获得任务成本$\mathcal{F}_{task}$之后,可利用式(1)解决整个问题。作者们通过随机采样轨迹的方式进行简单的零级优化,且利用提出的目标函数打分。该优化步骤在MPC框架下实施:基于每一步的当前观测重新规划轨迹。最终,作者们发现整个系统可实现大量的操纵任务。同时,由于价值地图的定义是关于“感兴趣实体”,因此会产生不必要的轨迹,作者们利用动力学模型寻找最小化任务成本的必要轨迹。
基于线上经验的高效动态学习
虽然VoxPoser为合成机器人操作轨迹的零样本框架,但是它也通过学习动力学模型受益于线上经验。确切的说,分为如下两个步骤:
- 收集环境转换数据$(\mathbf{o}_t,\mathbf{a}_t,\mathbf{o}_{t+1})$,$\mathbf{o}_t$为环境观测,$\mathbf{a}_t=MPC(\mathbf{o}_t)$
- 利用下一时刻预测的观测$\hat{\mathbf{o}}_{t+1}$与真实观测$\mathbf{o}_{t+1}$之间的$L_2$损失训练动力学模型$g_{\theta}$
两个步骤不断迭代训练动力学模型。
在MPC中动作的采样分布$P(\mathbf{a}_t\vert\mathbf{o}_t)$对学习效率很重要。然而,对于一个特定任务,由于动作不与场景中相关对象交互,或不进行有意义的交互,从而导致不高效。因此,作者们利用合成轨迹$\tau^{\mathbf{r}}_0$作为先验,即动作分布为$P(\mathbf{a}_t\vert\mathbf{o}_t,\tau_{0}^{\mathbf{r}})$。同时,为了鼓励局部探索对轨迹$\tau^{\mathbf{r}}_0$增加了随机噪音。
相关思考
综上所属,VoxPoser主要利用大语言模型对世界的理解与知识增强机器人的操作能力,从而使其能够基于开放指令对开放对象集执行动作的能力。其中,主要利用了大语言模型基于语言指令推断affordances与约束的能力。
引用方法
请参考:
li,wanye. "VoxPoser:利用大语言模型为机器人操作创建可组合的3D价值地图". wyli'Blog (Apr 2024). https://www.robotech.ink/index.php/archives/418.html
或BibTex方式引用:
@online{eaiStar-418,
title={VoxPoser:利用大语言模型为机器人操作创建可组合的3D价值地图},
author={li,wanye},
year={2024},
month={Apr},
url="https://www.robotech.ink/index.php/archives/418.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接