深度强化学习的首要偏见
首要偏见是指智能体对早期的交互数据过拟合,而对新的交互数据无法学习到新知识。这种现象也存在于人类的认知过程中,例如:人类在学习弹吉他时,一开始基于简单的曲子学习,但是由于过于熟悉之前的经验,进而形成无意识的习惯,从而导致无法根据新经验学习。文献$[1]$对该现象进行了研究,主要的创新点有:
- 为深度强化学习中存在首要偏见提供了证明,即智能体过拟合早期的数据而伤害未来的决策。
- 揭示了这一现象合理的原因,以及表明了深度强化学习算法如何放大这种效应。
- 提出了通过周期性遗忘智能体的一部分知识而减轻首要偏见。
- 实验证明了实施周期性重置可得到性能提升。
文献$[1]$作者们还对深度强化学习中存在的首要偏见给出了定义。
深度强化学习中首要偏见的定义: 对早期经验过拟合而伤害接下来学习过程的趋势。
首要偏见产生的原因
利用初始经验提高样本效率,对智能体的训练很重要。同时,过于依赖早期经验会使智能体产生首要偏见,从而影响后面的学习。DQN中的Replay Buffer就是典型的在样本效率和首要偏见之间的权衡。
为了理解首要偏见对强化学习的影响,作者们提出了一个问题:对早期单批次数据的过拟合会完全破坏智能体的学习过程吗?在文献$[2]$DMC环境,基于文献$[3]$SAC算法训练了两个智能体,一个是在环境中每步的策略和价值更新只进行一次,即标准智能体;另一个是基于初次收集的100个数据点,对智能体进行$10^5$次更新。如图1所示,智能体累积奖励的变化曲线图。
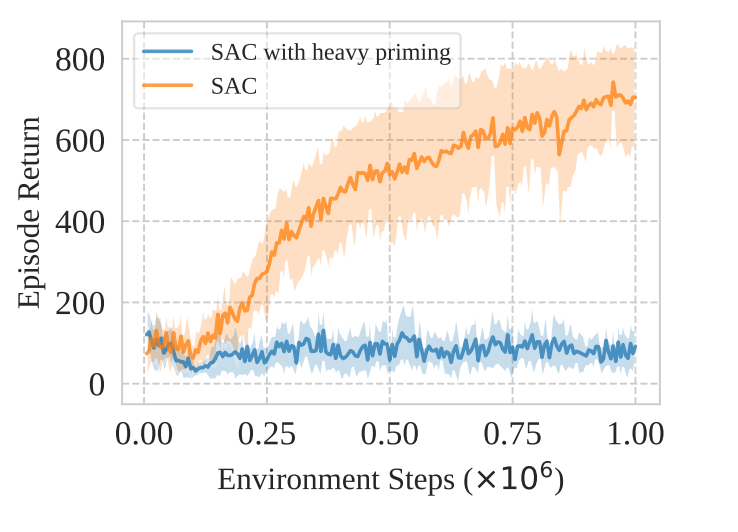
根据图1,可知,首要偏见会无情的破坏智能体接下来的学习过程。在后续的实验中,作者们发现即使更新数据中包含少量之前的数据也会对智能体产生影响。这些发现,表明,首要偏见有复合效应: 过拟合的智能体收集的数据质量本身就不高,从而导致学习不高效,并且进一步破坏后续的学习能力。
Agent利用首要经验学习是可行的
一旦智能体被首要偏见严重的影响,它可能很难得到满意的性能。那么,就会有一个问题:过拟合智能体收集的数据会导致学习不稳定吗?为了回答这个问题,作者们训练两个智能体,第一个智能体是基于SAC算法在每个步中进行9次更新;第二个智能体是基于上一个智能体收集的数据作为经验回放的初始数据训练一个新的智能体。如图2所示,两个智能体累积奖励的变化曲线图。
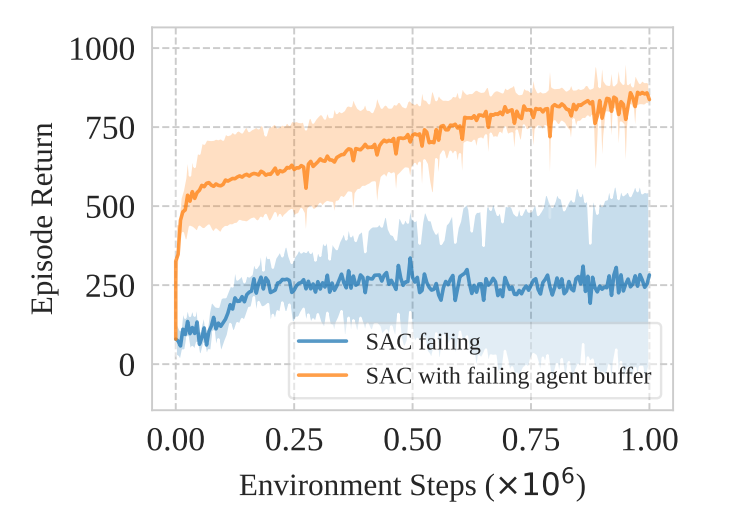
根据图2,可知,首要偏见不是造成智能体收集不到合适的数据,而是无法从这些数据中进一步学习。
解决方法
简单来说,就是:对智能体的神经网络,周期性的初始化最后若干层参数,同时维护Replay Buffer。
参考文献
$[1]$ Nikishin E, Schwarzer M, D’Oro P, et al. The primacy bias in deep reinforcement learning$[C]$//International conference on machine learning. PMLR, 2022: 16828-16847.
$[2]$ Tunyasuvunakool S, Muldal A, Doron Y, et al. dm_control: Software and tasks for continuous control$[J]$. Software Impacts, 2020, 6: 100022.
$[3]$ Haarnoja T, Zhou A, Hartikainen K, et al. Soft actor-critic algorithms and applications[J]. arXiv preprint arXiv:1812.05905, 2018.
引用方法
请参考:
li,wanye. "深度强化学习的首要偏见". wyli'Blog (Feb 2024). https://www.robotech.ink/index.php/archives/164.html
或BibTex方式引用:
@online{eaiStar-164,
title={深度强化学习的首要偏见},
author={li,wanye},
year={2024},
month={Feb},
url="https://www.robotech.ink/index.php/archives/164.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接