面对未知:学习一个具有线上系统识别的通用策略
简单来说,UP-OSI作者们提出了一个学习框架(可见图1),用于解决机器人领域"Reality Gap"的问题。该学习框架的核心思想是:通过仿真探索“虚拟世界”,提前计算机器人能够遇到的许多可能情况。为了该方法可行,作者们提出了两个假设,分别是
- 假设存在一种方法可提前计算每种动力学模型的最优策略。
假设存在一种快速方法可知道哪种动力学模型适合观测序列。
在这两个假设下,真实世界线上执行时,只需要通过根据机器人最近的历史状态选择合适动力学模型,然后选择对应控制策略以实现最优运动。
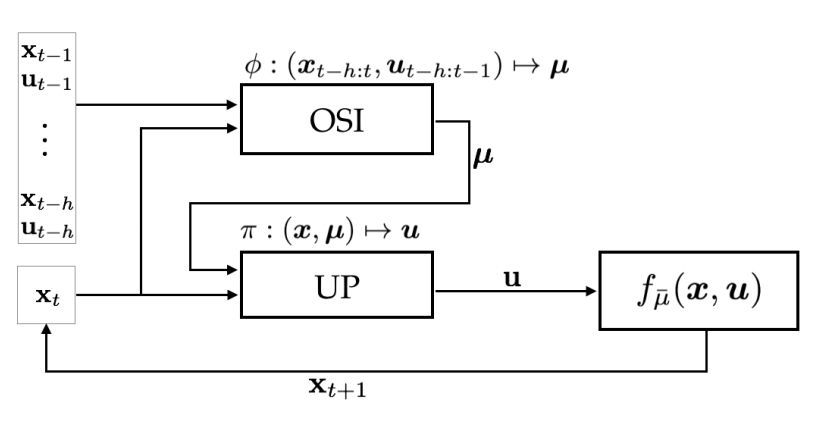
根据图1,可知,该学习框架可有两大模块,分别是通用控制策略(Universal Control Policy, 简称UP)和线上系统识别(Online System Identification,简称OSI)。
在现实中学习通用策略是不可能,因为环境系统千变万化。但是,学习一个感兴趣领域的通用策略是可能的。为了学习出感兴趣领域的通用策略,先采样出$K$个系统参数,然后以强化学习方式根据每个系统参数均学习出最优策略,可见图2。

图2中$\mu$为系统参数,$x$为机器人的本体状态。
线上系统识别以监督学习的方式拟合系统参数,其函数为$\phi(\mathbf{x}_{t-h:t},\mathbf{u}_{t-h:t-1})\to\mu$,目标函数为
$$ \begin{equation} {\theta}^*=\underset{\theta}{argmin}\sum_{(H_i,\mu_i)\subseteq B}\Vert\phi_{\theta}(H_i)-\mu_i\Vert^2\tag{1} \end{equation} $$
在模型训练时,发现,若只是以真实系统参数$\bar{\mu}$输入UP网络得到的历史数据训练OSI模型,发现UP-OSI性能没有只有UP网络的策略性能好。这是因为OSI只观测到了"good cases"。为了防止这种情况发生,在OSI网络训练时,也以OSI网络预测出的系统参数输入UP网络以得到观测历史。两份历史联合训练OSI模型,效果较好。如图3所示,OSI模型算法

引用方法
请参考:
li,wanye. "面对未知:学习一个具有线上系统识别的通用策略". wyli'Blog (Jan 2024). https://www.robotech.ink/index.php/archives/75.html
或BibTex方式引用:
@online{eaiStar-75,
title={面对未知:学习一个具有线上系统识别的通用策略},
author={li,wanye},
year={2024},
month={Jan},
url="https://www.robotech.ink/index.php/archives/75.html"
}
CC版权: 本篇博文采用《CC 协议》,转载必须注明作者和本文链接