RT-1:用于真实世界大规模控制的机器人Transformer
在自然语言处理与计算机视觉领域,高容量模型基于开放的不可知的任务训练,可以吸收大规模数据集中呈现的知识,从而学习到通用能力。然后,该模型可以在特定的新任务实现少样本或零样本泛化的能力。这种通用能力在机器人领域更为重要。虽然近几年许多大的多任务的机器人策略产生,但是它们的泛化能力很差。这是因为存在两大挑战,分别是:
- 构造合适的数据集
- 设计合适的模型
作者们历时17个月基于13个机器人得到了130k episodes以及超过700个任务的数据,这些数据可以使机器人能够形成很好的泛化能力,从而使机器人能够发现结构相似任务之间的模式,且应用到新任务上。该数据集不仅仅规模很大,而且广度很大。
高效的机器人多任务学习需要高容量模型。虽然Transformer在自然语言处理与计算机视觉领域展现出惊人的性能,但是它无法高效的实时运行。因此,RT-1作者们提出了一个机器人Transformer,它可以把相机图片、指令与电动机命令作为输入,即可对高维的输入与输出进行编码。RT-1的架构、数据集、以及评估概览,可见图1所示。
最终,实验表明RT-1可以展示较强的泛化能力和鲁棒性,可见图1.b,且可以执行SayCan中的长期任务。

概览
用于RT-1研究的机器人有7个自由度的机械臂、两个手指型夹抓,以及一个移动基座,可见图2(d)所示。为了收集数据和训练模型,构建了一个仿真环境,可见图2(a)所示。两个真实厨房环境用于评估,可见图2(b,c)。真实厨房与仿真环境中厨房拥有相似的柜台,只是灯光、背景、以及厨房的几何结构不同。训练数据由人类提供的演示组成,并根据机器人执行的指令对每个episode进行文本注释。

该系统主要的贡献:RT-1是一个高效的模型,可以吸收大量的数据,可高效的泛化,且可实时对机器人进行控制。RT-1的输入由图片序列、自然语言指令构成,输出由机械臂运动的目标位姿$(x,y,z,roll,pitch,yaw,gripper\quad status)$、基座的运动$(x,y,yaw)$、模式转换指令构成。机器人有三个模式,分别是:控制机械臂、基座、或者终止。
Robotics Transformer
模型
RT-1的模型架构可见图3所示。接下来,自上而下的详细介绍模型架构。
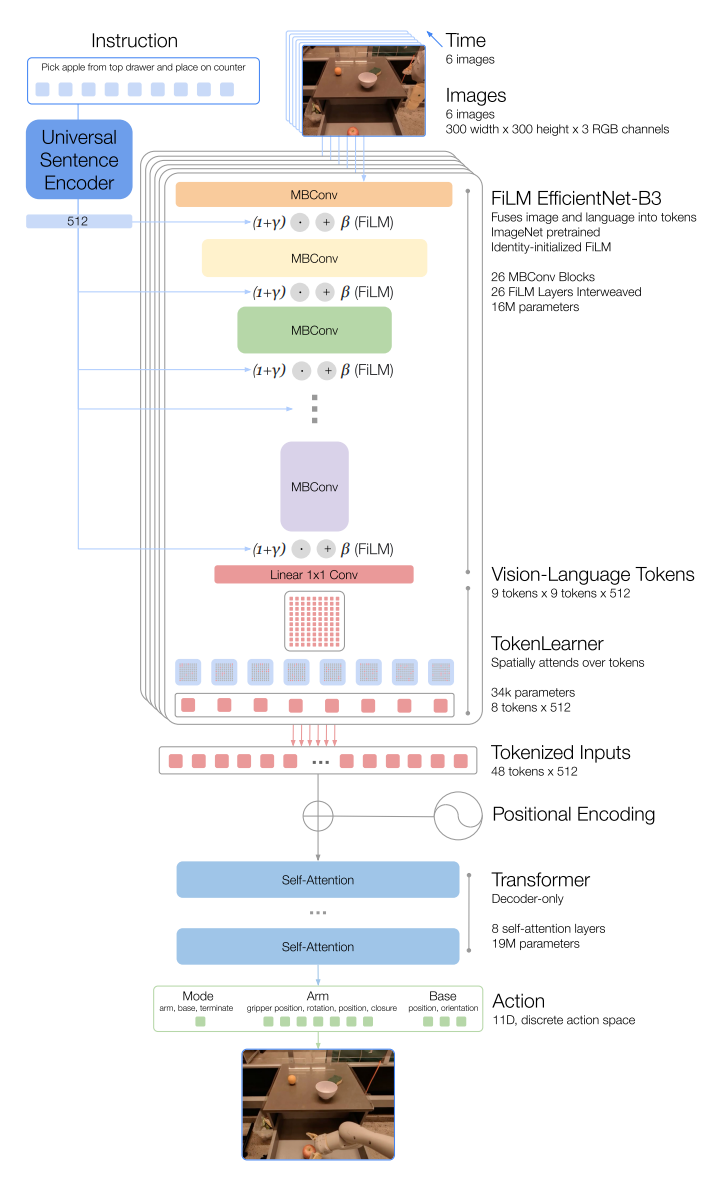
Instruction and image tokenization
RT-1通过ImageNet预训练的EfficientNet-B3把过去的6张图片tokenization。6张$300\times 300$的图片作为输入,输出$9\times9\times512$的特征地图,再被打平为$81$维的视觉tokens。其中,EfficientNet的主要模块为移动倒置瓶颈MBConv。
为了包含语言指令,以预训练语言embedding的形式调整图片tokenizer,允许抽取任务相关的图片特征,从而提升表现。首先,语言指令通过Universal Sentence编码器编码。然后,该embedding被用于输入到恒等初始化的FiLM层。紧接着,FiLM层被添加到预训练EfficientNet以调节图片编码。正常情况下,把FiLM直接嵌入到预训练网络会扰乱中间激活函数,从而抵消掉预训练权重的效果。为了克服该问题,初始化FiLM层为恒等形式,从而保护预训练权重。
TokenLearner
为了进一步压缩tokens的数据,从而加速推理,RT-1使用了TokenLearner。TokenLearner是一个元素级别的注意力模块,可以学习大量tokens到更少量tokens之间的映射。最终,把每张图片81维的视觉tokens变为8维的tokens,6张图片concat到一起,共48维tokens输入到Transformer的Decorder架构。
Action tokenization
为了tokenize actions,RT-1中每个动作维度通过均匀采样的方式被离散化为256个桶。这种离散化技术应该是Sequential DQN中的建模方式。
Loss
损失函数为标准的交叉熵损失函数和因果掩码。
Inference speed
为了能够使机器人的执行速度类似于人,希望机器人执行任务至少$3Hz$的控制频率。因此,利用了如下技术加速推理:
- 通过利用TokenLearner减少预训练EfficientNet生成tokens的数量。
- 计算tokens之后存储下来,减少重复计算。
数据
在机器人领域,任务的定义不一致的。在RT-1中,根据动词对任务进行划分。
引用方法
请参考:
li,wanye. "RT-1:用于真实世界大规模控制的机器人Transformer". wyli'Blog (Jan 2024). https://www.robotech.ink/index.php/archives/95.html
或BibTex方式引用:
@online{eaiStar-95,
title={RT-1:用于真实世界大规模控制的机器人Transformer},
author={li,wanye},
year={2024},
month={Jan},
url="https://www.robotech.ink/index.php/archives/95.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接