Decision Transformer
Decision Transformer效果主要在游戏中评估,并未在机器人领域得到验证。与RL算法相比,该算法的建模思路或思想完全不同。Decision Transformer把RL的序列决策问题变为了条件轨迹序列建模。这样的建模方式会规避掉RL中非线性函数、Bootstrapping、以及off-policy的致命三元素和未来奖励折扣。同时,基于Tansformer的方式能够直接通过自注意力进行信用分配。
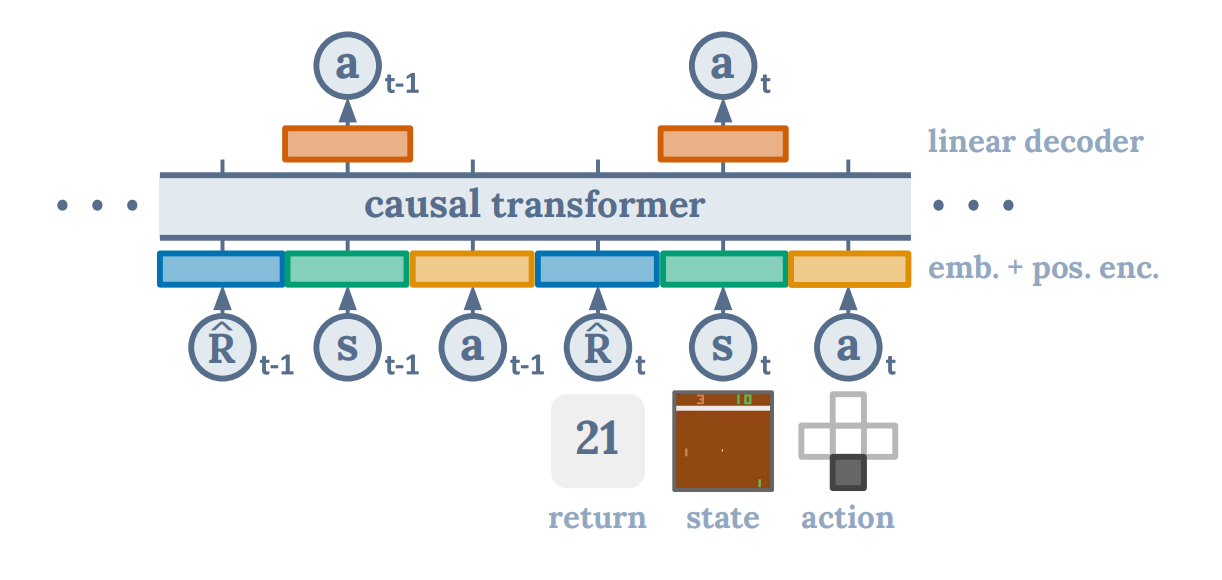
图1 Decision Transformer网络架构
如图1所示,Decision Transformer以奖励、过去的状态、以及过去的动作为输入,生成下一个动作,这是一种自回归的建模方式。其中,奖励为未来希望获得的回报,为动作的生成作提示。

图2 Decision Transformer算法
如图2所示,DT算法的具体操作流程可以总结为
- 输入过去K时间步的状态、动作、未来期望回报,
- 学习时间步的embedding
- 利用线性层或卷积层学习三种输入的Embedding
- 三种输入与时间步的embedding求和
- 求和后的三种输入stacking,再输入GPT,生成下一个时间步的动作。
其中,若t时刻的奖励为$r_{{t}'}$,那么未来期望回报可表示为$\hat{R}_t=\sum_{{t}'=t}^Tr_{{t}'}$。
这是一种离线的学习方式,并没有与环境交互学习。但是,经过实验发现,该学习范式性能超过其它离线学习范式。
引用方法
请参考:
li,wanye. "Decision Transformer". wyli'Blog (Jan 2024). https://www.robotech.ink/index.php/archives/23.html
或BibTex方式引用:
@online{eaiStar-23,
title={Decision Transformer},
author={li,wanye},
year={2024},
month={Jan},
url="https://www.robotech.ink/index.php/archives/23.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接