MobileLLM:优化小于1B参数的大语言模型
大语言模型正在渗透人类生活各种方面,不仅影响人类的交流与工作,而且重塑每日娱乐生活方面。然而,LLMs运行在云环境中,需要大量的计算资源,这不仅导致大语言模型无法部署在移动设备上,而且对能量消耗与碳排放带来了巨大挑战。根据该观察,MobileLLM是一个小于1B参数量的模型,可部署在移动设备上,且与同规模的模型相比性能得到了提升,可见图1所示。作者们做出了如下贡献:
- 与Sclaing law不同,对于小LLMs深度比宽度重要。一个深且窄的模型擅于捕获抽象的概念。
- 利用embedding共享方法和分组查询注意力最大化权重利用。
- 提出了immediate block-wise权重共享,从而避免了相邻block之间的权重流动,导致了最小延时预算。
- 提出了一个新家族的模型MobileLLM,拥有SOTA表现。
- 在下游任务,例如:Chat与API calling,MobileLLM模型家族显著优于同等尺寸的模型。
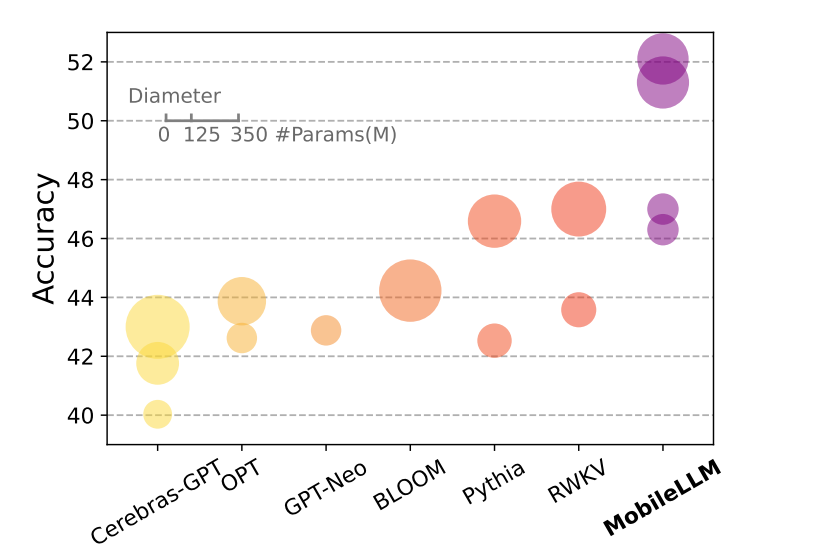
图1 小于1B参数的LLMs在零样本常识任务上的平均分。每个球的面积与同家族模型大小成正比。
训练设置
实验在32块A100的GPUs上执行,每块GPU的batch大小为32,在0.25T数量tokens上执行120k探索性实验。
构建较强的Baseline
FFN的选择
作者们首先研究了全连接神经网络中常见激活函数的表现,发现SwiGLU激活函数能够提升小模型的性能。
模型架构的深度与宽度
在该领域的信念是Transformer模型的表现主要由参数量、训练数据集大小、以及训练迭代次数决定。然而,作者们发现,对于小模型这种假设可能不存在。确切的说,对于有限容量的小模型,深度比广度更重要。如图2所示,不同模型架构在任务上的表现。
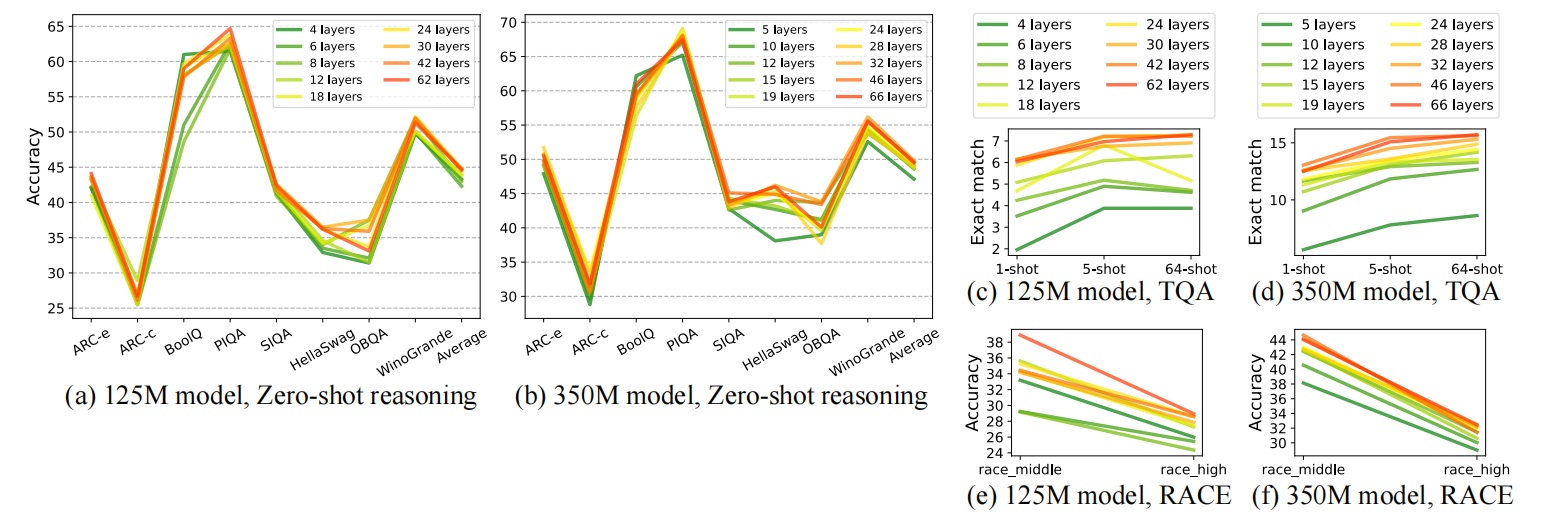
图2 不同模型在零样本常识推理任务、问题回答、以及阅读理解任务上的表现
Embedding共享
对于小于1B参数量的模型,embedding层在参数中占很大的比例。与之相对,对于大语言模型中,embedding层的参数占很小的比例。这也是OPT模型提出embedding共享之后,被抛弃的原因。
在小于1B参数量的语言模型中,作者们发现输入-输出embedding层共享降低参数量的同时,模型的性能也会下降。若把这部分降低参数量用于增加模型架构的深度,那么模型的平均准确率会得到提升。因此,embedding共享对于最大化权重利用是一个很有价值的技术。
Heads与KV Heads的数量
对于Transformer模型,作者们还研究了最优head大小。在每个head的更多语义与多头组合的更多非线性之间妥协对选择head大小属于很重要的考量。作者们,发现,利用分组查询注意力GQA且增加embedding维度大小会提升模型性能。如图4所示,查询head数量为16,kv-heads的数量由16减少到4时性能较好。
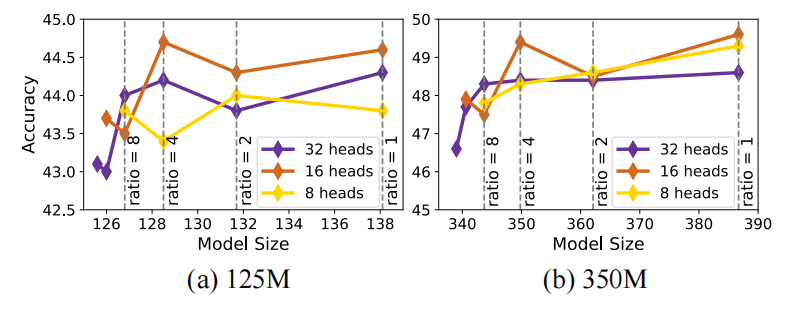
图4 heads与kv-heads数量的消融研究
Layer Sharing
由于模型的深度比宽度更重要,因此作者们研究了层共享。如图5所示,不同的共享策略。
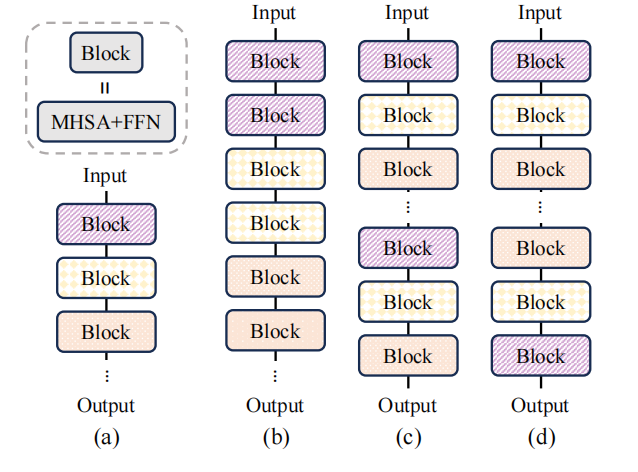
图5:(a)Baseline模型无层共享;(b)即时块共享;(c)重复所有block共享;(4)反转共享
经过研究,作者们发现重复block会提升模型的性能。同时,考虑硬件内存层级,即时块共享能够在缓存中共享权重,避免了SRAM与DRAM之间权重转移。因此,作者们选择了即时块共享,对应的模型被称为MobileLLM-LS。
相关思考
MobileLLM属于组合式创新,没有架构的改进。主要考虑了模型深度与广度之间的权衡、层共享、embedding共享、FFN激活函数、以及Head数量之间的最优选择。
引用方法
请参考:
li,wanye. "MobileLLM:优化小于1B参数的大语言模型". wyli'Blog (Apr 2024). https://www.robotech.ink/index.php/archives/430.html
或BibTex方式引用:
@online{eaiStar-430,
title={MobileLLM:优化小于1B参数的大语言模型},
author={li,wanye},
year={2024},
month={Apr},
url="https://www.robotech.ink/index.php/archives/430.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接