LLaVA:视觉指令微调
利用机器生成的跟随指令数据调优大语言模型,提升了模型的零样本泛化能力。与之对应的,LLaVA是第一个尝试利用多模态语言-视觉指令跟随数据调优的多模态大模型。其中,多模态指令跟随数据主要由GPT-4产生的。实验结果表明,LLaVA拥有多模态聊天能力和零样本泛化能力。在Science QA数据集上微调,实现了92.53%的准确率。视觉指令调优与视觉提示调优不同,前者主要目的是提升模型的指令跟随能力,后者主要目的是提高模型自适应的参数效率,LLaVA属于前者。
GPT协助下的视觉指令数据生成
多模态社区有大量的开放图片-文本对数据可获得,从CC到LAION。然而,多模态指令跟随数据可用的很少。对于图片$\mathbf{X}_{\mathbf{v}}$和相关描述$\mathbf{X}_{\mathbf{c}}$,为了指导助手描述图片内容很容易创建一系列问题$\mathbf{X}_{\mathbf{q}}$。一种简单的扩展图片-文本对的方式是:Human: $\mathbf{X}_{\mathbf{q}}\mathbf{X}_{\mathbf{v}}$
- Captions:从各个方面描述视觉场景。
- Bounding boxes:定位场景中物体,每个box编码所包含对象的概念和它的空间位置。
同时,基于GPT4产生了三种指令跟随数据,分别是:
- 对话:主要问有确定性答案的问题,例如:图片中对象类型、对象数量、对象动作、对象位置、以及两个对象之间的相对位置。
- 详细描述:为了生成丰富的和充分理解的图片描述,创建了一系列的特定问题,用于提示GPT4。
- 复杂推理:创建了深度推理问题。
在指令跟随数据生成的过程中,利用了COCO数据集中图片。如表1所示,指令跟随数据样例。

表1 指令跟随数据样例
视觉指令调优
架构
为了有效地利用预训练LLM和视觉模型,选择Vicuna作为LLM$f_{\phi}(\cdot)$,这是因为在开源模型中该模型具有最好的指令跟随能力。如图1所示,网络架构。
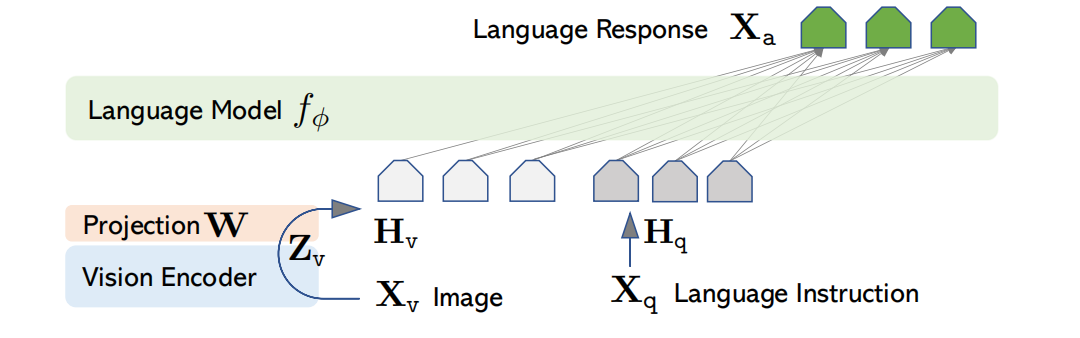
图1 LLaVA架构
对于输入图片$\mathbf{X}_{\mathbf{v}}$,利用预训练模型CLIP的ViT-L/14作为编码器,产生特征$\mathbf{Z}_{\mathbf{v}}=g(\mathbf{x}_{\mathbf{v}})$。在实验中,把ViT-L/14的最后一层Transformer的前后特征作为图片的表示。同时,通过简单的线性层把图片特征映射到词embedding空间,即$\mathbf{H}_{\mathbf{v}}=\mathbf{W}\cdot\mathbf{Z}_{\mathbf{v}}$。最终视觉编码与文本编码维度相同,输入LLM模型。
训练
对于图片$\mathbf{X}_{\mathbf{v}}$,产生多轮对话数据$(\mathbf{X}_{q}^1,\mathbf{X}_{a}^1,\cdots,\mathbf{X}_{q}^T,\mathbf{X}_{a}^T,)$。在第$t$轮,指令$\mathbf{X}_{instruct}^t$为
$$ \begin{aligned} \mathbf{X}^t_{instruct}=\begin{cases}Randomly\quad choose [\mathbf{X}_q^1,\mathbf{X}_v]or[\mathbf{X}_v,\mathbf{X}_q^1] & the\quad first\quad turn\quad t=1\\ \mathbf{X}_q^t & the\quad remaining\quad turns\quad t\gt1 \end{cases} \end{aligned}\tag{1} $$
如表2所示,多模态指令跟随序列的格式

表2 模型训练的输入数据
表1中描述的是数据生成方法,表2描述的训练数据构建方式。
基于自回归的训练方式,在预测tokens上执行LLM的指令调优
$$ \begin{aligned} p(\mathbf{X}_a\vert\mathbf{X}_v,\mathbf{X}_{instruct})=\prod_{i=1}^Lp_{\theta}(x_i\vert\mathbf{X}_v,\mathbf{X}_{instruct,\lt i},\mathbf{X}_{a,\lt i}) \end{aligned}\tag{2} $$
式(2)中$\theta$为可训练参数,$\mathbf{X}_{instruct,\lt i}$和$\mathbf{X}_{a,\lt i}$分别为预测token$x_i$之前的所有指令和回答tokens。对于LLaVA模型训练,考虑两阶段的调优步骤:
- 阶段一:特征对齐的预训练。训练阶段保持视觉编码器和LLM权重不变,最大化可训练映射层参数$\theta=\mathbf{W}$的似然。
阶段二:端到端的微调。视觉编码器权重参数保持不变,持续更新映射层预训练权重和LLM的权重。主要考虑两个场景:
- 多模态Chatbot:基于158K图片-语言指令跟随数据微调,包含多轮对话和单轮对话。其中,指令跟随数据基于表1的方式生成,共三种类型数据,每种类型的数据被均匀采样。
- Science QA:第一个大规模多模态科学问题数据集,每个答案都有详细的解释。问题与上下文信息作为指令,推理过程和答案作为回答。
LLaVA-Bench
LLaVA-Bench(COCO)随机选择了COCO中30张图片,对于每个图片,基于提出的视觉指令跟随数据生成方法生成数据。利用这些数据研究模型的对齐行为和能力。
LLaVA-Bench(In-the-Wild)随机选择各种各样的24张图片和60个问题,每个图片有高度详细的和人工的描述,以及一个合适的问题。利用这些数据研究模型在挑战任务上的能力和对新领域的泛化能力。
引用方法
请参考:
li,wanye. "LLaVA:视觉指令微调". wyli'Blog (Feb 2024). https://www.robotech.ink/index.php/archives/292.html
或BibTex方式引用:
@online{eaiStar-292,
title={LLaVA:视觉指令微调},
author={li,wanye},
year={2024},
month={Feb},
url="https://www.robotech.ink/index.php/archives/292.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接