Chameleon:混合模态early-fusion基础模型
多模态基础模型通常利用特定的编码器或解码器独立的对不同模态建模。然而,这种方式限制了整合模态之间信息的能力,以及生成多模态文本的能力。Chameleon是一系列混合模态基础模型,能够生成和推理文本-图片交织的内容,即该模型以端到端的统一架构处理混合模态数据。
同时,为了便于同时处理文本与图片,把图片量化为离散token,从而允许无缝推理和生成多模态内容。为了实现这种能力,也需要提高模型优化的稳定性和可扩展性。
由此,作者们构建了一个稳定的训练方法、对齐方案、以及为early-fusion的token级别的混合模态场景定制的架构参数化方法。利用这些技术,Chameleon-34B在Llama-25倍tokens数据量训练,拥有了在混合模态推理和生成方面的新能力,且媲美或超越其它LLMs和VLMs在单模态或多模态benchmarks上的能力。其中,新能力主要是指可处理任何序列的图片和文本。

图1 Chameleon原理图
预训练
Image Tokenization:在Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors基础上训练了新的图片tokenizer,用于把$512\times512$图片编码为维度大小为$1024$的离散tokens。其中,编码集大小为$8192$。这种tokenizer的主要缺点在于构建带有大量文本的图片。
plus:笔者认为这种tokenization的方法,应该是VQ-VAE的改进。
Tokenizer:在词汇表大小为$65536$的训练数据子集上,训练了新的BPE编码器。其中,训练数据包含大小为$8192$的图片编码集。
预训练数据
预训练分为两个阶段,第一个阶段占训练的$80%$,剩下的部分为$20%$。对于所有的Text-To-Image数据,均进行了翻转获得captioning数据。
第一阶段:文本数据为LLaMa-2和CodeLLaMa的训练数据,tokens数量为$2.9$trillion。文本-图片数据对均授权的公共可获得的,总量为$1.4$billion,共$1.5$trillion的tokens。文本与图片交织数据共$400$billion的tokens。
第二阶段:训练数据由第一阶段$50%$数据与高质量数据集混合而成。其中,图片与文本比例相似。同时,也包含指令调优数据集的部分子集。该子集由过滤得到。
稳定性
在Chameleon模型扩展到$8B$参数和$1T$tokens以上,训练后期会产生不稳定性。为了实现稳定性,作者们设计了新的架构和优化方法。
架构:与LLaMa-2架构一致,利用RMSNorm作为标准化方案,也适用了SwiGLU激活函数和旋转位置编码RoPE。
作者们发现标准的LlaMa架构表现出复杂的发散,这是因为训练中后期范数的缓慢增长。进一步的说,在训练多模态数据时,由于softmax的平移不变特性,即:$softmax(z)=softmax(z+c)$,其熵显著的增加。由于模态之间共享相同的模型权重,每个模态之间通过增加自身的范数,从而彼此尝试“竞争”。在单模态中,这种问题被命名为logit偏移问题。如图2a所示,在训练过程中transformer最后一层输出范数的变化曲线,表示输出范数与未来损失发散之间有很强的相关性。
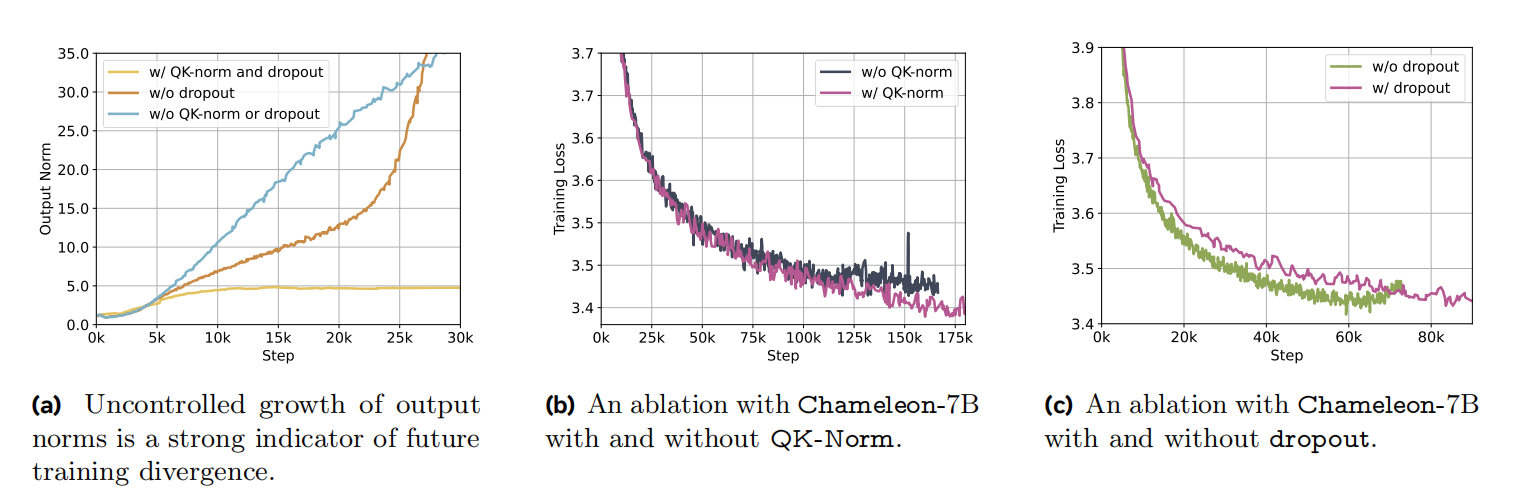
图2 各种设置下Chameleon的输出范数和训练损失曲线
Transformer中softmax运算主要发生在两个地方,分别是注意力机制和logits的softmax计算。受到Scaling Vision Transformers to 22 Billion Parameters和Small-scale proxies for large-scale Transformer training instabilities的启发,作者们通过query-key normalization(QK-Norm)改进Llama。确切的说,QK-Norm通过对注意力中键和值进行layer norm直接控制softmax输入的范数增长。图5b,表示了Chameleon-7B有无QK-Norm的训练损失曲线。
同时,除了QK-Norm之后,作者们也发现注意力和全连接层之后的dropout对稳定化Chameleon-7B也很必要。然而,对于Chameleon-34B,dropout和QK-Norm不足以实现稳定化,需要再进行normalization re-ordering才能实现稳定化。这种normalization策略来自于Swin Transformer,它限制了全连接块的范数增长,这对于SwinGLU激活的连乘性质造成的发散具有很好的缓解作用。若$h$表示输入$x$自注意力之后时间步$t$的隐藏层向量,
Chameleon-34B:
$$ \begin{aligned} h=x+{attention}\_{norm}(attention(x)) \\ output = h + {ffn}\_{norm}({feeed}\_{forward}(h)) \end{aligned} $$
Llama2:
$$ \begin{aligned} h=x+attention({attention}\_{norm}(x)) \\ output = h + {feeed}\_{forward}({ffn}\_{norm}(h)) \end{aligned} $$
在复杂度方面,LLaMa-2参数发散之前有无normalization re-ordering没有差别。同时,作者们也发现,这种标准化与dropout结合没有展现出很好的效果,可见图3c所示,无dropout的Chameleon-34B训练效果。
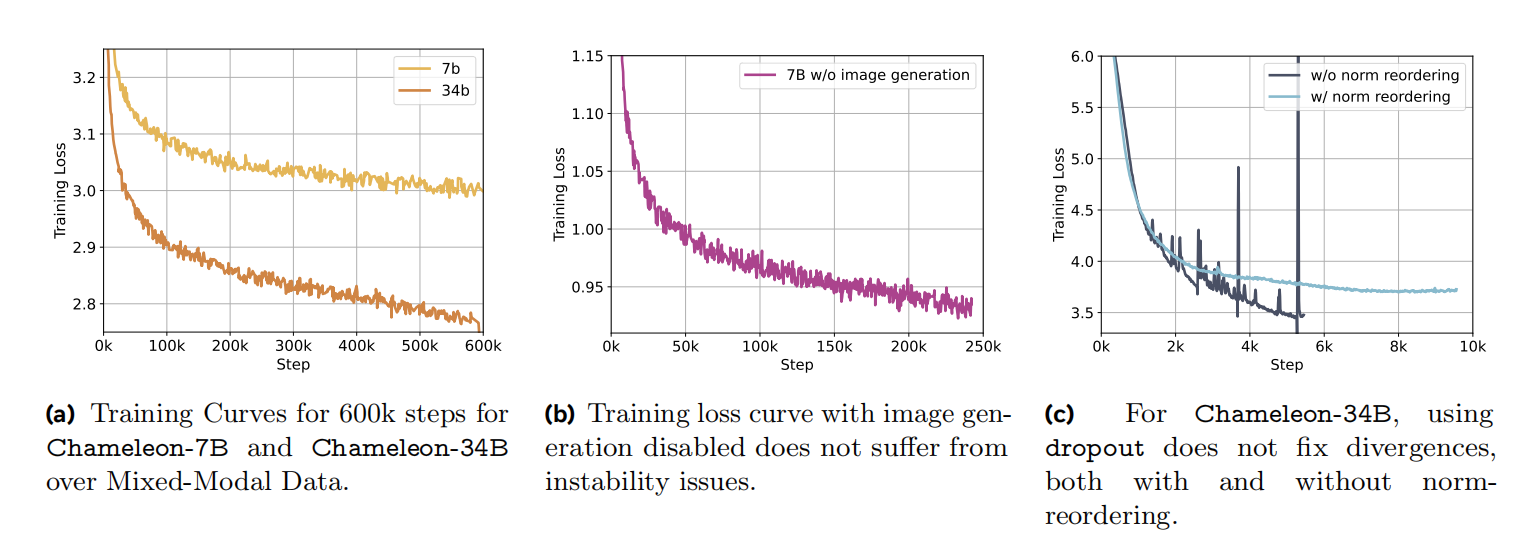
图2 各种设置下Chameleon的输出范数和训练损失曲线
优化:训练的优化器为Adam,其$\beta_1=0.9,\beta_2=0.95,\epsilon=10^{-5}$。其中,学习率的指数衰减调度,warm-up步数为4000。权重衰减为0.1,梯度裁剪阈值为1.0。Chameleon-7B的dropout概率为0.1,Chameleon-34Bdropout率为0.0。
为了应对最终softmax的logit shift问题,作者们利用z-loss进行正则化softmax函数的分母$Z$。确切的说,对损失函数增加$10^{-5}log^2Z$
推理
为了支持对齐与评估,需要提升模型推理的吞吐量和减少延时。这是因为混合模态的生成会引入Data-dependencies per-step,Masking for modality-constrained generation,与Fixed-sized text units的调整,详情可见论文。
对齐
根据LIMA: Less Is More for Alignment工作,作者们基于有监督微调在高质量数据集上实施了轻量级对齐。其中,包含不同类型的数据集,目标是暴露模型的能力和提升安全性。数据集详情可见论文。
微调策略
在微调阶段,保持不同模态之间的数据平衡非常重要。确切的说,在SFT阶段,若模态之间的数据严重不平衡,会导致模型学习了一个无条件的先验,从而要么不生成特定模态,要么过多的生成。
对于有监督微调阶段优化,学习率进行了余弦调度。其中,初始学习率为$1e^{-5}$,权重衰减系数为$0.1$。batch-size大小为128,包含$4096$个tokens。每个数据集实例由提示和对应的答案构成。同时,为了描述提示的结束和答案的开始,潜入了一个distinct token。在微调阶段,图片进行border填充从而图片中所有信息输入到模型;在图片生成阶段,进行了center-cropped,从而确保了优秀的图片生成质量。微调训练阶段,目标函数与自回归目标函数一致。
相关思考
Chameleon的early-fusion应该是指图片和文本的处理不需要特定的编码器或解码器。对于图片,只需要经过image-tokenizer就可以把图片的tokens投射到与文本的共享空间。
在论文的相关工作中,表示,利用离散tokens表示视觉数据可追溯到BEiT,可以说这篇文章的工作就是在VQ-VAE基础之上进行的。随后,CM3作者们把这种想法推广到了对混合模态文档的学习,从而可允许在统一架构下对两种模态联合推理。在之后,CM3Leon作者们在DALL-E中基于token的图片生成的基础之上,把这种方式扩展到了自回归文生成图。Chameleon的early-fusion就是在基于离散tokens表示图片数据的血统下,发展起来的。
引用方法
请参考:
li,wanye. "Chameleon:混合模态early-fusion基础模型". wyli'Blog (Oct 2024). https://www.robotech.ink/index.php/archives/647.html
或BibTex方式引用:
@online{eaiStar-647,
title={Chameleon:混合模态early-fusion基础模型},
author={li,wanye},
year={2024},
month={Oct},
url="https://www.robotech.ink/index.php/archives/647.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接