ViT:视觉编码器
如图1所示,ViT整体架构很简单,由Transformer的Encoder构成,非双向。首先,图片分成$N$块patch,作为输入序列的token。然后,$N$token被打平,再输入线性映射层得到embedding。接下来,patch embedding与position embedding相加输入Encoder。与Bert的class token一样,也有一个可学习类别embedding的token $z_0^0$,其在Encoder对应输出$z_L^0$是整个图片的表示。最后,$z_L^0$输入到MLP网络预测类别,即在图片分类任务上预训练。
与Transformer不同的,ViT的position embedding是学习出来的。为了ViT可以处理任意序列长度,对位置embedding进行了2D插值防止其失效。
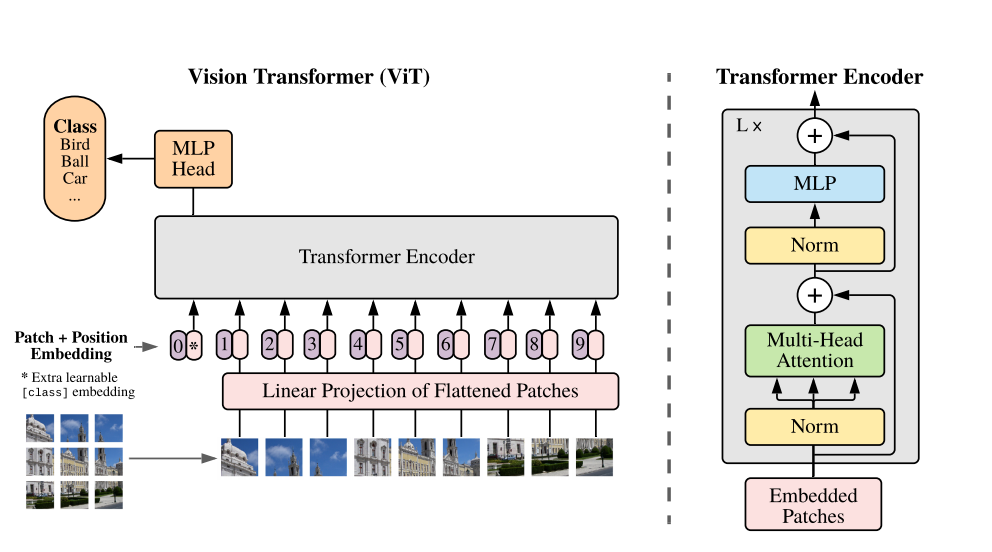
图1 模型架构
引用方法
请参考:
li,wanye. "ViT:视觉编码器". wyli'Blog (Jan 2024). https://www.robotech.ink/index.php/archives/66.html
或BibTex方式引用:
@online{eaiStar-66,
title={ViT:视觉编码器},
author={li,wanye},
year={2024},
month={Jan},
url="https://www.robotech.ink/index.php/archives/66.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接