Vicuna:一个开源的chabot拥有ChatGPT90%的能力
Vicuna是一个开源的13B参数量的chatbot。确切的说,该模型是通过在13B的LLaMA模型上利用来自ShareGPT.com的70K对话数据微调得到的,其工作流可见图1所示。
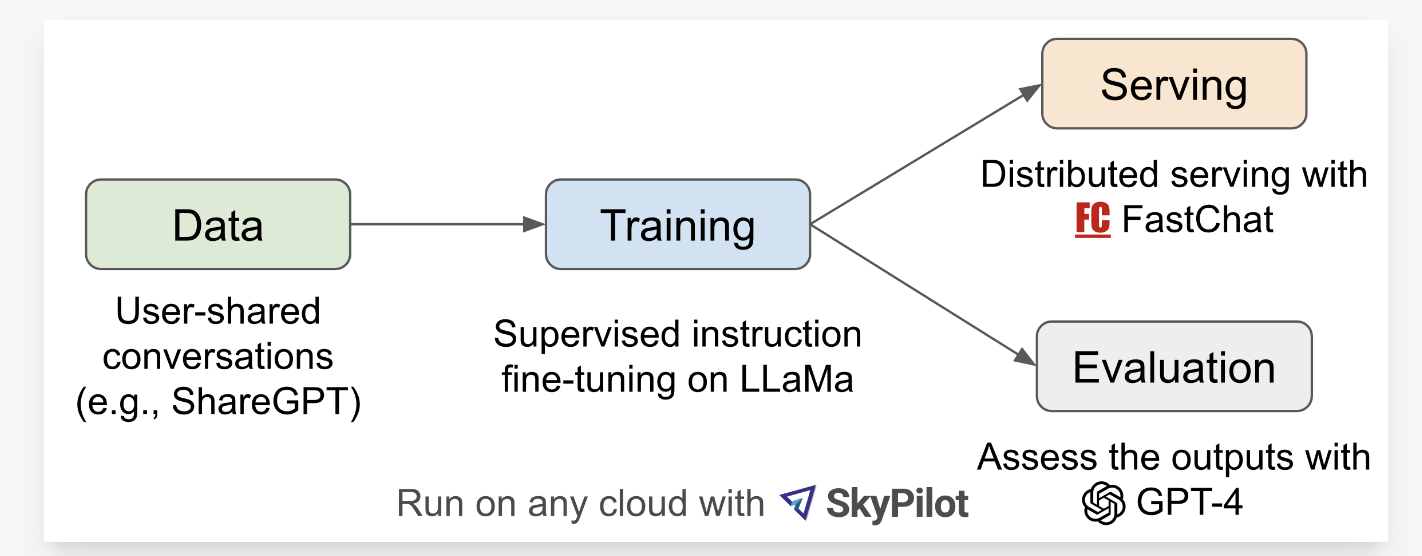
图1 工作流概览
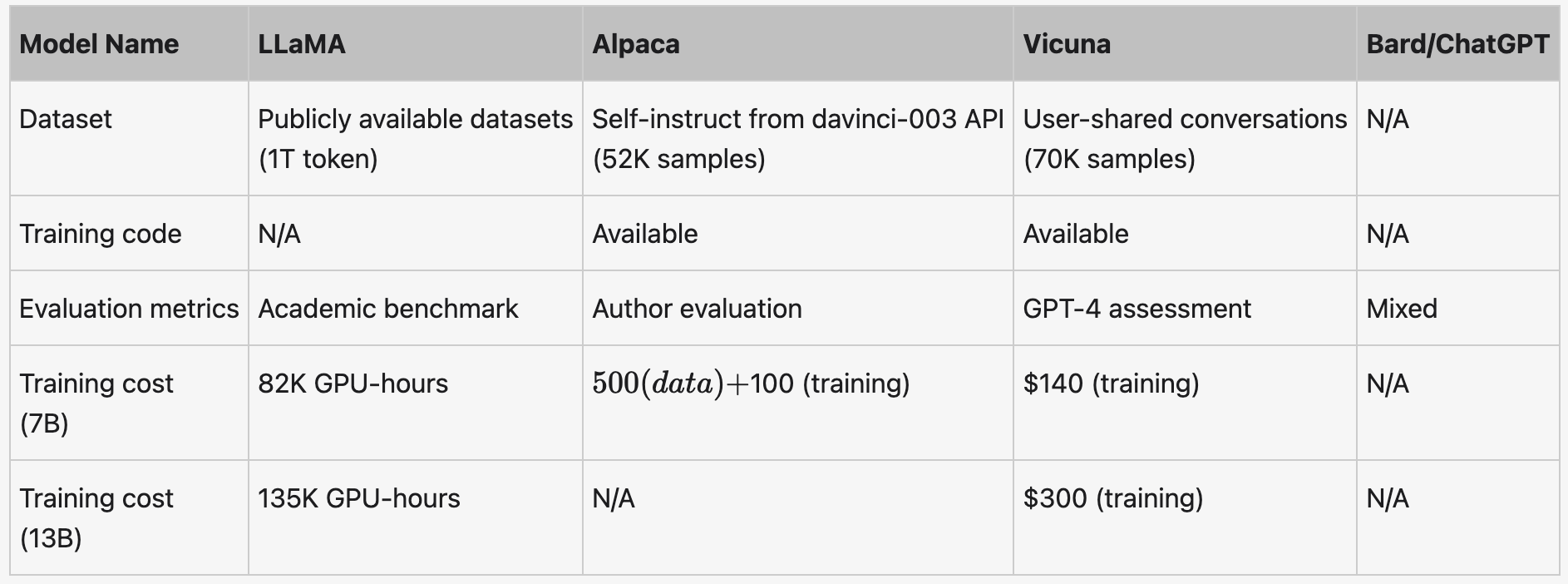
如表1所示,不同模型之间的详细比较。
表1 不同模型之间的比较
模型训练
为了确保数据质量,作者们把HTML转换为MarkDown,且过滤掉不合适或低质量的样本。同时,把冗长的对话划分为更小的片段,从而能够适合模型的最大化上下文长度。
在Alpaca基础之上,对模型训练进行了如下改进:
- 多轮对话:调整了训练损失从而考虑多轮对话,只计算chatbot输出的微调损失。
- 内存优化:为了使Vicuna理解长文本,把最大上下文输入从512扩展到2048。为了降低扩展上下文长度带来的内存增加,使用了梯度checkpointing与FlashAttention。
- 基于Spot实降低成本。
模型服务
构建了一个可服务多个模型的分布式wokers服务系统。该系统支持灵活的即插即用的GPU wokers。利用SkyPilot中默认容错控制器与管理spot的特征,服务系统利用来自多个云服务的性价比高的spot实例进行服务,拥有优越性能。
模型评估
评估AI chatbots属于一个挑战性任务,需要检测语言理解、推理、与上下文意识的能力。然而,当前的benchmarks已经不足够进行模型评估。因此,作者们利用GPT-4自动评估chatbot表现。评估步骤如下:
- 首先,设计了8种问题,例如:Fermi问题、角色扮演场景、以及代码或数据任务。通过提示工程,GPT-4能够生成对于baseline模型来说属于多样、挑战性问题。每个种类选择10个问题,从LLaMA、Alpaca、ChatGPT、Bard、以及Vicuna中收集回答。
- 接下来,利用GPT-4评价这些回答在有助性、相关性、精确性、以及详细程度上的质量。然而,作者们发现GPT-4不擅于判断代码或数据任务上的质量。
确切的说,对于每个问题,输入GPT-4的评估数据由每个模型的输出相结合形成单个提示构成,然后提示GPT-4评估模型输出的质量。
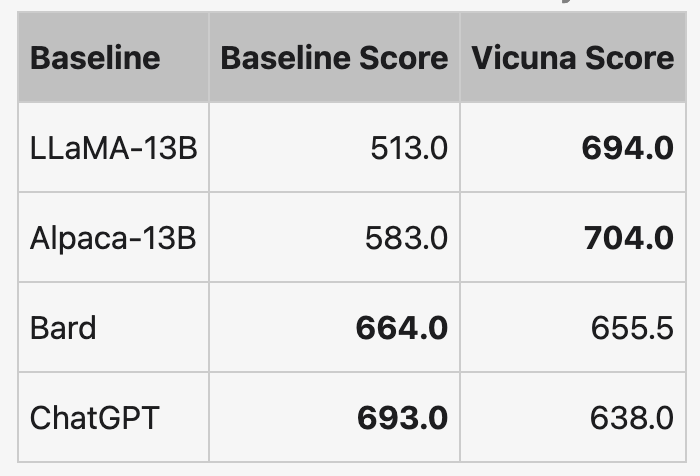
如表2所示,Vicuna的性能达到了ChatGPT的92%。
表2 不同模型由GPT-4评估得到总分的比较
基于GPT-4的评估框架虽然证明了chatbots的潜力,但是这种方式的强劲性与成熟度仍然不高。
引用方法
请参考:
li,wanye. "Vicuna:一个开源的chabot拥有ChatGPT90%的能力". wyli'Blog (Apr 2024). https://www.robotech.ink/index.php/archives/431.html
或BibTex方式引用:
@online{eaiStar-431,
title={Vicuna:一个开源的chabot拥有ChatGPT90%的能力},
author={li,wanye},
year={2024},
month={Apr},
url="https://www.robotech.ink/index.php/archives/431.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接