RT2:视觉-语言-动作模型将网络知识迁移到机器人控制
与RT-1关注模型的泛化能力相比,RT-2的目标是训练一个学习机器人观测到动作端到端的模型,且能够利用大规模预训练视觉语言模型的益处。最终,提出了一个在机器人轨迹数据和互联网级别的视觉语言任务联合微调视觉语言SOTA模型的学习方式。这类学习方法产生的模型被称为vision-language-action(VLA)模型。经过评估,发现,该类模型获得了涌现能力,包括泛化到新对象的能力、解释命令的能力、根据用户指令思维推理的能力。如图1所示,RT-2模型概览。
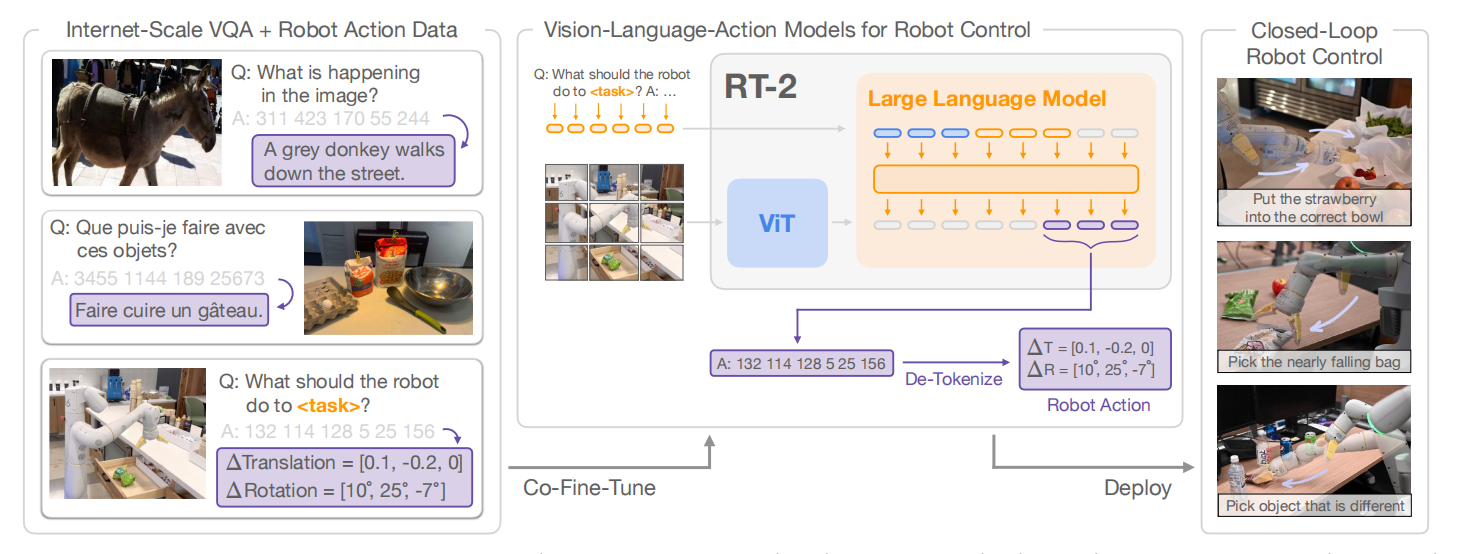
简单来说,RT-1是利用预训练模型对视觉与语言进行编码,然后再通过解码器输出动作。与之不同,RT-2把语言、动作、图片放在一个统一的输出空间,利用VLMs产生语言,也可以理解为“动作”为特殊的语言。总的来说,RT-2分为两步:首先对VLMs在大规模互联网数据进行预训练,然后再机器人任务上微调。
视觉-语言-动作模型
视觉-语言模型预训练
RT-2基于PaLM-E和PaLI-X视觉语言模型在视觉解释和推理任务上预训练。预训练任务从根据语言创作图到单个对象与其它对象之间关系问题的回答。
动作微调
RT-2直接把动作tokens当作语言tokens,把RT-2-PaLI-X模型和RT-2-PaLM-E模型在机器人控制任务上微调。与RT-1一样,末端执行器的目标位姿作为动作空间,每一维度的动作空间被均匀的离散化为256个桶。
输出动作一种可能的方式是输出一个数字字符串,例如“1 128 91 241 5 101 127”。对于PaLI-X,拥有1000个独立的token,因此可以直接利用这些token与动作离散化的桶相关联,用于微调模型;对于PaLM-E,由于没有给出独立的tokens,因此需要覆盖之前学习过的256个tokens,这种微调方式被称为为符号微调。
值得注意的一个技术细节是联合微调,RT-2在互联网数据和机器人控制数据上联合微调。这种方式使模型能够学到更多任务之外的语言或图像知识。同时,为了保证模型在机器人控制任务上输出有效的动作,因此对输出进行了限制。
实时推理
为了能够实时控制机器人,把模型部署在云服务上,机器人通过与服务请求的方式
获取控制指令。
引用方法
请参考:
li,wanye. "RT2:视觉-语言-动作模型将网络知识迁移到机器人控制". wyli'Blog (Jan 2024). https://www.robotech.ink/index.php/archives/103.html
或BibTex方式引用:
@online{eaiStar-105,
title={RT2:视觉-语言-动作模型将网络知识迁移到机器人控制},
author={li,wanye},
year={2024},
month={Jan},
url="https://www.robotech.ink/index.php/archives/103.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接