DINO:自监督视觉Transformer的新特性
在自然语言处理领域,基于Transformer为网络架构的自监督预训练为任务提供了丰富的学习信号,从而实现了突破性进展。在视觉领域,ViT基于标签作为监督信号进行预训练,性能超过了基于ConvNets的模型。DINO作者们质疑ViT拥有优越性能是由监督信号导致的。由此,研究了基于ViT特征的自监督预训练的影响。最终,发现了一些与监督ViT或ConvNets相比,自监督ViT特有的有趣特性:
- 自监督ViT特征确切的包含场景布局和对象边界信息,可见图1所示。这些信息与最后一个Block的自注意力模块的可获取性有直接关系。
- 自监督ViT特征在KNN算法上性能优越,无需微调、线性分类器、或数据增强,可在ImageNet上实现78.3%的top-1准确率。

图1 基于无监督训练的视觉Transformer的自注意力
分割掩码似乎属于自监督方法共享的特性。然而,基于KNN的优越性能往往需要动量编码器和multi-crop增强相结合才能实现。同时,较小的patches对VITs提升性能很重要。根据发现的这些元件重要程度,设计了一个简单的自监督方法,可称为无标签的知识蒸馏DINO。
算法设计
如图2所示,DINO通过直接预测teacher网络的输出简化自监督训练,目标函数交叉熵。同时,作者们发现,teacher网络只需要一个centering和sharpening的输出,就可以避免模式崩塌。然而,其它的元件,例如:预测器、高级归一化器、或对比损失,对稳定性和表现只能展现很少的益处。
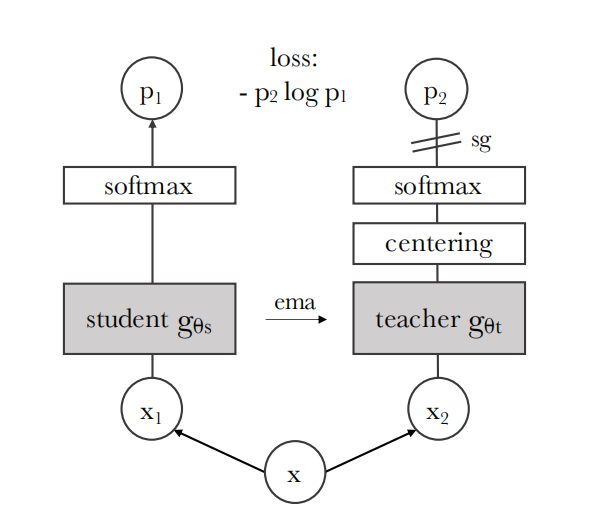
图2 无标签的自蒸馏。两个网络具有相同的架构,但参数不同。教师网络的输出以batch数据的平均值为中心。对教师应用了停止梯度 (sg) 运算符,以便仅通过学生传递梯度。教师参数使用学生参数的指数移动平均值 (ema) 进行更新。
基于知识蒸馏的自监督学习
知识蒸馏是一个学习范式,训练一个学生网络$g_{\theta_s}$以匹配teacher网络$g_{\theta_t}$的输出。对于给定图片$x$,网络的输出均是$K$维概率分布,可用$P_s$和$P_t$表示。确切的说,概率分布$P$是由网络$g$的输出归一化得到
$$ \begin{aligned} P_s(x)^{(i)}=\frac{exp(g_{\theta_s}(x)^{i}/\tau_s)}{\sum_{k=1}^K exp(g_{\theta_s}(x)^{k}/\tau_s)} \end{aligned}\tag{1} $$
其中,$\tau_s$为温度参数,控制输出分布的尖锐程度。
对于给定teacher网络$g_{\theta_t}$,通过最小化交叉熵损失的方式匹配两者分布
$$ \begin{aligned} \underset{\theta_s}{min}H(P_{t}(x),P_s(x)) \end{aligned}\tag{2} $$
其中,$H(a,b)=-alogb$
那么,对自监督学习,首先构建每个图片不同distorted视角,或利用multi-crop策略的不同crops,即对于给定图片生成不同视角集合。该集合包含两个全局视角$x_1^g$和$x_2^g$,以及小分辨率的许多局部视角。所有的crops传递到学生网络,而只有全局视角传递到teacher网络,从而鼓励“局部到全局”进行对应。其损失函数为
$$ \begin{aligned} \underset{\theta_s}{min}\sum_{x\in\{x_1^g,x_2^g\}}\quad\sum_{{x}'\in V,{x}'\neq x}H(P_t(x),P_s({x}')) \end{aligned}\tag{3} $$
其中,全局视角的分辨率为$224\times224$,局部视角的分辨率为$96\times96$。
Teacher网络
与知识蒸馏不同的,不存在一个先验的teacher$g_{\theta_t}$,因此从历史学生网络构建teacher网络。其中,teacher网络的更新方式为指数移动平均EMA,该方法也被称为动量编码器。
$$ \begin{aligned} {\theta}_t\leftarrow\lambda\theta_t+(1-\lambda){\theta}_s \end{aligned}\tag{4} $$
其中$\lambda$从0.996至1根据余弦调度的方式设定参数值。
网络架构
神经网络$g$由ViT或ResNet作为骨架$f$和一个投射head $h:g=h\circ f$构成。骨架$f$的输出用于下游任务。其中,投射头由三层感知机和$l_2$正则化构成,隐藏层维度为2048。对于ViT,由于本身架构无batch-normalization,因此投射head也无batch-normalization。
避免坍塌
为了避免模型坍塌,作者们对teacher网络的输出使用中心化和sharpening。中心化有利于阻止一个维度占据主导地位,而鼓励输出为均匀分布。与中心化不同,sharpening拥有完全相反的效果。因此,两者可用于平衡模型坍塌和训练的稳定性$($降低对batch数据的依赖$)$。其中,中心化是对输出增加一个偏差项$c$,即$g_t(x)\leftarrow g_t(x)+c$,且$c$的更新方式为
$$ \begin{aligned} c\leftarrow mc+(1-m)\frac{1}{B}\sum_{i=1}^Bg_{\theta_t}(x_i) \end{aligned}\tag{5} $$
输出sharpening由teacher网络输出的softmax标准化温度参数$\tau_t$控制。
综上所示,DINO算法伪代码可见算法1

相关思考
这种蒸馏方式的设置与RL中目标网络和行为网络之间的更新关系有相似之处。
引用方法
请参考:
li,wanye. "DINO:自监督视觉Transformer的新特性". wyli'Blog (Jul 2024). https://www.robotech.ink/index.php/archives/549.html
或BibTex方式引用:
@online{eaiStar-549,
title={DINO:自监督视觉Transformer的新特性},
author={li,wanye},
year={2024},
month={Jul},
url="https://www.robotech.ink/index.php/archives/549.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接