概述多模态大语言模型的演进
MLLM发展遵循着LLM的相似路径,Flamingo是第一个大规模探索上下文学习的视觉语言模型。之后,visual instruction-tuning很快成为了最重要的训练范式。如图1所示,MLLM至少包含三个元件:一个LLM backbone为用户提供接口、一个视觉编码器、以及一个或多个视觉语言自适应模块。
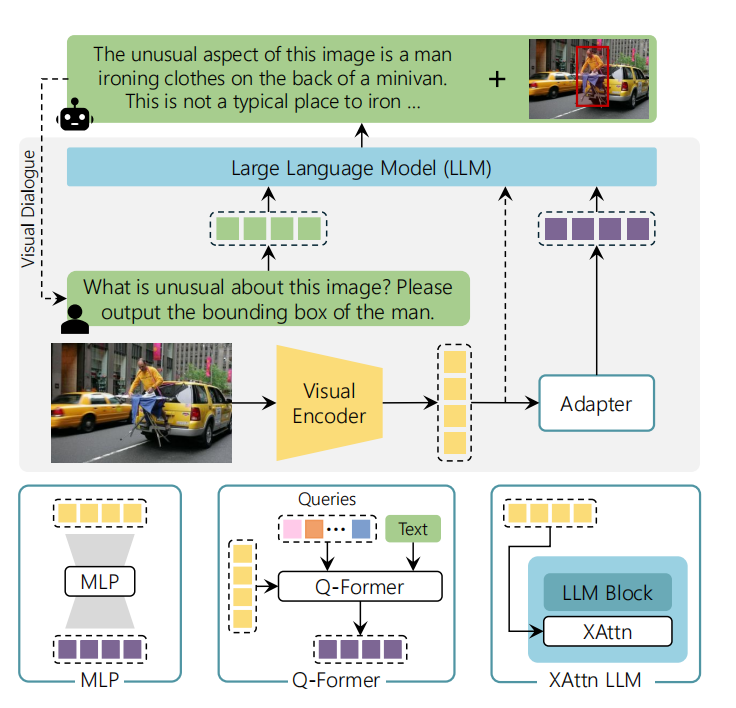
图1 多模态大语言模型的通用架构
对于LLM,常利用LLaMA家族及其衍生模型作为backbone,因为它的权重可自由获取,且只是基于开源数据训练。如图2所示,MLLM模型的相关总结,主要包含LLM backbone、视觉编码、以及适配器,还有是否进行视觉指令微调,以及主要任务和能力的简短清单。
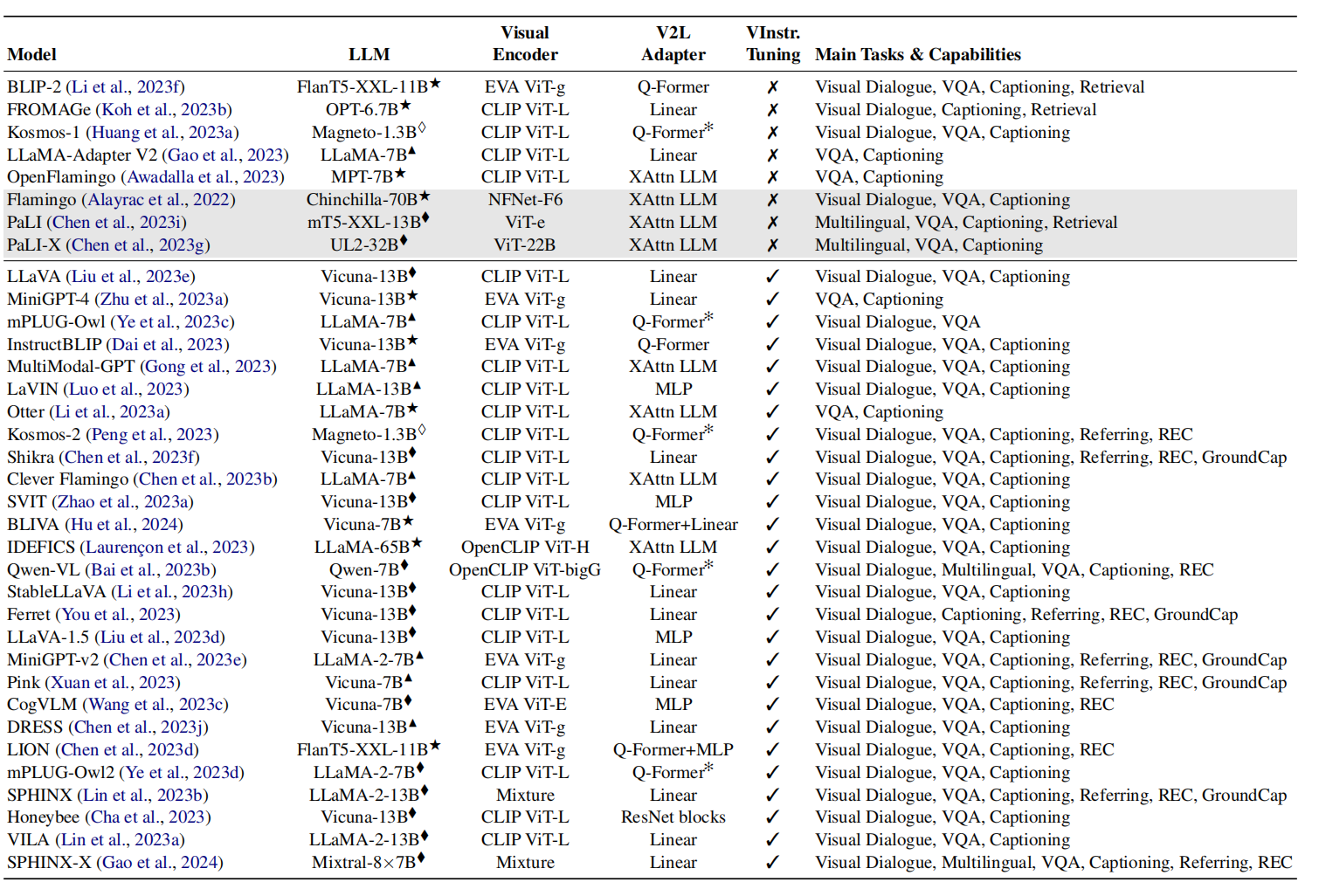
表1 在视觉-语言任务上的多模态大语言模型总结
♢: LLM training from scratch; ♦: LLM fine-tuning; ▲: LLM fine-tuning with PEFT techniques; ⋆: frozen LLM.The ✻ marker indicates variants to the reported vision-to-language adapter, while gray color indicates models not publicly available.
视觉编码器
利用CLIP目标函数的预训练ViT模型常常被作为视觉编码器,从而利用对齐之后的CLIP embedding。受欢迎的选择有:
CLIP与Open-CLIP是基于互联网上收集的图片数据训练,采用对比的方式对齐文本与图片对。EVA-CLIP是一系列模型,该系列模型提供了实际且高效训练CLIP模型的解决方案。
之后,发现,视觉模型的参数与语言模型的参数量不平衡,所以不断扩展视觉模型。再接下来,由于在模型训练阶段需要forzen视觉编码器参数,导致视觉与语言模态的不对齐。为了缓和该问题,就提出了两阶段的训练方法。
视觉语言适配器
不同模态的同时存在,需要一个模块描述模态之间的对应关系,这个模块被称为适配器。从基本网络架构到高级形态的适配器,均被用在MLLM模型。
线性与MLP映射
最简单直接的方式是学习一个视觉输入到文本embedding的线性映射,例如:LLaMA-Adapter、FORMAGe。与之不同的,LLaVA-1.5利用一个两层的MLP提升多模态能力。尽管MLLM模型在早期采用线性映射,但是最近的模型也有使用线性映射,且呈现高的性能。
Q-Former
Q-Former是一个基于Transformer的模型,被提出于BLIP-2。它的适配模块由共享自注意力层的两个Transformer块构成,从而有助于视觉与文本表示之间的对齐。在Q-Former基础之上,各种改进版被提出。mPLUG-Owl模型简化了Q-Former,且提出了一个视觉抽象器元件,该元件把视觉信息变成的可学习tokens,从而产生语义上丰富的视觉表示。同时,Qwen-VL利用单层交叉注意力模块压缩视觉信息。
辅助的交叉注意力层
辅助的交叉注意力层在Flamingo中提出,主要方式为把稠密的交叉注意力模块整合在LLM的预训练层之间。这种新增加的层常常与零初始化的tanh门控机制结合,从而确保条件模型与原始模型一致。辅助的交叉注意力层的使用,需要从零训练模型,与别的方式相比增加了可训练参数。为了减少计算复杂度,这种方式常与基于感知的元件相结合,从而在输入LLM之间减少了视觉token的数量。
多模态训练
MLLM模型训练分为单阶段和多阶段,这两种方式均利用交叉熵作为目标函数预测下一个token,以自回归的方式建模。对于单阶段训练,LLaMA-Adapter只是利用视觉文本对数据更新适配器模型的参数;Kosmos-1模型forzen视觉模块,从零开始训练LLM模块;Flamingo模型forzen LLM模块,训练适配器与视觉编码器模块;Otter模型把所有模型从零开始训练,且利用文本数据尽可能保护模型的对话能力。对于两阶段训练,LLaVA模型第一阶段只训练适配器模块以对齐图片特征和文本特征,第二阶段引入了visual instruction-following,更新多模态适配器和LLM模块;MiniGPT-4模型第一阶段只是训练了负责多模态对齐的线性层,第二阶段利用第一阶段模型产生的数据训练;Instruct-BLIP模型两个阶段都forzen视觉编码器和LLM模块,只有Q-Former模块被训练;mPLUG-Owl在初始阶段更新了视觉编码模块,第二阶段利用文本数据和多模态数据联合增强对齐;在两个阶段,Shokra模型forzen视觉backbone,更新了其它所有参数。
参考文献
引用方法
请参考:
li,wanye. "概述多模态大语言模型的演进". wyli'Blog (Feb 2024). https://www.robotech.ink/index.php/archives/277.html
或BibTex方式引用:
@online{eaiStar-277,
title={概述多模态大语言模型的演进},
author={li,wanye},
year={2024},
month={Feb},
url="https://www.robotech.ink/index.php/archives/277.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接