基于GPT-4的指令微调
大语言模型在上下文学习和思维链推理展现了较强的泛化能力。为了使大语言模型跟随自然语言指令和完成真实世界任务,研究人员探索了指令微调方法。这种方法要么利用人类标注的提示和反馈微调模型,要么利用开源benchmarks和datasets有监督微调。在这些方法中,自主指令精调是一个对齐LLM与人类意图简单和有效的方法。为了提升大语言模型的指令微调性能,基于GPT-4的微调利用GPT-4作为teacher生成数据,用于自主指令微调。

数据集
数据收集:利用Alpaca数据集中52k唯一指令输入GPT-4,输出指令中描述任务的答案。如算法1所示,作者们遵循同样的提示策略以生成微调数据。值得一提的是:Aplaca数据集中的输出是由于GPT3.5产生的。最终,利用GPT-4生成四种类型的数据集,分别是:
- 英文指令跟随数据
- 中文指令跟随数据:利用ChatGPT把52K指令数据翻译成中文,然后再要求GPT-4用中文回答指令。
- 比较数据:利用GPT-4评估回答的分数。此外,也利用GPT-3.5和OPT-IML评估回答的分数,比较三个模型的评估。该数据最终用于训练奖励模型。
- 非自然指令的回答:GPT-4的回答在68k instruction-input-output三元组数据集上解码。它的子集被用于量化GPT-4与大规模指令微调模型之间的差距。
指令微调语言模型
Self-Instruct Tuning
作者们利用有监督微调训练两个版本LLaMA 7B模型,分别是:
- 英语指令跟随数据训练LLaMA 7B模型。
- 中文指令跟随数据训练LLaMA 7B模型。
以上两个模型用于研究GPT-4生成的数据质量和跨语言泛化能力,模型的训练遵循与Aplaca相同的训练流程。
奖励模型
RLHF主要目的是对齐LLM模型与人类意图,主要的元件是奖励模型。该奖励模型被建模为回归任务,用于预测给定提示和响应的标量值。然而,这种方式需要大量的比较数据。为了评估数据质量,基于OPT 1.3B训练了奖励模型用于评估不同的响应。比较数据的每个实例都包含一个提示$x$和$K$个响应,GPT-4对每个分数分配了一个分数$s\in[1,10]$,因此有$C_{2}^{K}$个比较对。匹配对表示为$(y_l,y_h)$且$s_l\lt s_h$,目标函数为$min\quad log(\sigma(r_{\theta}(x,y_h)-r_{\theta}(x,y_l)))$。如图1所示,OPT-IML、GPT3.5和GPT4在比较数据中评分的分布。
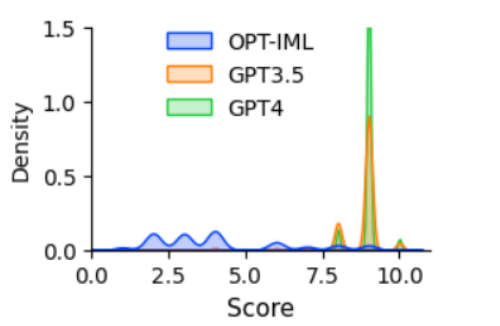
图1 模型对比较数据评分的分布
引用方法
请参考:
li,wanye. "基于GPT-4的指令微调". wyli'Blog (Feb 2024). https://www.robotech.ink/index.php/archives/311.html
或BibTex方式引用:
@online{eaiStar-300,
title={基于GPT-4的指令微调},
author={li,wanye},
year={2024},
month={Feb},
url="https://www.robotech.ink/index.php/archives/311.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接