FlashAttention-2:利用有效并行化与分片机制实现高效注意力
FlashAttention利用非对称GPU显存层级的特性不仅提高了内存效率,也提高了训练速度。然而,随着上下文长度的增加,它没有优化的GEMM运算一样快,且只达到了理论最大FLOPs/s的25-40%。这种不高效主要是由GPU中不同线程块与线程束之间次优的work分片导致的低显存占有率或不必要的共享内存读写所引起的。为了处理这些问题,FlashAttention-2设计了更好的woker分片。确切的说,主要优化为:
- 调整算法,减少非矩阵相乘FLOPs的数量。
- 并行化注意力计算,从而提高显存占有率。
- 在一个线程块内,线程束之间分发work,从而利用共享内存减少通信。
最终,与FlashAttention相比,FlashAttention-2的效率提高了两倍,可达到理论最大FLOPs/s的50%-73%,性能与GEMM运算相接近。
:loudspeaker: 由于FlashAttention2在FlashAttention基础之上,只是工程上优化,所以笔者对于技术细节没有过多关注。
算法
现代GPU拥有专门的计算单元,从而导致矩阵相乘速度更快,例如:A100 GPU对FP16或BF16矩阵相乘的最大化理论吞吐量为312 TFLOPs/s,而非矩阵相乘FP32只有19.5TFLOPs/s的吞吐量。因此,减少非矩阵相乘的FLOP数量,会显著提高运算效率。
前向传递

反向传递

并行化
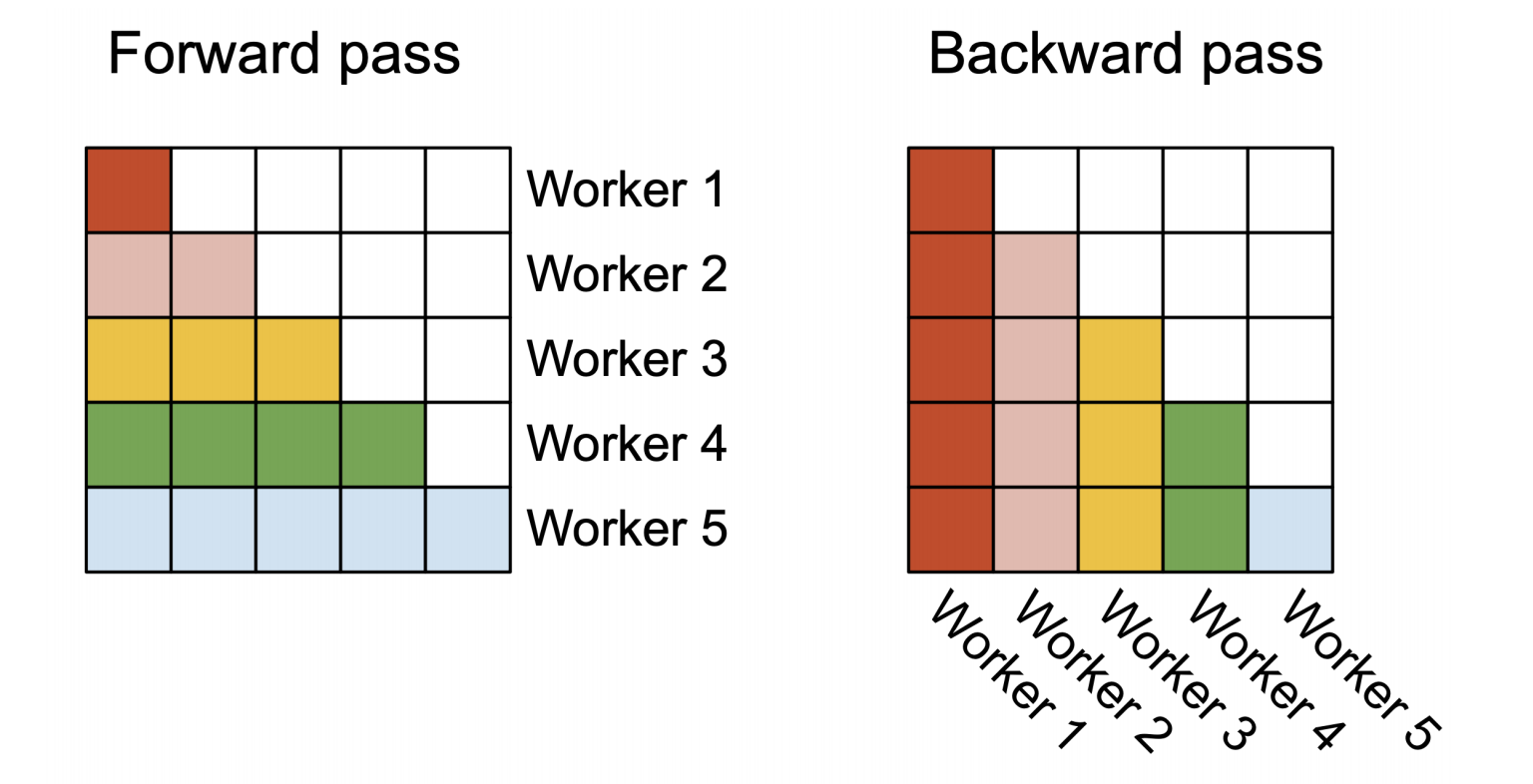
图2 并行化原理图
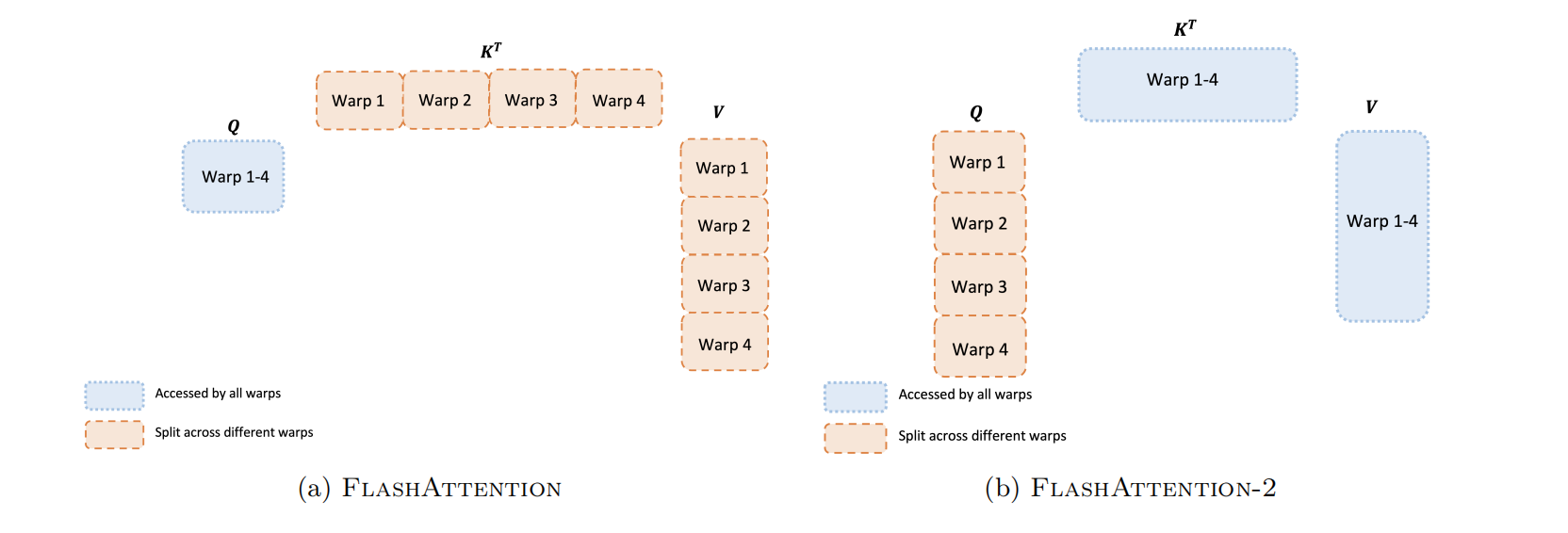
图3 前向传递中不同线程束的工作分片原理图
相关思考
FlashAttention-2的研究是作者们通过GPU的profilling,发现,GPU拥有低的占有率或不必要显存读写共享。这两种现象产生的原因是GPU中线程块与线程束之间的次优work分区导致的。因此,作者们在FlashAttention基础之上进行了相关优化。
引用方法
请参考:
li,wanye. "FlashAttention-2:利用有效并行化与分片机制实现高效注意力". wyli'Blog (Apr 2024). https://www.robotech.ink/index.php/archives/443.html
或BibTex方式引用:
@online{eaiStar-443,
title={FlashAttention-2:利用有效并行化与分片机制实现高效注意力},
author={li,wanye},
year={2024},
month={Apr},
url="https://www.robotech.ink/index.php/archives/443.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接