VIMA:多模态提示的通用机器人操纵
机器人任务的表述有三种形式,分别是模仿one-shot演示、跟随语言指令、以及实现视觉目标。然而,这三种方式处理的任务不同,且模型也不同。基于提示的学习在自然语言处理领域展现了通用能力,单个模型可以处理各种各样的任务。VIMA是一个机器人领域的通用智能体,基于多模态提示学习的transformer架构。VIMA这篇论文的主要贡献有:
- 多模态提示范式:把机器人操纵任务转化为序列建模问题。
- 大规模benchmark:系统性评估智能体的扩展性和泛化性。
- 多模态提示机器人智能体:拥有处理多任务和零样本泛化的能力。
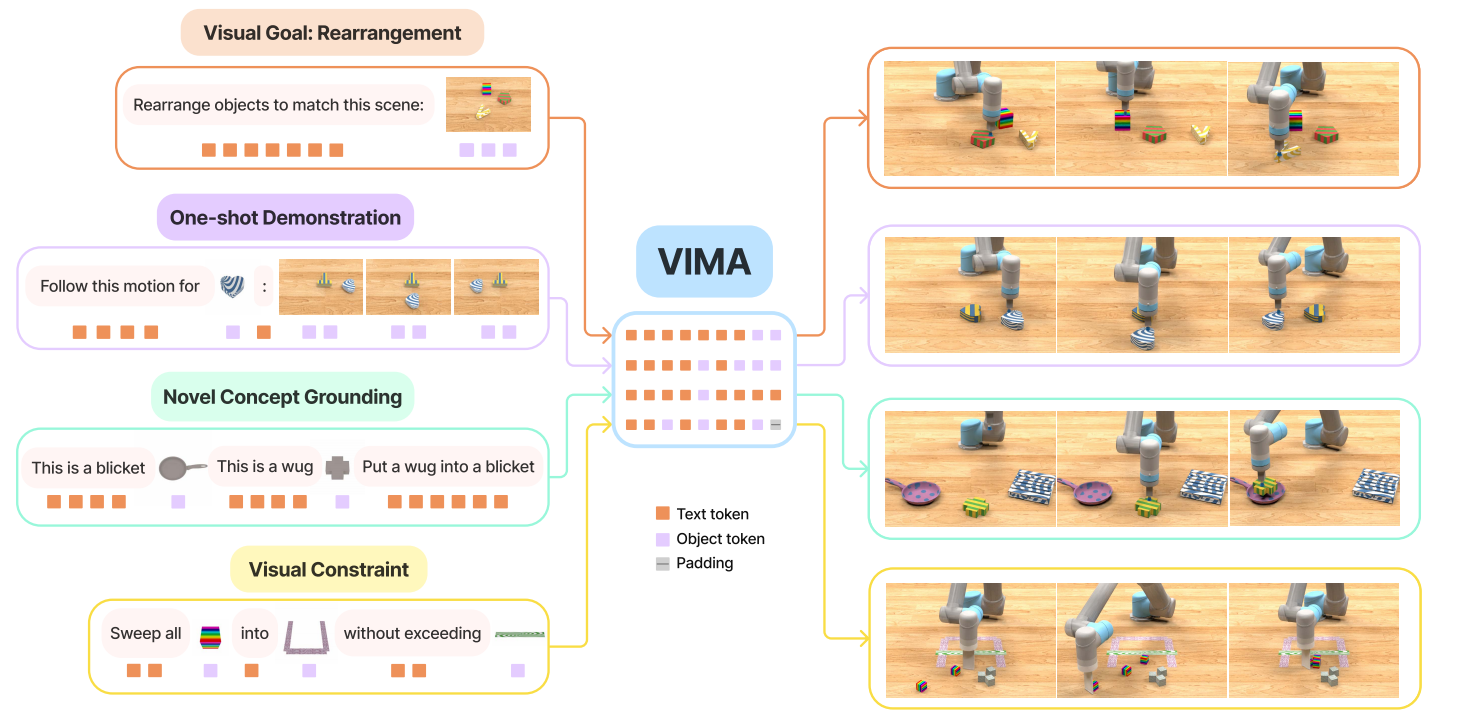
图1 任务说明的多模态提示
多模态提示
作者们认为各种各样的任务说明范式可以被多模态提示初始化。确切的说,多模态提示$\mathcal{P}$被定义为任意交叉的文本与图片的有序序列$\mathcal{P}:=[x_1,x_2,\ldots,x_l]$,可见图1所示。其中,元素$x_i\in\{text,image\}$。
主要考虑的任务有6中,分别是
- 简单的物品操纵
- 实现视觉目标
- 新颖概念理解
- one-shot视频模仿
- 满足视觉约束
- 视觉推理
VIMA-Bench
由于只有特定任务的benchmarks,所以提出了VIMA-Bench。该Benchmark的形成是由收集对象与文本对形成提示对,从而扩展Ravens机器人仿真器得到。同时,基于特权信息获得仿真环境中专家演示数据。在仿真环境中,智能体的观测空间由前向RGB图片和自顶向下视角的图片构成;动作空间由关节位置构成;奖励函数为0-1奖励,只有完成任务才有奖励。
如图2所示,作者们设计了4级评估协议,系统探索了智能体的泛化能力。
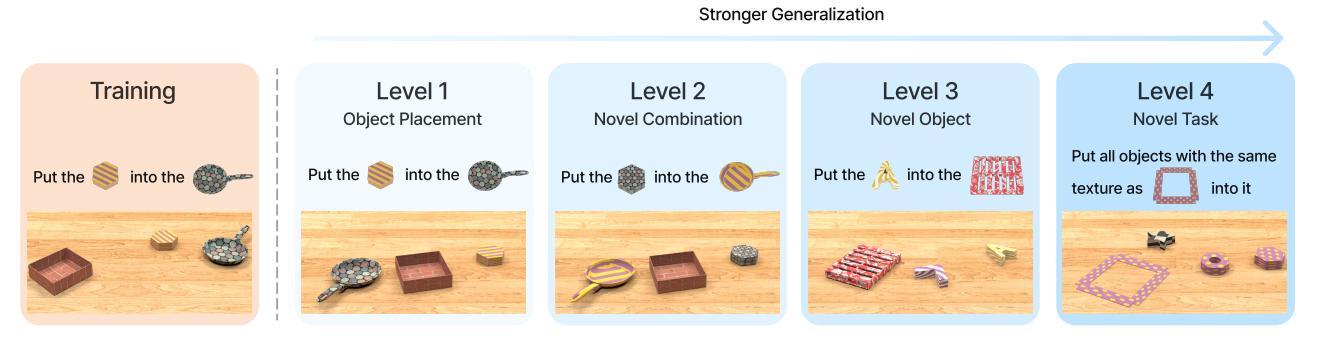
图2 评估协议
VIMA
为了学习一个高效的多任务机器人策略,设计了一个多任务编码-解码架构和以对象为中心的智能体,可见图3所示。
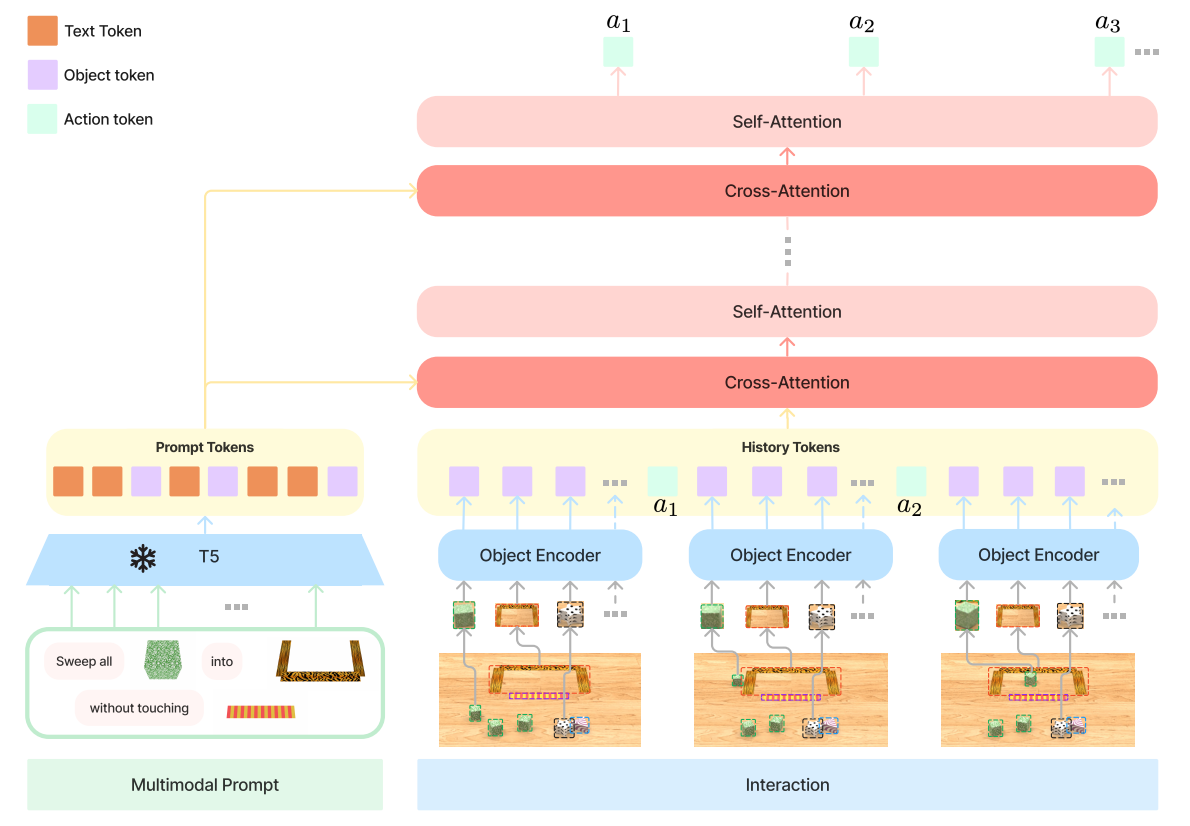
图3 VIMA架构
确切的说,策略$\pi(a_t\vert\mathcal{P},\mathcal{H})$由多模态提示和历史$\mathcal{H}:=[o_1,a_1,o_2,a_2,\ldots,o_t]$为输入。对于多模态提示,利用预训练模型T5进行编码。对于解码,利用多模态提示编码与交互数据和观测$o_t$之间的交叉注意力生成动作序列。VIMA通过从有界box坐标和裁剪RGB patches计算tokens的方式得到对象为中心的表示。
Tokenization:三种类型的数据需要tokenization,分别为文本、单个对象的图片、桌面场景图片。对于文本,利用预训练T5的tokenizer和词embedding获得词tokens。对于全景图片,首先利用微调后的Masked R-CNN抽取单个对象,然后对每个对象的有界box和裁剪图片进行编码,分别使用了有界box编码器和ViT。其中,有界box编码器为MLP。对于只包含单个对象的图片,利用ViT直接得到编码。最后,tokens以特定准则,通过预训练T5编码器编码提示。同时,为了使模型能够容纳新的模态,在非文本tokens与T5之间增加了MLP。
表1 Tokenization的超参数与模型架构
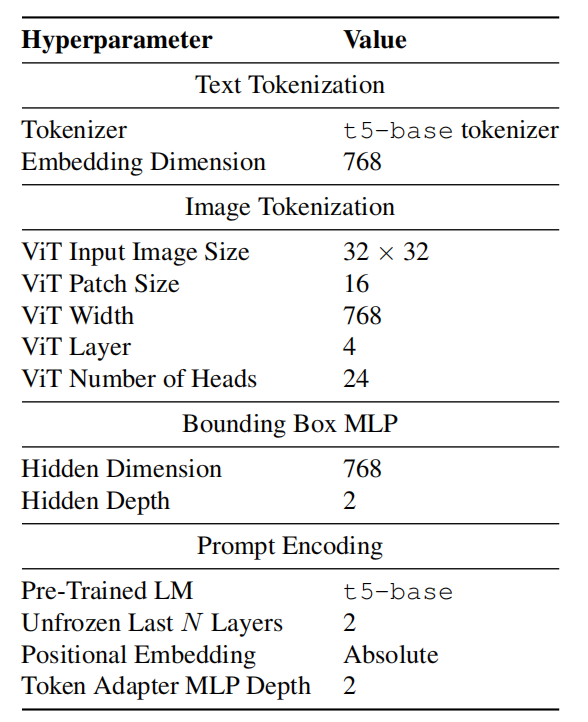
对于全景图片,需要把有界box的编码与ViT编码concat到一起作为最终token。同时,作者们还进行了如下优化:
- 在把裁剪图片输入到模型时,会对非方形patch进行padding。
- 在有界box坐标编码时,会对各个坐标数据进行标准化到[0,1]范围内。
- 为了防止灾难性遗忘,基于layer-wise learning rate decay只微调T5最后两层网络。
对于观测图像的编码,先把图像中对象利用全景图像的方式编码,然后与末端执行器的one-hot状态编码concat到一起,最后转换为观测编码。对于动作的编码,作者们基于Decision-Transformer与Online decision transformer的方式,利用两层MLP作为拟合器进行编码。
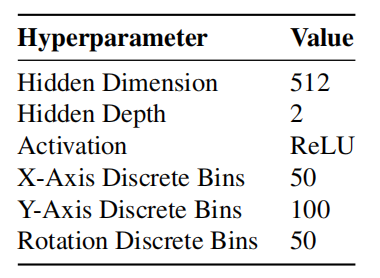
由于动作空间由两个SE(2)位姿构成,因此每个位姿利用6个独立的Head对动作token进行解码。这个位姿被独立的建模,这是因为早期的研究表明独立的建模与可替代的技术性能一样好,例如:Vinyal等人和OpenAI中研究人员中利用自回归解码。如表2所示,动作解码器的模型超参数。
表2 动作解码器的模型超参数
引用方法
请参考:
li,wanye. "VIMA:多模态提示的通用机器人操纵". wyli'Blog (Feb 2024). https://www.robotech.ink/index.php/archives/284.html
或BibTex方式引用:
@online{eaiStar-284,
title={VIMA:多模态提示的通用机器人操纵},
author={li,wanye},
year={2024},
month={Feb},
url="https://www.robotech.ink/index.php/archives/284.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接