SAM:分割任何事物
SAM是一个图像分割的基础模型,该模型在大规模数据集上预训练,也属于可提示的模型。为了构建SAM模型,作者们定义了一个可提示的分割任务,创建了一个支持灵活提示和可实时输出分割掩码的模型架构。同时,为了训练模型,构建了一个数据引擎,可在利用模型辅助数据收集和基于新收集的数据模型之间迭代。如图1所示,构建SAM的三大元件:任务、模型、数据。
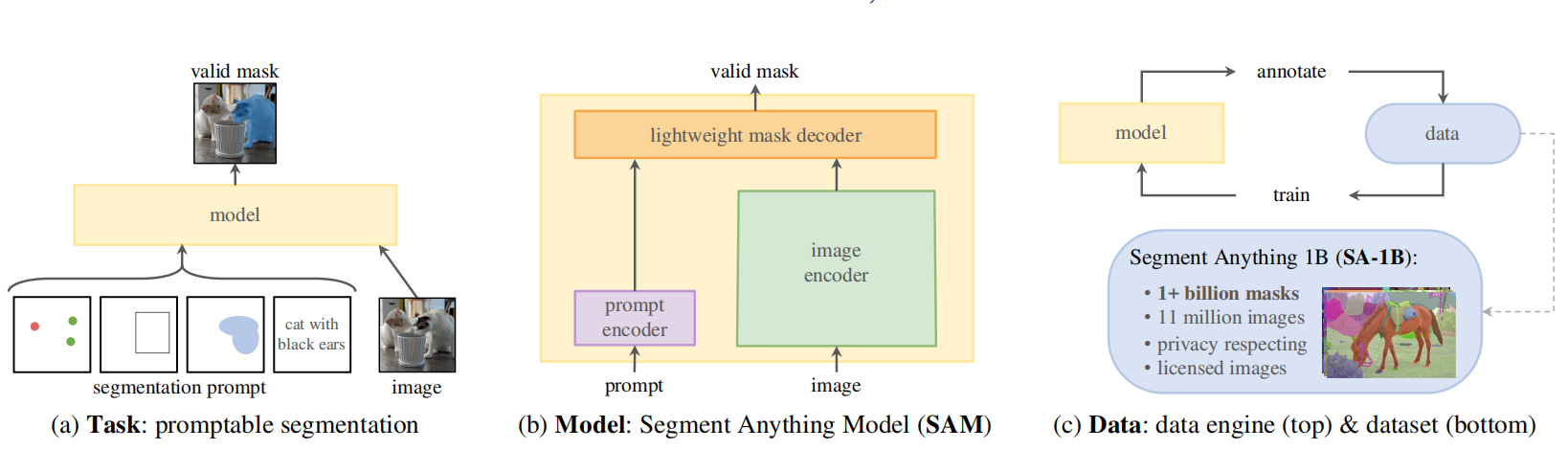
图1 构建SAM的三个元件
任务
如图1.a所示,作者们提出了一个可提示的分割任务,其目标是基于任何分割提示输出一个有效的分割掩码。一个提示只是确定了一个图片应分割什么,例如:提示可包括空间或文本信息确定一个对象。其中,有效的输出掩码意味着即使提示是模糊的或指向了多个可能对象,也要输出输出合理的掩码,只要包含对象中的一个。该提示任务既作为预训练目标函数,也通过提示工程解决下游任务。
模型
如图2所示,SAM有三个元件,分别是:图片编码器、灵活的提示编码器、以及快速掩码解码器。
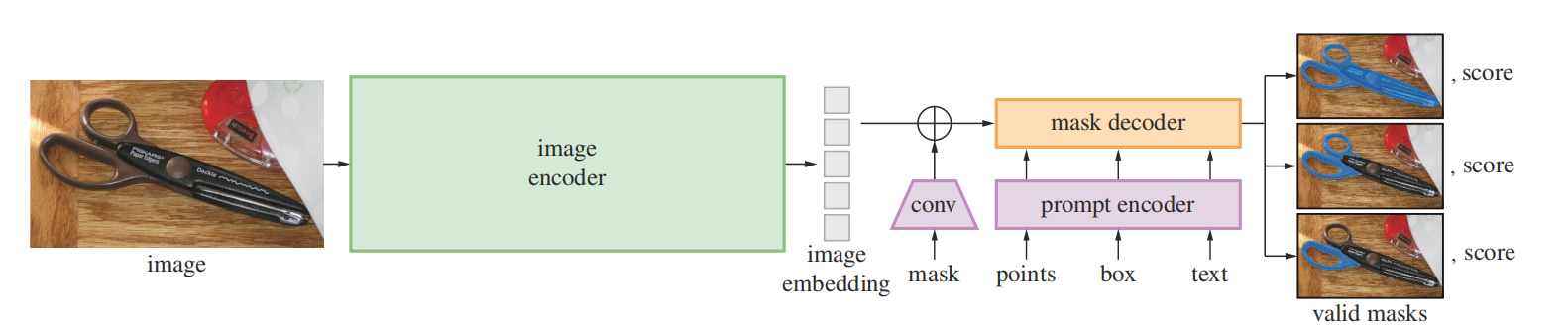
图2 SAM架构概览
图片编码器:利用MAE的预训练视觉Transformer编码器ViT,最小限度的适应处理高分辨率数据。其中,最小限度的适应处理高分辨率数据的思想来自于ViTDet。图片编码器每次可处理一张图片,且可在提示模型之前运行。
提示编码器:作者们考虑两种提示,分别是稀疏和稠密。其中,稀疏提示有点、boxes、文本,稠密提示有掩码。对于点与boxes,利用每个提示类型学习到的embeddings和位置编码求和表示,而文本利用CLIP中文本编码器的输出作为表示。对于掩码提示,基于卷积形成的embedding与图片embedding中元素级别求和作为表示。
掩码解码器:掩码解码器高效的映射图像编码、提示编码、以及token到一个掩码。基于DETR和MaskFormer的研究,掩码解码器由Transformer的解码器改进版和动态掩码预测头构成。其中,利用提示自注意力、图片与提示之间双向交叉注意力改进Transformer的解码器。自注意力和交叉注意力模型的输出经过上采样所有图片embedding,再利用MLP映射输出token到一个动态的线性分类器预测掩码概率。
对于一个给定的模糊提示,模型预测多个掩码,可见图3所示。作者们发现,3个掩码输出足够处理最常见的情况。在训练阶段,作者们反向传播了掩码的最小损失。为了排序掩码,对于每个掩码还预测了一个置信分数。

图3 每列显示SAM根据单个歧义点提示(绿色圆圈)生成的3个有效掩码
数据引擎
如图1.c所示,数据引擎是指训练的高效模型拥有辅助标注数据,标注的新数据再用于训练新模型,由此不断交替。确切的说,数据引擎分为三个阶段,分别是:
- 协助:SAM协助标注人员标注掩码,类似于经典交互性分割设置。
- 半自动:SAM根据提示自动产生对象子集的掩码,标注人员聚焦标注剩下的对象,从而有助于增加掩码的多样性。
- 全自动:基于前景点网格提示SAM,产生平均每张图片生成100个高质量掩码。
最终的数据集在全自动阶段形成,来自11M授权和隐私保护的图像数据,共计1B的掩码。
引用方法
请参考:
li,wanye. "SAM:分割任何事物". wyli'Blog (Mar 2024). https://www.robotech.ink/index.php/archives/356.html
或BibTex方式引用:
@online{eaiStar-356,
title={SAM:分割任何事物},
author={li,wanye},
year={2024},
month={Mar},
url="https://www.robotech.ink/index.php/archives/356.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接