VRB:从人类视频中获得Affordances作为机器人的多用途表示
The meaning or value of a thing consists of what it affords... what we perceive when we look at objects are their affordances, not their qualities.
-J.J. Gibson
在一个新的厨房环境中,采取动作之前,人类已经对大部分物品可以怎么操作有了很好的理解。这种理解不仅仅停留在语义层面,还知道对象哪里可以握住和往哪个方向移动。虽然这些理解不总是有效,有时可能需要探索,但是人类非常依赖物品的这种视觉affordances,从而在不同的环境中高效的执行日常任务。随着深度学习技术的发展,视觉技术不断的发展,不仅仅可以从图片中标记大部分对象,甚至可以知道其位置。然而,这些信息对于机器人执行是任务远远不够的。VRB作者们利用视觉affordances解决视觉与机器人之间的间隔。这种整合需要解决三个问题,分别是:
- 表示affordances的有效方式是什么?
- 如何从数据中学习这种表示?
- 如何把视觉affordances适应各种机器人学习范式?
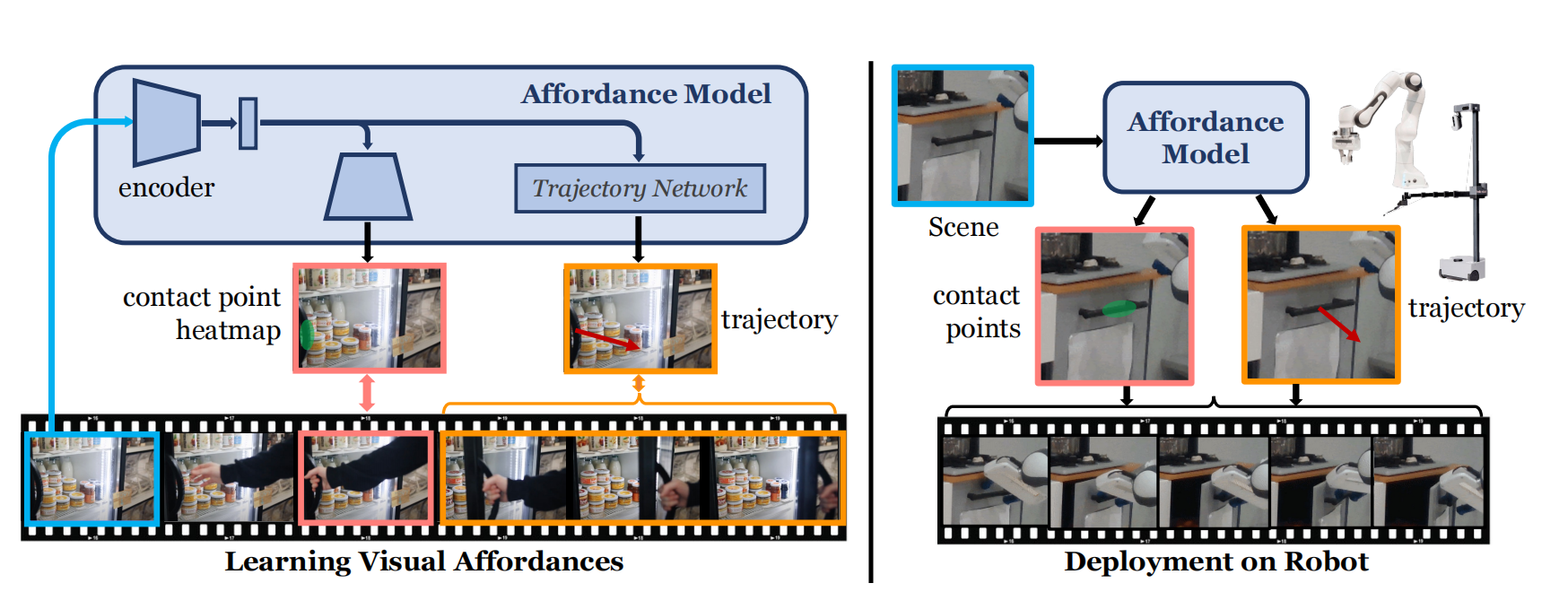
图1 VRB(Vision-Robotics Bridge)概览
Affordances的可行动的表示
Affordances只在有人执行才会有意义,因此抽取affordances最直接的方式是观察人类与世界的交互。虽然affordances之前的表示方式,例如:热力图、物品的前置与后置条件、以及人类交互的描述,均得到了很好的研究,但是无法参数化,这对机器人很重要。同时,这种表示应能够对不同的机器人形态拥有很好的泛化性。因此,作者们利用接触点与接触后轨迹作为视觉affordance的表示,从而使机器人能够理解与物品的可交互地方与可移动的方向。确切的说,利用$c$表示接触点,利用$\tau$表示可接触轨迹。其中,$\tau=f(I_t,h_t)$,$I_t$为时刻$t$的图片,$h_t$为人手在像素空间的位置,$f$为可学习的模型。
从视频数据中学习Affordances
接下来的问题,就是如何从人类视频中以一个可扩展的数据驱动方式抽取$c$与$\tau$。VRB通过机器人优先的方式解决该问题。
从人类视频中抽取Affordances
考虑一个视频$V$,一个人开门由$T$帧构成,即$V=\{I_1,\ldots,I_T\}$。那么,有两个目标:
- 找到哪里与什么时候接触发生。
- 在接触之后,如何估计手怎样移动的。
为了解决该问题,作者们利用hand-object检测模型,该模型对于每个输入图片$I_t$,产生手的2D有界box $h_t$与一个离散的接触变量$o_t$。然后,过滤出$o_t$表示视频中有接触点的帧,且找到第一次接触发生的时间$t_{contact}$。
手在像素空间的位置${\{h_t\}}_{t_{contact}}^{{t}'}$构成了接触后轨迹$\tau$。为了抽取接触点$c$,利用对应的有界boxes,且利用皮肤颜色分割找到hand边缘与有界boxes交叉的所有点。由此,可得到$N$个接触点$\{c^i\}^N$。那么,如何利用这些接触点训练affordance模型?一些方法预测接触点均值或者随机采样$c^i$的方式。与之不同,作者鼓励预测多峰,这是因为一个场景可能包含多个可能交互。因此,作者们利用GMM模型拟合接触点。那么,接触点的分布为
$$ \begin{aligned} p(c)=\underset{\mu_1,\ldots,\mu_{K},\Sigma_1,\ldots,\Sigma_K}{argmax}\sum_{i=1}^N\sum_{k=1}^K\alpha_{k}\mathcal{N}(c^i\vert\mu_k,\Sigma_k) \end{aligned}\tag{1} $$
综上所述,可分为三个步骤:
- 在人类视频中找到第一次接触发生的时间$t_{contact}$
- 利用GMM算法拟合帧$I_{t_{contact}}$中手的接触点
- 找到2D手有界box$\{h_t\}^{{t}'}_{t_{contact}}$的接触后轨迹$\tau$
为了考虑相机的移动,对$t_{contact}$与${t}'$时间段的轨迹进行补偿。确切的说,作者们利用时刻$t$的homography矩阵$\mathcal{H}_t$把接触点投射到开始帧的坐标系中。其中,homography矩阵通过两个连续帧之间特征比较获得。那么,轨迹为$\tau=\mathcal{H}_t\circ\{h_t\}^{{t}'}_{t_{contact}}$。
同时,由于所获得的视觉信息是以人为中新的,所以为了处理Human-Robot之间视觉领域的迁移,对人存在的帧中抽取affordances,但是把它们映射到人还没出现的第一帧。若第一帧中人存在且与环境无交互,那么裁剪掉;若人存在且与环境交互,那么抛弃掉这一帧。
训练Affordances模型
affordance模型以图片数据作为输入数据。为了应对接触点的多峰分布的问题,利用相同的模型预测交互点的多个热力图,从而构建一个空间概率分布。为了方便,利用$(\cdot)_{\theta}$表示所有参数化模块和$f_{\theta}$表示整个网络,如图1所示,affordance模型概览,输入图片$I_t$被ResNet$g_{\theta}^{con}$编码为空间隐表示$z_t$,即$g_{\theta}^{conv}(I_t)=z_t$。然后,利用反卷积层把$z_t$投射为$K$个概率分布或热力图,即$H_t=g_{\theta}^{deconv}(z_t)$。然后,利用空间softmax函数$\sigma_{2D}$估计GMM均值$\mu_k$,协方差矩阵保持不变。那么,其损失函数为
$$ \begin{aligned} \mathcal{L}_{contact}=\Vert\mu_i-\sigma_{2D}(g_{\theta}^{deconv}(g_{\theta}^{conv}(I_t)))\Vert_2 \end{aligned}\tag{2} $$
为了估计接触后轨迹,训练轨迹预测网络$\mathcal{T}_{\theta}$。轨迹预测网络以$z_t$为输入,预测运动方向。具体的说,利用Transformer中自注意力网络进行序列预测,其损失函数为$\mathcal{L}_{traj}=\Vert\tau-\mathcal{T}_{\theta}(z_t)\Vert_2$。同时,为了应对图片中存在多个可交互的对象带来的不确定性,对接触点附近的周围进行局部采样。
基于视觉Affordances的机器人学习
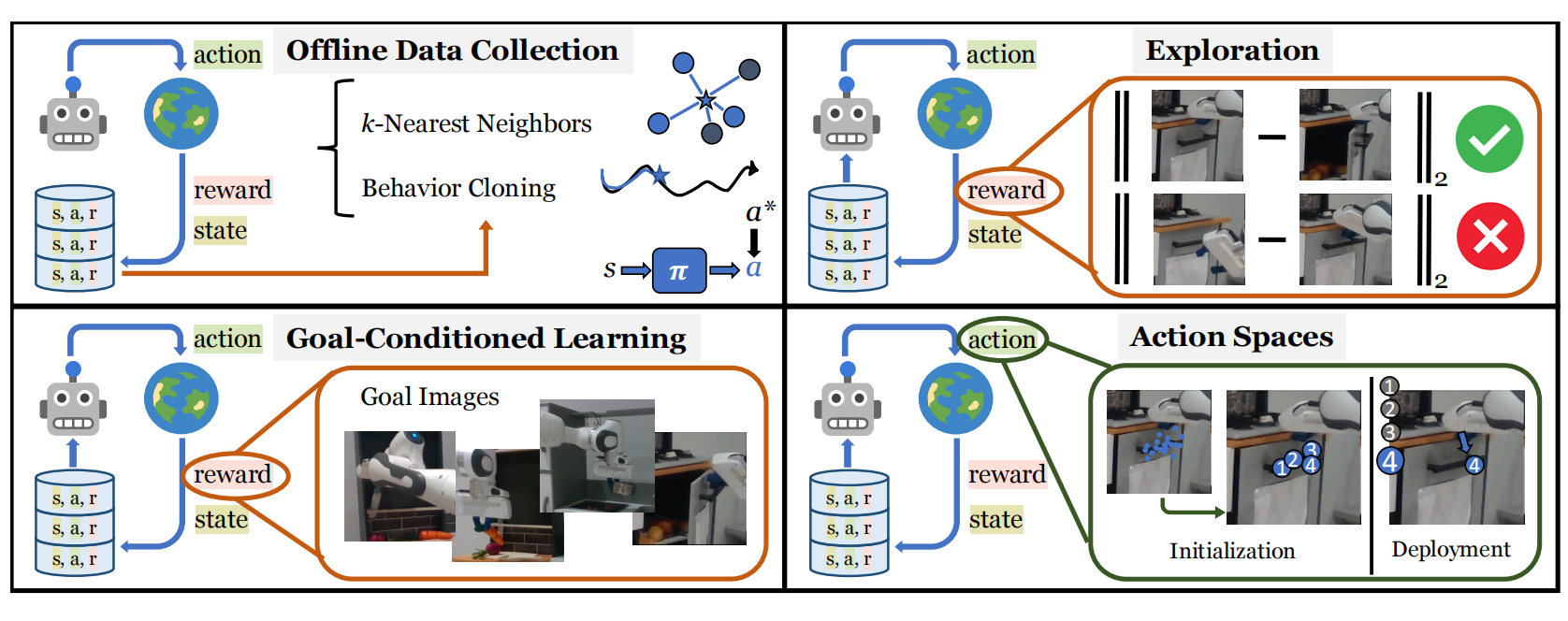
图2 机器人学范式
对于模仿学习,把输入图片$I_t$与affordance模型的输出$(c,\tau)=f_{\theta}(I_t)$存储为数据数据集$\mathcal{D}$。对于给定目标图片,利用KNN算法过滤出与其距离最近的轨迹。然后,基于最接近的轨迹,利用BC算法训练策略$\pi(c,\tau\vert I_t)$。
对于无奖励的探索,先利用affordance模型$f_{\theta}(\cdot)$收集数据。接下来,再利用任务无关的探索度量对所有轨迹排序,并利用分布$h$拟合最优轨迹的$(c,\tau)$。接下来,可从分布$h$中采样,也可以利用affordance模型采样,最大化第一张图片与最后一张图片之间的环境改变$EC(I_i,I_j)=\Vert\phi(I_i-\phi(I_j))\Vert_2$,也为探索度量。
对于目标为条件的学习,与探索一致,基于affordance模型收集轨迹,再对轨迹进行排序,最后拟合分布$h$。与探索不同的是,其度量为最小化轨迹中最后一张图片$I_{T}$与目标图片$I_g$之间距离$\Vert\psi(I_g)-\psi(I_T)\Vert_2^2$。
对于Affordance作为动作空间,由于机器人的动作空间是连续性,因此需要动作空间进行参数化。一种可替代的方式是以空间的方式参数化,为每个位置分配一个原始技能,例如:抓、推、或放。在当下场景,先多次查询affordance模型获得大量预测,然后利用GMM拟合这些点。最终,通过对GMM模型采样的方式搜索动作。
相关思考
若从生成模型的角度看待affordance估计,那么建模这种多峰分布利用扩散模型或Transformer也许是一个新思路。同时,不同学习范式下基于Affordance的策略学习方法笔者也看不太懂,可能需要结合代码进一步理解。
引用方法
请参考:
li,wanye. "VRB:从人类视频中获得Affordances作为机器人的多用途表示". wyli'Blog (Apr 2024). https://www.robotech.ink/index.php/archives/427.html
或BibTex方式引用:
@online{eaiStar-427,
title={VRB:从人类视频中获得Affordances作为机器人的多用途表示},
author={li,wanye},
year={2024},
month={Apr},
url="https://www.robotech.ink/index.php/archives/427.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接