DiT:基于Transformer可扩展的扩散模型
Transformer在自然语言处理、视觉、以及许多其它领域得到了广泛的应用。然而,在图像相关的生成模型领域很少采用Transformer网络架构,例如:扩散模型利用卷积U-Net作为网络架构。对于基于U-Net的扩散模型,ADM作者们分析了网络扩展性与网络复杂性度量Gflop的特性。与之不同,DiT作者们揭开了扩散模型的网络架构选择的重要性,且对未来生成模型研究提供了经验。确切的说,在隐式扩散模型LDMs框架下,构建了基于Transformer扩散模型的设计空间,研究了网络复杂度与样本质量之间的关系,即模型的扩展性。

图1 基于DiTs的ImageNet生成。气泡区域表示扩散模型的flops。左图:我们的 DiT 模型在 400K 次训练迭代中的 FID-50K(越低越好)。随着模型flops的增加,FID 的性能稳步提高。右图:我们的最佳模型 DiT-XL/2 具有计算效率,并且优于所有之前基于 U-Net 的扩散模型,例如 ADM 和 LDM。
基础知识
对于扩散模型相关知识,可见DDPM
无分类器的引导
条件扩散模型需要辅助信息作为输入,例如:类标签$c$。在这种情况下,逆过程变为了$p_{\theta}(x_{t-1}\vert x_t,c)$,其$\epsilon_{\theta}$和$\Sigma_{\theta}$以$c$为条件。在该设置下,无分类器引导的扩散可被用于鼓励采样过程生成$x$,从而使$logp(x\vert c)$足够高。根据Bayes规则,$logp(c\vert x)\propto logp(x\vert c)-logp(x)$,那么$\nabla_xlogp(c\vert x)\propto \nabla_xlogp(x\vert c)-\nabla_xlogp(x)$。根据扩散模型为分数匹配的理论,可知,DDPM的采样过程可通过:$\hat{\epsilon}_{\theta}(x_t,c)=\epsilon_{\theta}(x_t,\emptyset)+s\cdot\nabla_xlogp(x\vert c)\propto\epsilon_{\theta}(x_t,\emptyset)+s\cdot(\epsilon_{\theta}(x_t,c)-\epsilon_{\theta}(x_t,\emptyset))$
plus:这一部分的内容应该是讲条件扩散模型利用无分类器引导的方式进行采样。
引导。其中,$s\gt1$表示引导的规模。在$c=\emptyset$下估计扩散模型可通过在训练期间随机dropping掉$c$或者利用一个学习的"null"embedding编码替换它。无分类器引导使扩散模型生成的样本质量得到了很大的提升,且这种趋势持续存在。
隐式扩散模型
在高分辨率像素空间,训练扩散模型成本很高。LDMs处理利用两阶段方式处理该问题:
- 利用一个可学习的编码器,把图片压缩到更小的空间表示。
- 训练一个表示$z=E(x)$的扩散模型,而不是图片$x$的扩散模型。
新的图片可通过从扩散模型中采样一个表示$z$,然后利用解码器把$z$解码成图片$x=D(z)$。
如图1所示,与ADM相比,LDMs只利用小部分Gflops就可以实现很好的性能。由于作者们也关注计算效率,因此把LDMs作为架构探索的出发点。
DiT的设计空间
由于作者们关注的是训练一个图片的DDPMs模型(确切的说,图片的空间表示),所以DiT是基于ViT架构,利用了ViT最好的实践。如图2所示,DiT的整个架构。
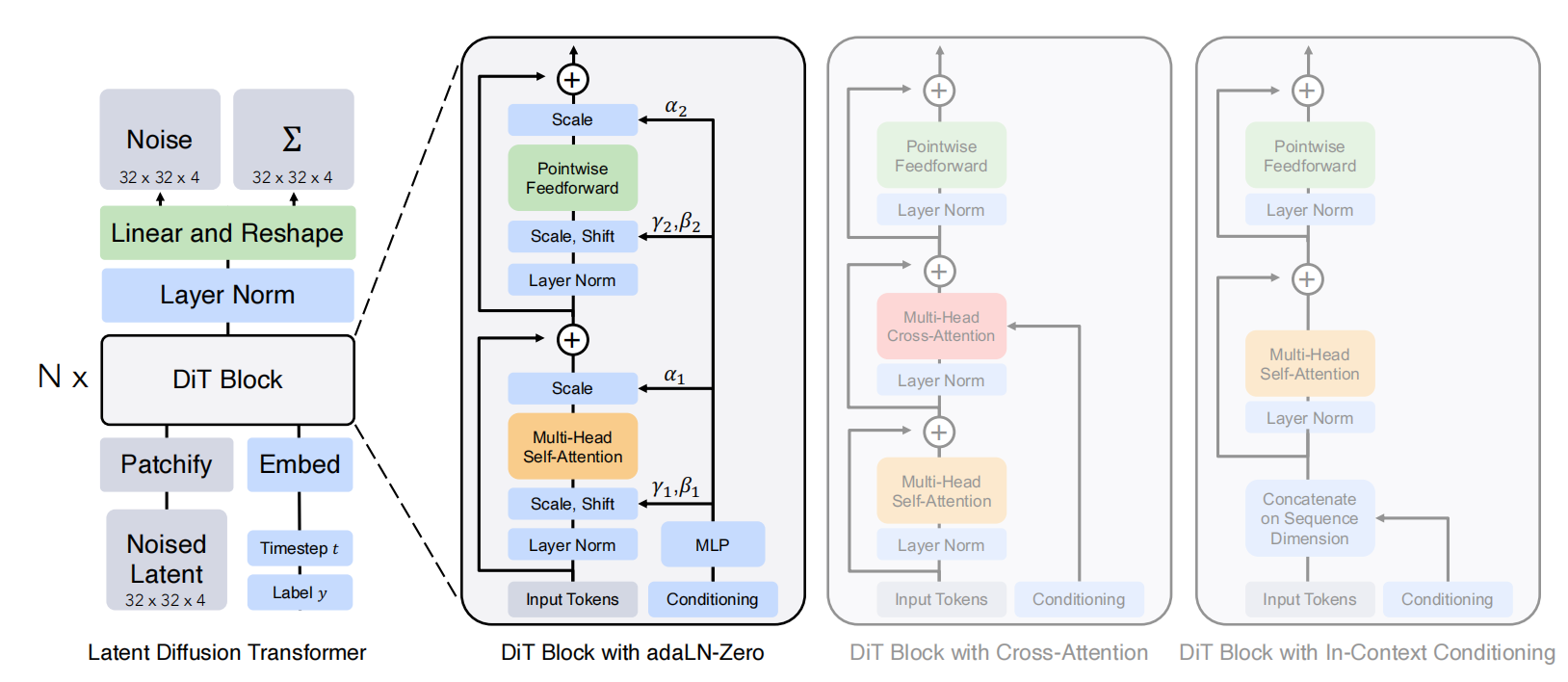
图2 DiT网络架构。左图:我们训练条件潜在 DiT 模型。输入潜在被分解为块并由多个 DiT 块处理。右图:我们的 DiT 块的细节。我们尝试了标准 Transformer 块的变体,这些变体通过自适应层规范、交叉注意和额外的输入标记结合了条件。自适应层规范效果最好。
Patchify
DiT的输入是空间表示$z$(对于$256\times256\times3$的图片,$z$的shape为$32\times32\times4$)。DiT的第一层是"patchify",该层把空间输入转化为$T$个tokens序列,每个维度为$d$,可见图3所示。在Patchify之后,对输入序列应用标准ViT位置编码(sine-cosine)。tokens的数量$T$由patch大小$p$决定,$p$减少一半$T$增加4倍,也就需要$4$被的Gflops。然而,$p$的变化对下游参数量无影响。作者们把$p=2,4,8$应用到$DiT$的设计空间。
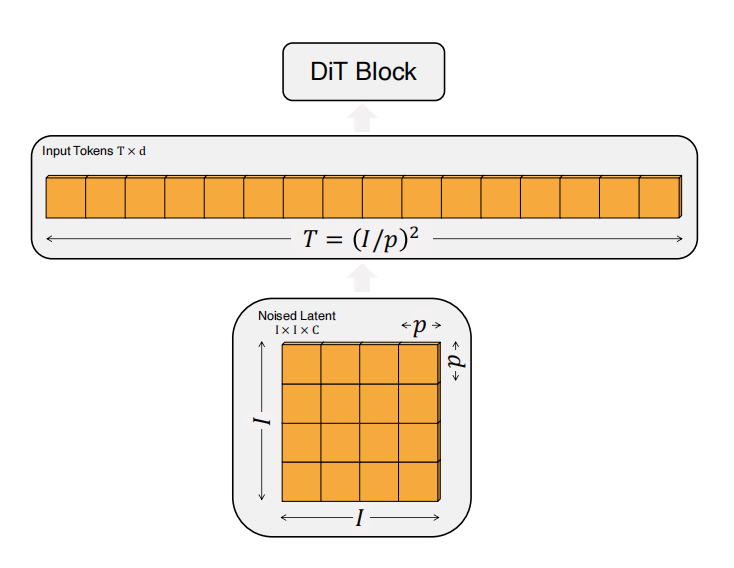
图3 DiTs的输入说明
DiT块设计
patchify后的tokens被transformer块序列处理。除了噪音图片输入,扩散模型有时也需要输入条件信息,例如:噪音时间步$t$、类标签$c$、自然语言等。作者们探索了transformer块的4个变体,用于处理不同的输入,可见图2所示。
- In-context conditioning :在输入序列中只增加$t$与$c$的向量embedding作为额外tokens,且与图片tokens采用相同处理方式。这种方式与ViTs中的cls tokens相似,从而可直接利用标准的ViT块。在最后一个DiT块,作者们从输入序列中移除了条件tokens。这种方式几乎不增加新的Gflops。
- 交叉注意力块:把$t$与$c$的token进行cocat,形成长度为2的序列,与图片token独立。在多头自注意力块之后,DiT块增加一个多头交叉注意力块。交叉注意力增加了大约$15%$的Gflops。
- 自适应层标准化(adaLN)块:与GANs中广泛采用的自适应标准化层一致,作者们利用自适应层标准化adaLN代替transformer中层标准化。这种方式拥有最高效的计算。这也是唯一一个对所有tokens应用相同条件机制的块。
- adaLN-Zero块:之前关于ResNets的工作发现,把每个残差块初始化为identity函数是有益处的,例如:Goyal等人发现在每个block中零初始化最后的batch 标准化缩放系数$\gamma$对可加速监督学习框架下的大规模训练。Diffusion U-Net模型利用了相同的初始化策略,即在任何残差连接前零初始化每个块的最后卷积层。作者们也对adaLN的DiT块进行了相同处理。确切的说,不仅仅回归了adaLN的缩放系数$\gamma$和偏移系数$\beta$,作者们也回归了维度的缩放参数$\alpha$,把它应用在DiT块中任何残差连接前。同时,对所有$\alpha$进行了零初始化输出。
如表示1所示,作者们共设计了4中DiT模型,研究其扩展性。
表1 DiT模型的细节
在最后的DiT块,作者们需要把每个图片tokens的序列解码成噪音预测和对角斜方差预测。这些输出均与原始空间输入拥有相同的尺寸。确切的说,作者们利用标准的线性解码器进行解码;作者们对最后一层应用标准化和线性的解码每个token为$p\times p\times2C$tensor。其中,$C$为DiT空间输入的通道数量。最后,把解码的tokens重新排列为原始的空间布局,从而得到预测的噪音和斜方差。
总结
总的来说,DiT属于VAE与基于Transformer的DDPMs的混合架构。其中,VAE为Stable Diffusion中模型。
引用方法
请参考:
li,wanye. "DiT:基于Transformer可扩展的扩散模型". wyli'Blog (Jul 2024). https://www.robotech.ink/index.php/archives/540.html
或BibTex方式引用:
@online{eaiStar-540,
title={DiT:基于Transformer可扩展的扩散模型},
author={li,wanye},
year={2024},
month={Jul},
url="https://www.robotech.ink/index.php/archives/540.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接