SayCan:机器人Affordances中的基础语言模型
大语言模拥有大量来自互联网文本语料的知识。然而,这些知识无法直接被具身智能体所使用。这是因为大语言模型不是建立在物理世界之上的,也无法观测它的生成对物理世界的影响。SayCan作者研究了为机器人从大语言模型中抽取知识,从而跟随指令的方法。其中,机器人拥有完成低级控制任务的技能库。具体来说,不仅利用LLMs解释指令,而且用于估计单个技能对完成高级别指令的可能性。若每个技能都有一个affordance函数,用于描述每个技能成功的概率,那么LLMs与affordance函数的相结合可估计每个技能完成指令成功的概率。其中,affordance函数使LLM意识到当前场景,也意识到机器人的能力边界。同时,这种方式可产生一个可解释的机器人完成指令执行的序列步骤。
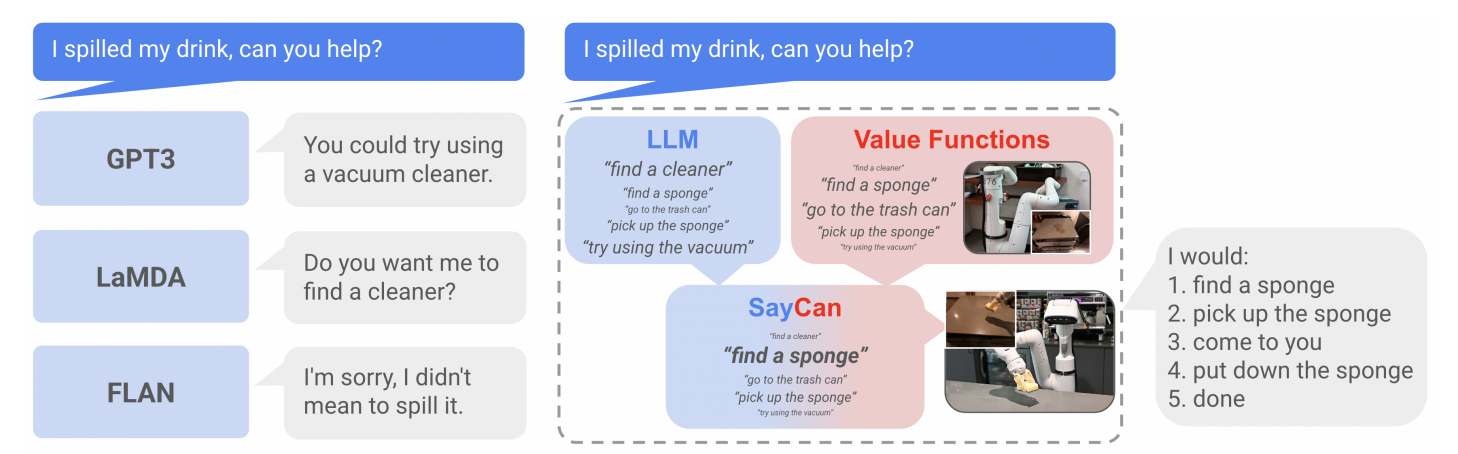
图1 大语言模型与SayCan的对比
算法设计
系统收到用户的自然语言指令$i$,用于描述机器人应该执行的任务。该指令的特点是长的、抽象、或模糊的。机器人拥有一个技能库$\Pi$,每个技能$\pi\in\Pi$执行一个短任务,例如:拿起一个特定物品,且有一个短的语言描述$l_{\pi}$与affordance函数$p(c_{\pi}\vert s,l_{\pi})$,该函数用于表示从状态$s$完成带有描述$l_{\pi}$的技能的概率。在RL术语中,若对于成功完成奖励为1而其它为0,那么affordance函数为技能的价值函数。
对于以上描述,LLM提供$p(l_{\pi}\vert i)$,用于描述技能文本标签属于用户指令有效下一步的概率。那么,给定技能对完成用户指令$i$的概率$p(c_i\vert i,s,l_{\pi})\propto p(c_{\pi}\vert s,l_{\pi})p(l_{\pi}\vert i)$。因此,给定指令$i$技能语言描述的概率$p(l_{\pi}\vert i)$可被认为对任务理解,在当前世界状态下技能完成的概率$p(c_{\pi}\vert s,l_{\pi})$可被认为对世界理解。

图2 价值函数模块
连接大语言模型与机器人
大语言模型生成的文本,要么无法被机器人执行,要么属于不必要的动作。虽然基于提示工程可诱导语言模型的输出格式,但是也往往产生不容易被解析成单个步骤用于执行。因此,作者们对语言模型的输出进行了改变。通常情况下,一个语言模型预测的是下一个词$w_k$出现在第$k$个位置的概率$p(w_k\vert w_{\lt k})$。作者们直接把大语言模型用于预测对一个技能描述库中每个技能被选择概率$p(l_{\pi}\vert i)$,选择最优技能。一旦技能选定之后,技能与指令concat到一起进行下一次预测。具体过程,可见图3与算法1所示。
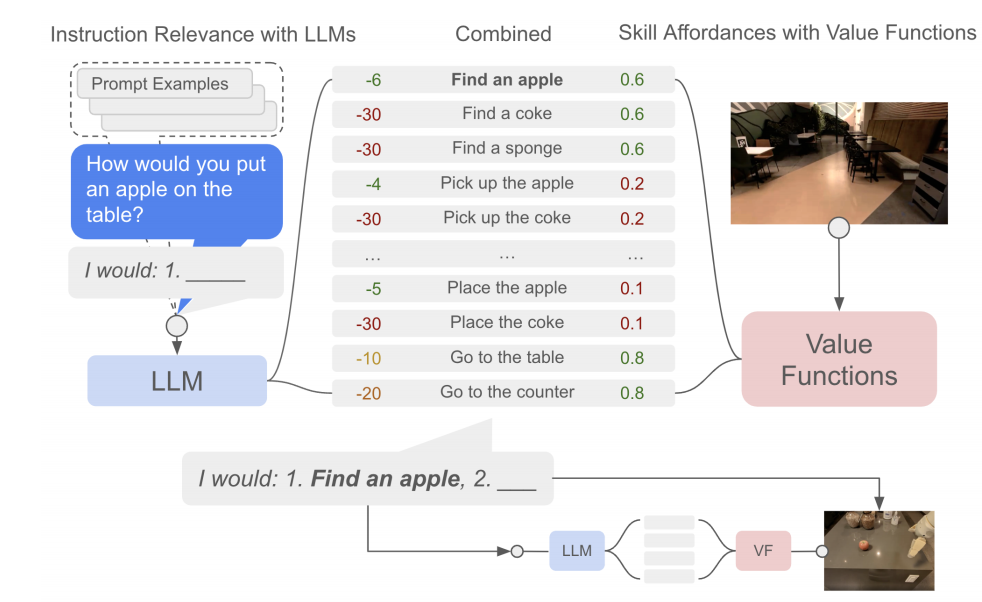
图3 SayCan的执行方法
在图3中价值函数基于RL范式通过机器人与环境交互学习得到,也被称为affordance函数。因此,价值函数空间捕获了所有技能的affordances,可见图2所示。

SayCan在机器人系统中实现
对于SayCan的实现,需要提供技能库、每个技能的策略、价值函数、以及简单的语言描述。对于单个技能,作者们要么利用行为克隆算法BC-Z获得获得,要么RL算法MT-Opt获得。对于价值函数,通过优化TD-backup损失$L_{TD}(\theta)=\mathbb{E}_{(s,a,{s}'\sim\mathcal{D})}[R(s,a)+\gamma\mathbb{E}_{{a}^{*}\sim\pi}Q^{\pi}_{\theta}({s}',a^{*})-Q^{\pi}_{\theta}(s,a)]$的方式获得。为了分摊训练许多技能的成本,作者们还利用了多任务BC与多任务RL。其中,BC-Z的网络架构可见图4所示,MT-Opt的网络架构可见图5所示。为了使策略能够以语言为条件,利用句子编码器获得描述的embeddings,作为策略和价值函数的输入。MT-Opt算法在Everyday Robots仿真环境中训练完成之后,利用了RetinaGAN的sim-to-real迁移作为策略的初始化,也利用线上数据进行了微调。
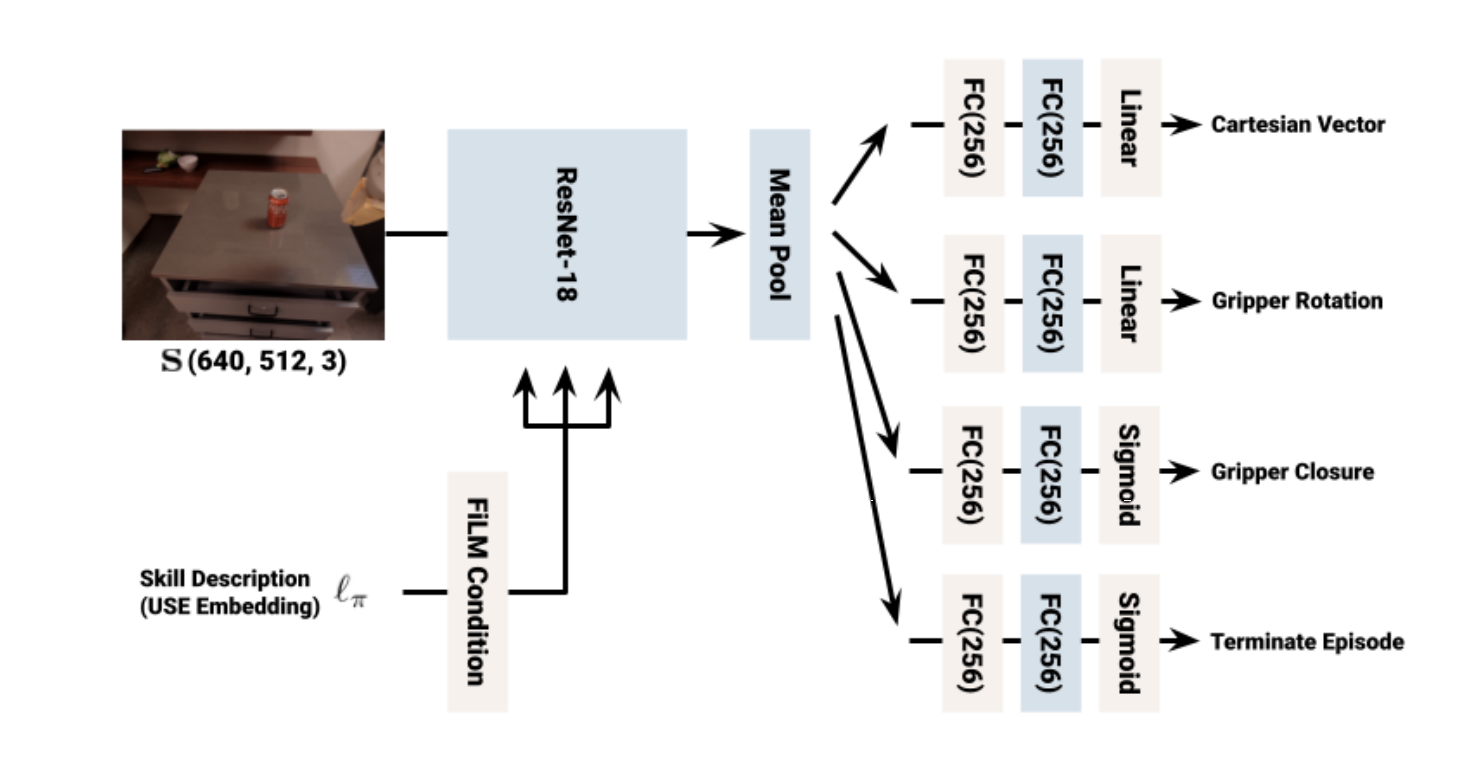
图4 BC策略的网络架构
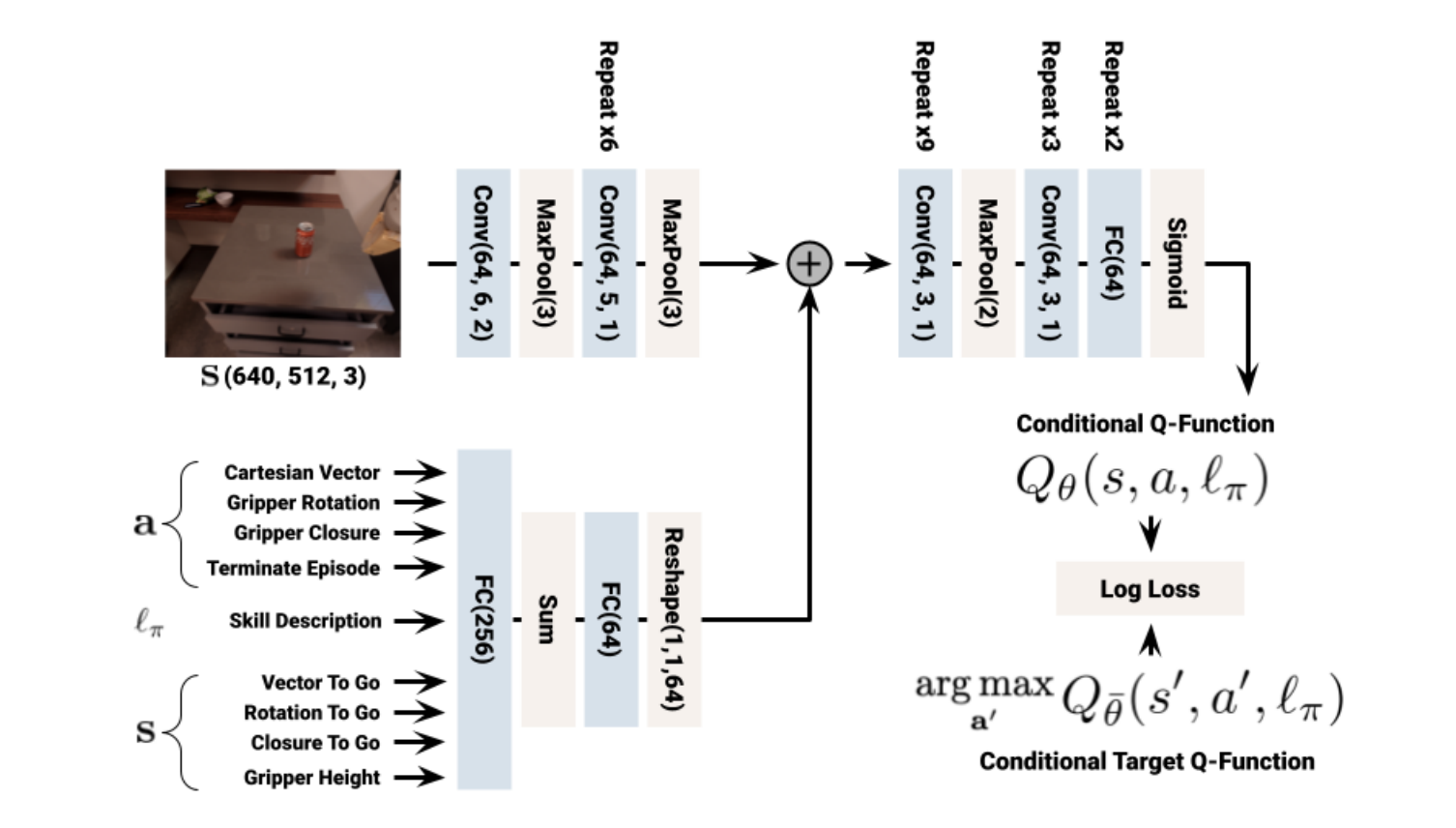
图5 RL策略的网络架构
相关思考
与VoxPoser相比,SayCan需要先定义一个技能库,因此无法处理开放场景的操作任务。
引用方法
请参考:
li,wanye. "SayCan:机器人Affordances中的基础语言模型". wyli'Blog (Apr 2024). https://www.robotech.ink/index.php/archives/420.html
或BibTex方式引用:
@online{eaiStar-420,
title={SayCan:机器人Affordances中的基础语言模型},
author={li,wanye},
year={2024},
month={Apr},
url="https://www.robotech.ink/index.php/archives/420.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接